1.es直接去官网下载windows版然后启动就可以了,双击elasticsearch.bat
2.使用postman对es服务器进行增删改查
3.倒排索引,与之相对的是正向索引,比如两篇文章
文章一:my name is zhangsan
文章二:my name is lisi
正排查询,是根据文章名字查文章,而倒排索引,是把文章内容关键字作为key
my: 文章一 文章二
name: 文章一 文章二
is: 文章一 文章二
zhangsan: 文章一
lisi: 文章二
这样你在按照内容搜索的时候,就会找到他在哪些文章里,然后再把这些文章的内容返回给你。
4.基本操作
新增数据:需要用post请求,url里制定索引,row中发送json格式数据,返回的数据中会携带_id,这个id是es自己生成的,多次发送同样的请求返回的id不同。如果想指定id可以在路径里把id加上,但是多次请求返回的version会是不同的。
查询:
match是会拆分的模糊查询,比如小华,会把小米和华为都查出来,因为是按照小和华单独模糊匹配的,而match_phrase是不会拆分的模糊匹配,再写小华就查不出来了,写小米或者华为可以查出来,或者小、华单独也可以查出来,因为是模糊匹配。
5.我们的搜索中心其实还没用spring boot data elastic search,用的是elasticsearch-rest-high-level-client
6.shards分片的概念,类似于mysql的分表,因为单节点能存储的数据量是有限的,把一个索引的大量文档分布在多个机器上,对于查询请求允许分布式查询。
为了防止某个分片挂了之后丢失数据,所以还要有副本Replicas,这样可以防止数据丢失同时降低主节点的查询压力。
7.多个分片需要有一个master分片来管理索引。每个分片可以有多个副本,在每台机器上,主分片和他的副本不能放在同一个机器上。
8.黄色代表三个主分片都正常,能正常查数据,但是副本没有运行,可能是因为只有一台机器,主分片和副本分片放在一起实际上没意义,因为机器一挂副本也没了,所以是黄色。
如果集群里有两台机器,那么123主分片都放在地一台机器上,副本分片都放在第二台机器上,颜色就变绿了。
但是如果原来仨机器,挂了一个,然后经过故障应对之后剩下的俩,即使仍然满足主从都正常运行的状态颜色也是红的,因为es知道你有一台本应该运行的机器没运行。
9.水平扩容:3主3从,集群里两台机器的时候是每个机器里三个分片,如果压力过大需要加一台机器,es会自动重新分配分片,分配的时候主要依据这么两个原则:第一主从不能同时放在一个机器上,第二 三台机器要平分六个分片,所以第三台机器一启动扩容之后有可能是第一台机器主1副2,第二台主2副3,第三台主3副1
10.需要注意的是,主分片的数量一旦创建完就不能改了,所以创建的时候一定要预估好最大数据量,副本的数量是可以改的。
11.主节点挂了之后再重启,主节点(领导人)就变了。领导人选举,是每个节点都知道自己和其他节点的nodeid,选举时排个序,在自己这里把最前面那个当master,最终选那个在超过一半数量的机器上都当成master并且它自己也选择了自己的那个节点作为master.
master节点的作用:只有master节点能维护元数据,比如节点的状态信息、索引的新增删除、mapping和setting配置等。
12.路由计算:新增一条数据的时候,需要计算他应该放在哪个分片里,计算的规则是hash(id)%分片数量,插入后自动同步到副本分片,所有副本都同步完了才会给客户端返回告诉客户端写入成功。实际在查询的时候,用户可能访问的是任意一个存有主分片或者副本分片的节点,但最终并不一定真的是从这个节点查询的,实际上这个被访问到的节点叫做协调节点,它会根据负载均衡把请求分给一个压力比较小的节点上。副本分片只能读,主分片可读可写。这也解释了为啥主分片的数量一旦确定就不能改了,因为只要主分片数量固定查询就总能路由到他,但是主分片一旦变了数量,没有一致性hash,就会导致原来村的数据查不到了。读和写,先访问到的那个节点是随机的,最终都有可能不是读或写数据的那个节点,这个节点会做路由计算,它是协调节点。
13.对于写入之后什么时候能读,其实是可以设置的,不是必须所有副本同步完才行,默认是“大多数副本同步完成”,这个是es自己有一套计算规则,根据主分片、副本分片数量、系欸但数量计算多少算是大多数,可以设置的是one(代表一个副本同步完就行)和all(代表必须所有副本同步完才行)
14.存储倒排索引的时候,肯定要对文本进行分词,这里有三个概念要清楚:
词条:指的是一个句子被分词之后的那个东西,是索引存储和查询的最小单元,如果是英文就是一个单词,如果是中文就是一个词组,取决于你用的是那种分词器。
词典:词条的集合,一般用B+树或者hashMap来存
倒排表:就是以词条为key,存储一个词条出现在id为多少的文档里的表。
所以查询过程大致是这样:先看你要查的这个词条在不在字典里,如果不在肯定就没有,有的话去查倒排表,找到在哪个文档里面,然后读取就可以了
15.在单个节点上,es的倒排索引一旦落到磁盘就不能修改了,所以新增、修改的时候其实都是生成的新文件,这个新的文件是一个"段"--segment,查询的时候是多个段一起查询然后结果做合并。如果是修改的话会把旧的标记为逻辑删,直接删除某个文档也是标记为逻辑删。既然落盘了不能被修改,那么是怎么做的逻辑删呢?不是像我们mysql一样有个逻辑删字段,置为1,而是有个单独的.del文件,把标记为删除的数据写在里面。
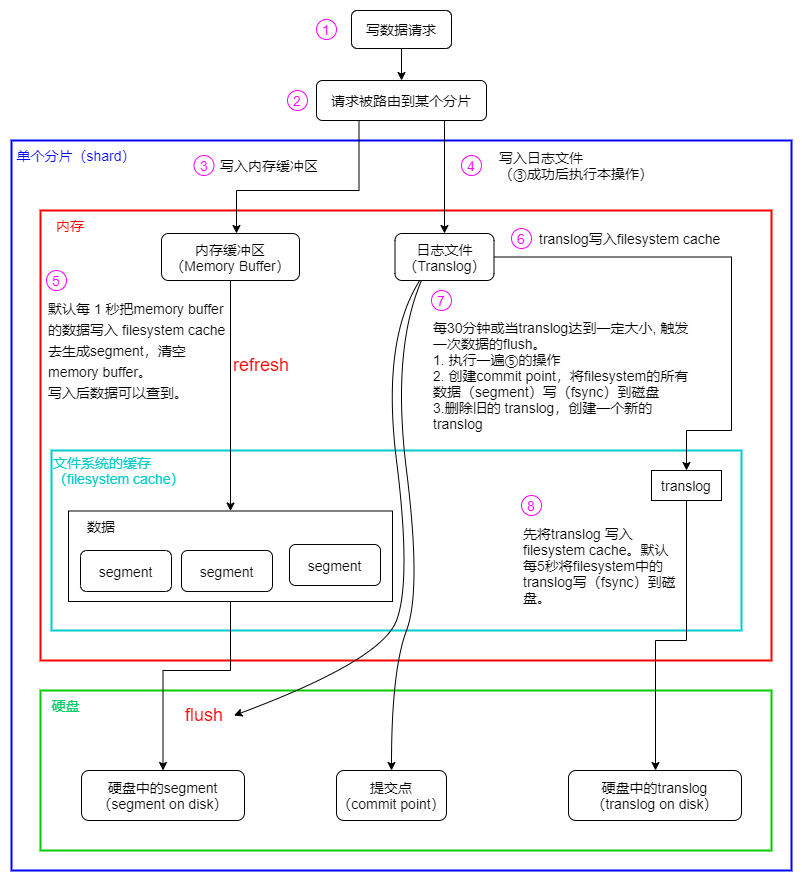
数据写到内存之后,如果得刷到磁盘才能查,这样就比较慢了。所以在内存和磁盘中间还有个OS cache 缓冲区,从内存往OS cache的操作叫refreash,是一秒做一次的,refresh完之后就可以查到了,我们工作中说的强刷就是指在写入或读取的时候带上refresh参数让es强制把数据刷到OS cache。为什么说es是“近实时”搜索,也是因为这个1秒的延迟。从OS cache再往磁盘segment的过程叫flush,这个操作半小时或者内存中的translog达到一定的大小才做一次。
除了上面这些主流程外,还有一个用来保证数据安全的事务日志translog,在数据写入内存成功后,在确认前,会写进内存里的translog,然后translog再写进os cache,在os cache中每隔5秒会把translog写进磁盘里,这样宕机重启时根据这个log来恢复数据,不过有可能会丢5秒的没来得及写的数据,跟redis的aof类似。
为什么要在文件缓冲区os cache中也放一份translog而不是直接把内存里的每隔5秒刷到磁盘上,可能是为了在只是进程挂掉内存清空,而不是服务器宕机时也能做数据恢复。
那为什么不直接放到缓冲区里而是放到内存再往缓冲区同步呢?可能是为了提高响应速度,往内存里写完就可以给客户端回复了,如果写文件系统缓存的话会慢一些。
问题:写入的过程中,先写主分片,然后并行写副本分片,副本分片“写入成功”之后向主分片节点报告,然后主分片节点向协调节点报告,协调节点再返回给客户端,这里的写入成功指的是那个阶段,是写入内存了还是从内存每秒refresh进io cache了,如果是后者的话那是不是有可能一次请求运气不好的话要等待一秒才返回结果?
根据官网文档,这个是可以设置的,index.translog.durability如果设置成request(默认值),那么每次写入操作都要fsync和commit然后返回给客户端,这样肯定很耗费性能。如果是设置成async的话就会在每次写入内存成功后直接返回(这里确定是不是在translog写成功之后才返回),后台再根据上面所述机制自动flush.
此处结合文档理解:
es官方英文文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
中文翻译:https://www.jianshu.com/p/ffef3be04fd3
流程图:https://blog.csdn.net/feiying0canglang/article/details/126426436
16.读操作分两步,QUERY THEN FETCH,简单讲第一次只查id,就是协调节点把查询广播给各个分片,每个分片把自己查出来的id和优先级发给协调节点,协调节点再做个排序过滤,拿到真正应该用来fetch的那些id,然后再发给那些分片,拿到全部应该返回给客户端的数据。
17.优化
分片:一个分片可以当成一个独立的搜索引擎,会占用一块儿独立的空间,所以不是越多越好。推荐每个分片占用的硬盘容量不超过ES的jvm堆空间设置(一般为32g),所以如果预估数据最终增长到500g,就用16个分片。一般也建议总分片(包含副本)数量不超过节点的三倍,否则一个节点挂掉丢失的分片太多。