边缘人工智能推理框架Tengine
Tengine是OPEN AI LAB拥有自主知识产权的边缘人工智能推理框架,致力于解决AIoT产业所面临的碎片化问题,加速AI的部署和普及,惠及千行百业。Tengine基于纯C打造,将轻量化无依赖做到极致,适合在各种软硬件资源受限的嵌入式环境下使用部署轻量的AI算法模型用于语音、视觉等应用。
目前,Tengine是市面上唯一可在各种嵌入式操作系统上运行的AI推理框架。不但可以在FreeRTOS\RTT\Lite-OS等极简的实时操作系统或裸机Bare-matel上运行,还可以在MCU、RISC-V等低功耗、资源极为有限的IoT芯片主控上运行。
1. Tengine的核心能力
Tengine是一个嵌入式的AI推理框架,帮助算法开发者解决在AI快速产业化落地中遇到的各个瓶颈难题。有两个特点,一是物理位置层面,其所关注的重点是嵌入式设备,也就是海量的AIoT应用设备,而非服务器集群;二是业务模式层面,重点在于推理,并非训练。
1.1 跨OS/算法框架适配
对于开发者而言,训练只是第一步,训练后获得推理模型的有效部署才是解决场景问题的关键,快速的硬件平台迁移及高效部署已经成为AIoT产业快速发展的掣肘。
Tengine目前广泛支持市面上主流的模型格式,如TensorFlow、Caffe和MXNet,并且通过ONNX模型实现了对PyTorch和PaddlePaddle的支持,让开发者能更自由地选择训练框架,降低了面对不同硬件和场景而迁移平台的成本。
在操作系统层面,由于AIoT场景的差异化及非收敛性,Android、Ubuntu、RTOS等各有其适配的产品形态,Tengine同样在OS层面进行了兼容适配,以简化AI开发者的开发流程。
1.2 跨OS/算法框架适配 跨芯片平台适配
为了助力产业提速增效,Tengine为开发者提供跨硬件设备的统一开发平台,在不同硬件设备上的API都尽可能保持一致,帮助开发者以一致的方式实现对不同芯片的有效调用适配。
开发者仅仅需要通过Tengine API,就能充分调用包括MCU、Arm Cortex-A/M系列处理器、Arm中国周易AIPU,以及海思NNIE、瑞芯微RK3399Pro NPU等等在内的芯片算力。
1.3 异构/加速支持,芯片有效性提升
业务跑通是第一步,跑得快跑得好才是芯片优势的核心体现。Tengine通过异构计算技术,能够帮助开发者同时调用CPU、GPU、DSP、NPU等不同计算单元的运算资源,进一步提升芯片有效性,以完成AI网络计算。
1.4 超轻量无依赖
在AIoT非常多场景中,考虑功耗、成本等要素,往往对于资源的分配极为苛刻,不依赖外部库很多时候会成为工程化场景的一大诉求。通过对框架设计进行一系列的简化和轻量处理,Tengine最小程序体积能达到300KB,在MCU上最小体积为20KB,并且自带视觉、语音的前后处理函数,对额外资源的占用进一步优化,提升芯片的适用范围和潜力。
1.5 全栈部署移植支持
Tengine从诞生至今,已开发出具备量化训练工具、调试工具、模型库、编译器等工具在内的完整工具链,能进一步满足开发者的各类高精度应用需求。
2.1 Tengine推理流程
依照顺序调用Tengine核心API如下:
2.2 init_tengine
初始化Tengine,该函数在程序中只要调用一次即可。
2.3 create_graph
解析输入的timfile模型文件,创建Tengine计算图。
2.4 prerun_graph
预运行,准备计算图推理所需资源。设置大小核,核个数、核亲和性、数据精度都在这里。
struct options
{
int num_thread;//核个数设置,
int cluster;//大小核设置,可选TENGINE_CLUSTER_[ALL,BIG,MEDIUM,LITTLE]
int precision;//精度设置,TENGINE_MODE_[FP32,FP16,HYBRID_INT8,UINT8,INT8]
uint64_t affinity;//核亲和性掩码,绑定具体核,
};
3.1 run_graph
启动Tengine计算图推理。
3.2 postrun_graph
停止运行graph,并释放graph占据的资源。
3.3 destroy_graph
销毁graph。
3.4 TVM与Tengine区别与联系
3.4.1联系
TVM与Tengine都属于端到端的神经网络编译器,包含了从解析模型,图优化到张量的优化和后端代码生成。
3.4.2 区别
1. TVM框架
TVM通过把图到op生成规则这一步进一步抽象化,把生成规则本身分成各个操作原语,在需要的时候加以组合。基于tvm我们可以快速地组合出不同的schedule方案。同时集成了自动优化功能,TVM 为 DL模型的每一层产生针对输入形状和布局优化过的算子,从而带来巨大的性能增益。TVM 提出了自动调度优化器
(Automated Schedule Optimizer),它包含两个主要组件:
1)调度探索器(Schedule Explorer),用来提出潜在的、有前途的优化配置。
2)基于机器学习的开销模型(ML-based Cost Model),用来预测和评估给定配置的表现。
总结成一句话:让AI来编译优化AI系统底层算子。
2. Tengine框架
现在Tengine开源部分的算子分别对于不同的平台分为arm32,arm64,ref,x86。其中arm32与arm64是针对端侧平台的算子优化,以arm汇编和arm neon为主来进行计算部分的优化,可以大大提高计算效率。X86则是针对Convolution和FullyConnected层在x86平台上进行加速。优化部分只针对需要大量计算的算子,对于其余的算子则是通过加载reference算子来实现。不过Tenngine框架算子层级的算子自动优化工具Autokernel也正在开发中,目标是从小处着手,把算子层级的优化做好,做到极致。
4.1 Transformer、强化学习算法的RISC-V向量指令加速验证
4.1.1 验证背景
本次验证主要是基于RISC-V对神经网络算法——Transformer及强化学习(Reinforcement Learning, RL)进行SIMD向量优化,并将其部署在基于平头哥提供的C908处理器的FPGA上进行测试,对算法优化前后的性能进行对比分析。
4.1.2 Transformer、强化学习算法模型模型流程分析
本次验证采用Transformer衍生出来的预训练语言模型(无监督模型)——bert模型以及指基于深度学习Qlearning算法的DQN算法进行验证。采用由OPEN AI LAB主导开发的边缘AI计算框架Tengine在端侧进行环境部署。Tengine提供的模型转化工具Convert Tool可将TensorFlow/PyTorch等主流训练框架的模型转换成Tengine独特的模型格式timfile。 DQN模型中的gemm算子和bert模型中的MatMul算子等weight为二维的算子,在转换
为timfile模型后,都会转换成FC(FullyConnected)算子。转换后的两种模型的具体流程如下图所示:
1. bert模型局部

2. DQN模型
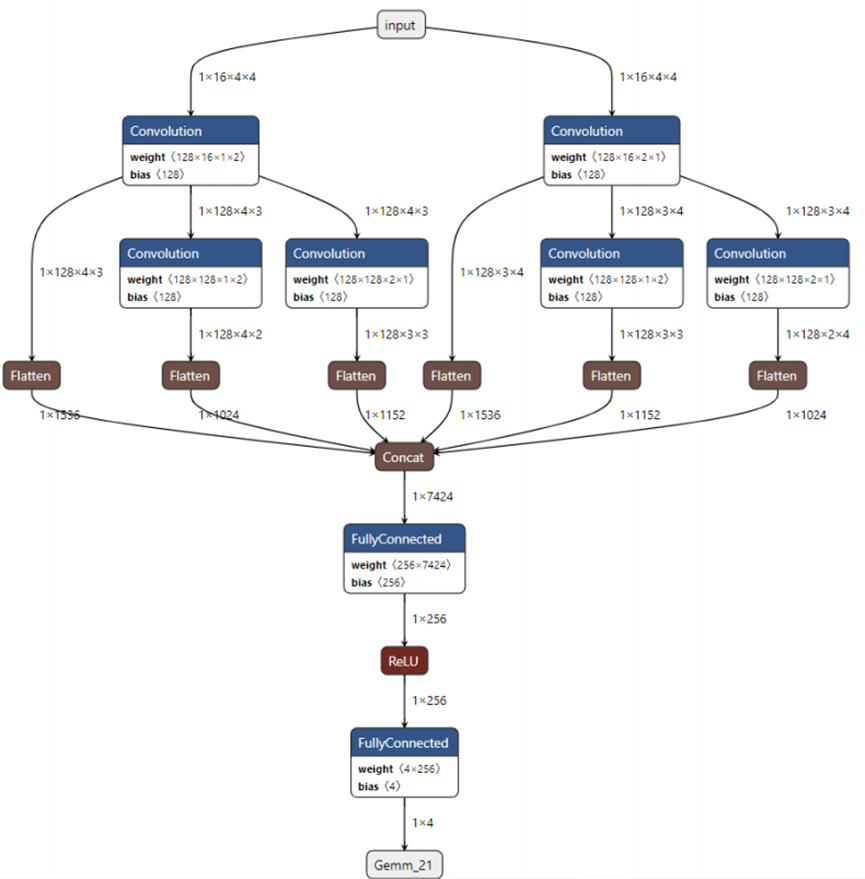
可用Netron工具解析模型文件的详细流程,方便后续的分析及优化。