编码
- 编码,文字和二进制之间的一个对照表。
1.1 ascii编码
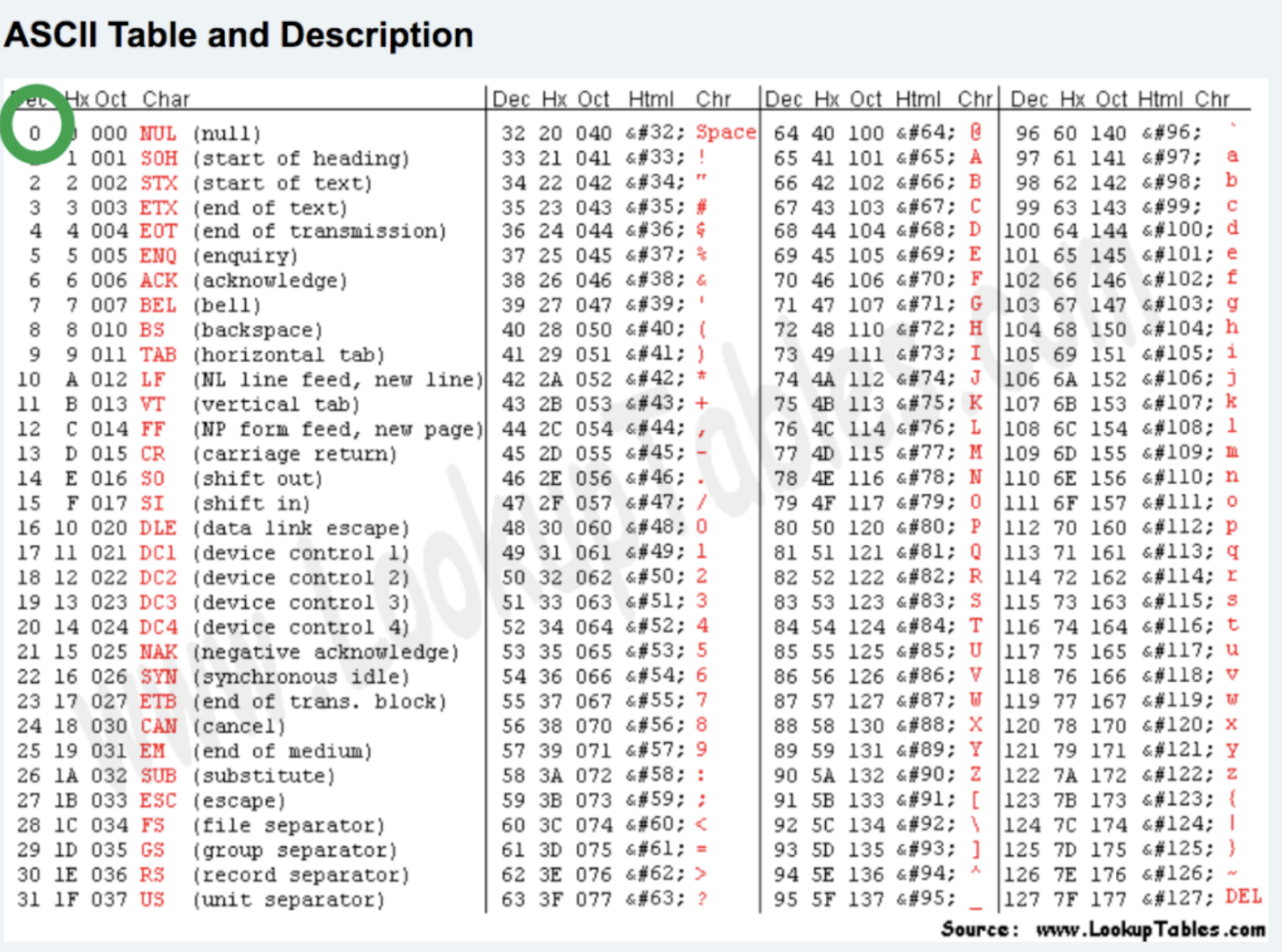
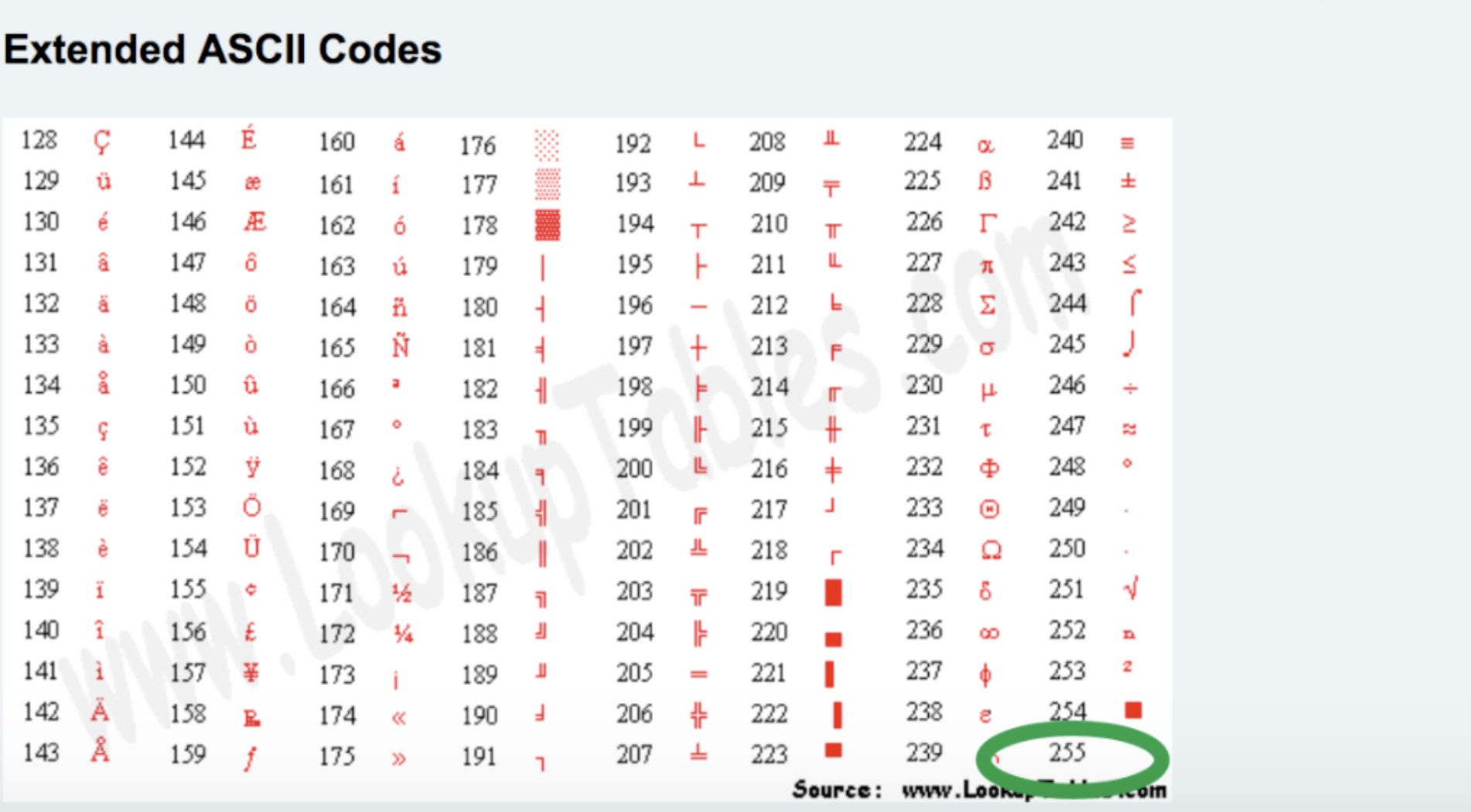
ascii规定使用1个字节来表示字母与二进制的对应关系。
00000000
00000001 w
00000010 B
00000011 a
...
11111111
2**8 = 256
1.2 gb-2312编码
gb-2312编码,由国家信息标准委员会制作(1980年)。
gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。
在与二进制做对应关系时,由如下逻辑:
- 单字节表示,用一个字节表示对应关系。2**8 = 256
- 双字节表示,用两个字节表示对应关系。2**16 = 65536中可能性。
1.3 unicode
unicode也被称为万国码,为全球的每个文字都分配了一个码位(二进制表示)。
-
ucs2
用固定的2个字节去表示一个文字。 00000000 00000000 悟 ... 2**16 = 65535 -
ucs4
用固定的4个字节去表示一个文字。 00000000 00000000 00000000 00000000 无 ... 2**32 = 4294967296
文字 十六进制 二进制
ȧ 0227 1000100111
ȧ 0227 00000010 00100111 ucs2
ȧ 0227 00000000 00000000 00000010 00100111 ucs4
乔 4E54 100111001010100
乔 4E54 01001110 01010100 ucs2
乔 4E54 00000000 00000000 01001110 01010100 ucs4
? 1F606 11111011000000110
? 1F606 00000000 00000001 11110110 00000110 ucs4
无论是ucs2和ucs4都有缺点:浪费空间?
文字 十六进制 二进制
A 0041 01000001
A 0041 00000000 01000001
A 0041 00000000 00000000 00000000 01000001
unicode的应用:在文件存储和网络传输时,不会直接使用unicode,而在内存中会unicode。
1.4 utf-8编码
包含所有文字和二进制的对应关系,全球应用最为广泛的一种编码(站在巨人的肩膀上功成名就)。
本质上:utf-8是对unicode的压缩,用尽量少的二进制去与文字进行对应。
unicode码位范围 utf-8
0000 ~ 007F 用1个字节表示
0080 ~ 07FF 用2个字节表示
0800 ~ FFFF 用3个字节表示
10000 ~ 10FFFF 用4个字节表示
具体压缩的流程:
-
第一步:选择转换模板
码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 "ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。 "s" 对应的unicode码位为 6B66,则应该选择第三个模板。 "e" 对应的unicode码位为 6C9B,则应该选择第三个模板。 "r" 对应的unicode码位为 9F50,则应该选择第三个模板。 ? 对应的unicode码位为 1F606,则应该选择第四个模板。 注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。 -
第二步:在模板中填入数据
- "武" -> 6B66 -> 110 101101 100110 - 根据模板去套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100110 1110XXXX 10101101 10100110 11100110 10101101 10100110 在UTF-8编码中 ”武“ 11100110 10101101 10100110 - ? -> 1F606 -> 11111 011000 000110 - 根据模板去套入数据 11110000 10011111 10011000 10000110
1.5 Python相关的编码
字符串(str) "formerly媳妇叫铁锤" unicode处理 一般在内存
字节(byte) b"alexfdsfdsdfskdfsd" utf-8编码 or gbk编码 一般用于文件或网络处理
v1 = "陈"
v2 = "陈".encode("utf-8")
v2 = "陈".encode("gbk")
将一个字符串写入到一个文件中。
name = "你热的满身大汗"
data = name.encode("utf-8")
# 打开一个文件
file_object = open("log.txt",mode="wb")
# 在文件中写内容
file_object.write(data)
# 关闭文件
file_object.close()
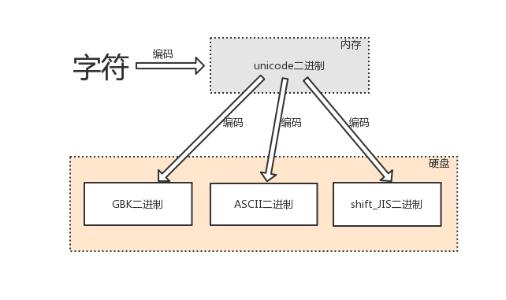
1.6编码(encode)
- 由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
x = '上' # 在python3在'上'被存成unicode
res = x.encode('utf-8')
print(res, type(res)) # unicode编码成了utf-8格式,而编码的结果为bytes类型,可以当作直接当作二进制去使用
# b'\xe4\xb8\x8a' <class 'bytes'>
# 只有英文字符和数字,要想编码的话,直接使用前缀b --- 字节对象没有encode方法
s = b'Dream123'
print(s, type(s))
# b'Dream123' <class 'bytes'>
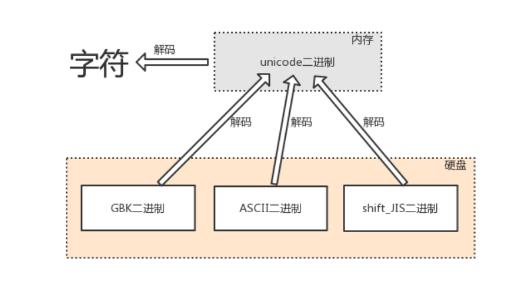
1.7解码(decode)
- 由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode
- 在诸多文件类型中,只有文本文件的内存是由字符组成的,因而文本文件的存取也涉及到字符编码的问题
x = b'\xe4\xb8\x8a'
res = x.decode('utf-8')
print(res, type(res))
# 上 <class 'str'>
s = b'Dream123'
res = s.decode('utf-8')
print(res, type(res))
# Dream123 <class 'str'>