论文对方面级情感分析的三个任务提出了一个解决方案,三个任务共享编码层,通过简单的全连接层进行方面词和观点词的提取,情感分析任务首先做一个自注意力,之后分别与方面词和观点词提取的特征向量做互注意力,通过全连接层进行情感分类。另外,模型还设计了两个子任务,第一个将句子中的词屏蔽,预测这个词属于方面词、观点词还是普通词。第二个任务是将成对的方面词和观点词屏蔽,判断它们是否是成对的关系。模型最后进行了分析,证明提出的方案对多方面词更有效果。
摘要
基于方面的情感分析(ABSA)的现有工作采用了统一的方法,允许子任务之间的交互关系。然而,我们观察到,这些方法倾向于基于方面和观点术语的字面意义来预测极性,并且主要考虑单词级别的子任务之间的隐含关系。此外,识别多个方面-观点对及其极性更具挑战性。因此,ABSA需要进一步全面了解与方面和观点相关的上下文信息。在本文中,我们提出了深度上下文化关系感知网络(DCRAN),该网络允许子任务之间基于两个模块(即方面和观点传播以及显式自我监督策略)的深度上下文信息的交互关系 特别是,我们为ABSA设计了新颖的自我监督策略,该策略在处理多个方面具有优势。实验结果表明,在三个广泛使用的基准上,DCRAN显著优于先前最先进的方法。
1介绍
基于方面的情感分析(ABSA)是一项识别句子中相关方面词的情感极性的任务。通常,ABSA由三个子任务组成,1)方面术语提取(ATE),2)意见术语提取(OTE),和3)基于方面的情感分类(ASC)。鉴于“食物很好,但服务很糟糕”这句话,ATE旨在确定“食物”和“服务”两个方面的术语,OTE旨在确定两个观点术语“好”和“糟糕”。ASC为每个方面分配了一个情绪极性:“食物(积极)”和“服务(消极)”。
ABSA的现有工作采用了两步法,分别考虑每个子任务(Tang等人,2016;Xu等人,2018)。然而,最近,统一方法在ABSA任务中实现了显著的性能改进。Luo等人(2020)专注于对方面项之间的交互进行建模,Chen和Qian(2020)利用了子任务(即A TE、OTE、ASC)之间的二元和三元关系。
尽管结果令人印象深刻,但他们的方法有两个局限性。首先,他们只考虑单词级别的子任务之间的关系,而不明确地利用整个序列的上下文信息。例如,表1中的E1,意见术语“更好”似乎代表了对“日本食品”的积极意见。然而,E1的真正含义是“我在美食广场吃的日本菜比我在这家餐厅吃的更美味”。因此,以前的方法倾向于基于方面和观点术语的字面意义来分配极性(E2)。其次,识别多个方面-意见对及其极性更具挑战性,因为模型不仅需要检测多个方面观点,而且要检测它们的情感极性。
为了解决上述问题,我们提出了ABSA的深度上下文关系感知网络(DCRAN)。DCRAN不仅隐式地允许ABSA子任务之间的交互关系,而且通过使用上下文信息显式地考虑它们之间的关系。我们的主要贡献如下 :
(1)我们设计了方面和观点传播解码器,使模型能够全面理解整个上下文,从而更好地预测极性。
(2)我们为ABSA提出了新的自我监督策略,该策略在处理多个方面和考虑具有方面和观点术语的深度上下文化信息方面非常有效。据我们所知,这是首次尝试为ABSA设计明确的自我监督方法。
(3)实验结果表明,DCRAN在三个广泛使用的基准上显著优于先前的最新方法。
2 DCRAN:深度上下文关系感知网络
2.1任务定义
给定句子S={w1,w2,…,wn},其中n表示标记的数量,我们旨在解决三个子任务:方面项提取(ATE)、观点项提取(OTE)和基于方面的情感分类(ASC)作为序列标记问题。
ATE任务旨在识别一系列方面术语Y a={ya1,ya2,…,yan},其中yai∈ {B,I,O}和OTE任务旨在识别一系列意见术语Y O={yo1,yo2,…,yon},其中yoi∈ {B,I,O}方面和意见术语。同样,ASC任务的目标是分配极性序列Y p={yp 1,yp 2,…,ypn},其中yp i∈ {POS,NEU,NEG,O}。标签POS、NEU和NEG分别表示正极、中性和负极。

2.2任务共享表示学习
根据现有的工作,我们使用预训练的语言模型,如BERT(Devlin等人,2019)和ELECTRA(Clark等人,2020)作为共享编码器来构建上下文表示,由子任务:A TE、OTE和ASC共享。我们将共享编码器的参数表示为Θs。然后我们使用单层前馈神经网络(FFNN)作为,
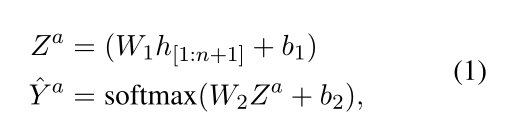
方面项提取的目标是最小化负对数似然(NLL)损失:
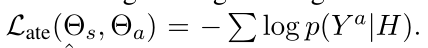
观点词提取的损失函数同上

2.3方面和意见传播
我们利用变压器解码器(V aswani et al.,2017)在预测极性序列时考虑方面和观点的关系。我们的变压器解码器主要由一个多头自关注、两个多头交叉关注和一个前馈层组成。多头自关注采用共享上下文表示H,
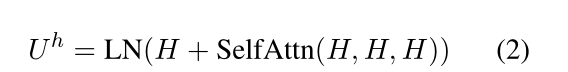
Uh、Za和Zo被馈送到两个互多头部注意力步骤中,

注意,等式3和4分别表示方面和意见传播。然后将U o馈入单层FFNN以获得极性序列Y p。基于方面的情感分析的目标是最小化NLL损失(负对数似然损失函数)
2.4显性自我监督策略
为了进一步利用体-观点与句子语境化信息的关系,我们提出了由两个辅助任务组成的显性自我监督策略:特定类型的掩蔽词鉴别和成对关系鉴别。
特定类型的掩蔽词鉴别
掩蔽句子的输入序列表示为,Xtsmtd=[[CLS]w1…[MASK]i…wn[SEP]],并输入到预先训练的语言模型中。然后,使用[CLS]标记的输出表示来将句子中哪种类型的术语屏蔽,
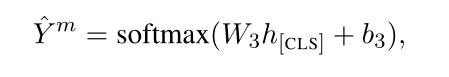
其中W3∈ R3×dh表示可训练参数,ˆY m∈ {Aspect,Opinion,O}。线性投影层的参数表示为θm,用于特定类型的掩蔽项判别。 这使得模型能够通过辨别被屏蔽的术语种类来显式地利用句子信息。
成对关系鉴别
在这项任务中,我们使用特殊标记[REL]统一替换方面和意见术语。掩蔽句子的输入序列表示为Xprd=[[CLS]w1…[REL]i…[REL]j…wn[SEP]],并被馈送到预先训练的语言模型中。用CLS预测被屏蔽的词是否具有成对的关系。
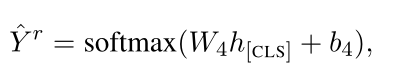
2.5联合学习
所有这些任务都是联合训练的,最终目标定义为:

3实验
3.2定量结果
表2报告了LAP14、REST14和REST15数据集的定量结果。我们的实验使用两种预训练语言模型,如BERT和ELECTRA,用于共享编码器。首先,我们观察到,在REST14和LAP14数据集(REST15数据集除外)上,DCRAN BERTbase显示的ABSA-F1分数略低于先前最先进的方法,该方法基于BERTlarge。 这表明我们提出的方法对ABSA非常有效。总体而言,DCRAN BERTlarge在所有指标上都显著优于以前的最新方法。另一个观察结果是,基于ELECTRA的模型优于基于BERT的模型。因此,在LAP14、REST14和REST15数据集上,DCRAN ELECTRAlarge在ABSA-F1中分别实现了5.5%、4.4%和7.6%的绝对增益,超过了先前最先进的结果。
3.3消融实验
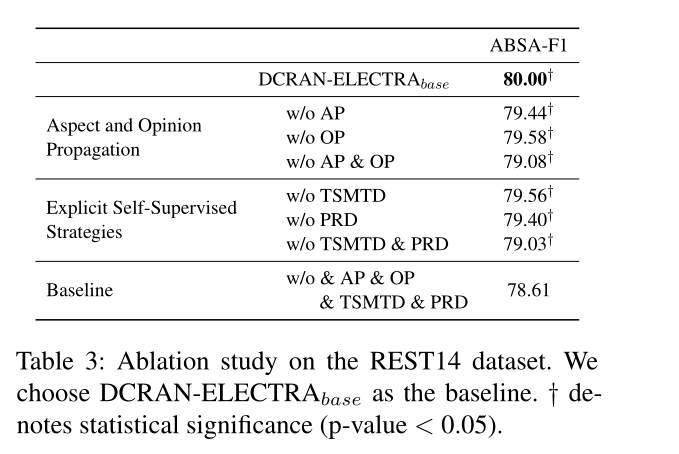
为了研究方面传播(AP)、意见传播(OP)、类型特定掩蔽词辨别和成对关系掩蔽词鉴别的有效性。我们在REST14数据集上进行消融实验。我们设置了基线模型,该模型没有利用方面和意见传播以及明确的自我监督策略。当不使用AP和OP时,如等式1中那样使用单层FFNN来预测极性序列Y p,而不是变压器解码器。如表3所示,我们可以观察到AP比OP更有效,当不使用AP和OP时,得分显著下降。在显式自我监督策略的情况下,我们可以观察到PRD比TSMTD更有效。由于PRD的目标是区分替换标记是否具有成对的方面-观点关系,因此它允许模型在句子层次上更多地利用方面和观点之间的关系。
3.4方面分析
我们通过比较句子的单体和多体来进行体分析。通过这些观察,我们证明了我们提出的方法对于句子包含多个方面的情况是非常有效的。
4结论
在本文中,我们提出了基于方面的情感分析的深度上下文关系感知网络(DCRAN)。DCRAN允许子任务之间以更有效的方式隐式交互,并允许两种显式自我监督策略用于深度上下文和关系感知学习。我们在三个广泛使用的基准上获得了最新的最新结果。
- 上下文 Relation-Aware Aspect-based Sentiment 深度上下文relation-aware aspect-based sentiment aspect-based challenge effective sentiment aspect-based 上下文qos深度 属性 relation-aware relation document-level relation-aware extraction sentiment sentiment-aware sentiment sentix sentiment-aware cross-domain structural extraction sentiment triplet