在机器学习中,术语Ensemble指的是并行组合多个模型,这个想法是利用群体的智慧,在给出的最终答案上形成更好的共识。
这种类型的方法已经在监督学习领域得到了广泛的研究和应用,特别是在分类问题上,像RandomForest这样非常成功的算法。通常应用一些投票/加权系统,将每个单独模型的输出组合成最终的、更健壮的和一致的输出。
在无监督学习领域,这项任务变得更加困难。首先,因为它包含了该领域本身的挑战,我们对数据没有先验知识,无法将自己与任何目标进行比较。其次,因为找到一种合适的方法来结合所有模型的信息仍然是一个问题,而且对于如何做到这一点还没有达成共识。
在本文中,我们讨论关于这个主题的最佳方法,即相似性矩阵的聚类。
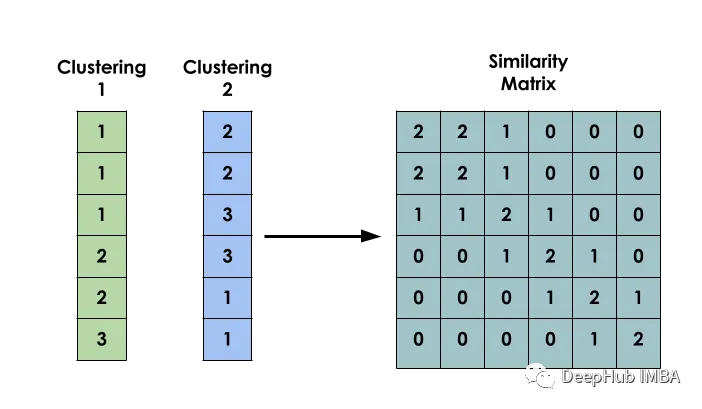
该方法的主要思想是:给定一个数据集X,创建一个矩阵S,使得Si表示xi和xj之间的相似性。该矩阵是基于几个不同模型的聚类结果构建的。
https://avoid.overfit.cn/post/526bea5f183249008f77ccc479e2f555