基本概念
LEO
LEO(log end offset) 称为日志末端位移,代表日志文件中下一条待写入消息的 offset,这个 offset 上实际是没有消息的。
分区 ISR 集合中的每个副本(所有的 leader 和 follower 副本)都会维护自身的 LEO。当 leader 副本收到生产者的一条消息,LEO 通常会自增 1,而 follower 副本需要从 leader 副本 fetch 到数据后,才会增加它的 LEO。
High Watermark
HW(High Watermark) 称为高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。
High watermark is calculated as the minimum LEO across all the ISR of this partition, and it grows monotonically.
ISR 集合中最小的 LEO 即为分区的 HW,消费者只能读取到小于高水位线以下的消息,即成功复制到所有副本的最后一条消息。因此,对于同一个副本对象,其高水位值不会大于 LEO 值。

在分区高水位以下的消息被认为是已提交消息,反之就是未提交消息。消费者只能消费已提交的消息,即图中位移小于 8 的所有消息。
最后 leader 副本会比较自己的 LEO 以及满足条件的 follower 副本上的 LEO ,选取两者中较小值作为新的 HW ,来更新自己的 HW 值。
HW 和 LEO 更新流程
每个副本对象都保存了一组高水位值和 LEO 值,但实际上,在 Leader 副本所在的 Broker 上,还保存了其他 Follower 副本的 LEO 值(Remote LEO)。

在这张图中,我们可以看到:
-
Leader 副本:Broker 0 上保存了该分区的 Leader 副本和所有 Follower 副本的 LEO 值,Kafka 把 Broker 0 上保存的这些 Follower 副本又称为远程副本(Remote Replica);
-
follower 副本:Broker 1 上仅仅保存了该分区的某个 Follower 副本。
Kafka 副本机制在运行过程中,会更新 Broker 1 上 Follower 副本的高水位和 LEO 值,同时也会更新 Broker 0 上 Leader 副本的高水位和 LEO 以及所有远程副本的 LEO,但它不会更新远程副本的高水位值,即中标记为灰色的部分。
LEO
LEO 的更新时机:
-
Follower 副本的 LEO:follower 副本从 leader 副本拉取消息,写入到本地磁盘后,就会更新其 LEO 的值;
-
Leader 副本的 LEO:leader 副本接收到生产者发送的消息,写入本地磁盘后,就会更新其 LEO 的值;
-
Leader 副本的 Remote LEO:follower 副本的 fetch 请求中包含的 offset,这个 offset 就是 follower 副本的 LEO,leader 副本会使用这个位移值来更新远程副本的 LEO;
可以看出在 leader 副本给 follower 副本返回数据之前,remote LEO 就先更新了。
HW
高水位的更新时机:
-
Follower 副本的高水位
follower 成功更新完 LEO之后,会比较它的 LEO 与 leader 副本返回的高水位,并用两者的较小值去更新它的高水位。
可以看出,如果 follower 的 LEO 值超过了 leader 的 HW 值,那么,follower 的 HW 值是不会超过 leader HW 值的。因为有些副本同步的过程可能较慢,因此,这里 follower 必须取最小值。
-
Leader 副本的高水位
高水位有四个更新时机:
-
生产者向 leader 写消息,会尝试更新高水位;
-
leader 处理 follower 的 fetch 请求,在更新完远程副本的LEO之后,会尝试更新高水位;
-
follower 副本成为 leader 副本时,会尝试更新高水位;
-
broker 崩溃可能会波及 leader 副本,也需要尝试更新高水位。
更新算法:取 leader 副本和所有与 leader 同步的远程副本的 LEO 中的最小值。
一个远程副本,要与 leader 保持同步,需要满足两个条件:
-
该 follower 副本在 ISR 中;
-
该 follower 副本的LEO 落后于 LEO的时间不超过 Broker 端参数
replica.lag.time.max.ms的值。
-
leader 和 follower 更新高水位的流程
leader 和 follower 更新高水位的流程,如下图所示:

Leader 副本
Leader 主要有两部分流程:
处理生产者请求
处理生产者请求的逻辑如下:
-
写入消息到本地磁盘;
-
更新分区高水位值:
-
获取 Leader 副本保存的所有满足条件的远程副本 LEO 值:\(LEO_1, LEO_2, \cdots ,LEO_n\);
-
获取 Leader 副本高水位值: \(currentHW\);
-
更新 \(currentHW = \max(currentHW, \min(LEO_1, LEO_2, \cdots ,LEO_n)\)
-
处理 Follower 副本拉取消息
处理 Follower 副本拉取消息的逻辑如下:
-
读取磁盘(或页缓存)中的消息数据;
-
使用 Follower 副本发送请求中的位移值更新远程副本 LEO 值;
-
更新分区高水位值(具体步骤与上面处理生产者请求的步骤相同)。
副本同步机制
下面,我们一个当生产者发送一条消息时,Leader 和 Follower 副本对应的高水位的更新过程,来介绍副本同步的机制。
初始状态
首先初始状态,所有的副本上 LEO 都是 0:

生产者发送消息
当生产者给主题分区发送一条消息后,Leader 副本成功将消息写入了本地磁盘,该消息的位移为 \(offset = 0\),因此, Leader 副本的 LEO 值被更新为 1:

Follower 拉取消息
此时,Follower 再次尝试从 Leader 拉取消息,由于这次有消息可以拉取了,Follower 副本也成功地更新 LEO 为 1,此时,Leader 和 Follower 副本的 LEO 都是 1,但各自的高水位依然是 0。
如下图所示:

Follower 再次拉取消息
由于 \(offset = 0\) 的消息已经拉取成功,因此,follower 这次请求拉取的是位移值 \(offset = 1\) 的消息。
leader 接收到此请求后,首先将 Remote LEO 更新为 1,然后,再将 leader 高水位更新为 1,最后,它会将当前已更新过的高水位值 \(HW = 1\) 发送给 Follower 副本。
Follower 副本接收到以后,也将自己的高水位值更新成 1。
过程,如下图所示:

至此,一次完整的消息同步周期就结束了,事实上,Kafka 就是利用这样的机制,实现了 Leader 和 Follower 副本之间的同步。
高水位同步机制的缺陷
从前面的步骤,我们可以可看出:leader 中保存的 remote LEO 值的更新总是需要额外一轮 fetch RPC 请求才能完成。这意味着在 leader 切换过程中,会存在数据丢失以及数据不一致的问题。
数据丢失问题
如下图所示,假设有两个副本 A 和 B,其中, B 为 leader 副本,A 为 follower 副本。
从前面的流程,我们可以看出来,leader 中的 HW 值是在 follower 的下一轮 fetch RPC 请求中完成更新的。
我们考虑,如下时序:
-
在 follower A 进行的第二段 fetch 请求,并接收到响应之后,此时,Leader B 已经将 HW 更新为 2;
-
此时,follower A 还没处理完响应就崩溃了,即 follower 没有及时更新 HW 值;
-
follower A 重启后,会自动将 LEO 值调整到之前的 HW 值,即会进行日志截断,
-
然后,follower A 接着会再次向 B 发送 fetch 请求,但此时,Leader B 也发生宕机了;
此时,Kafka 会将 follower A 选举为新的分区 Leader;
-
当 B 重启后,会从向 A 发送 fetch 请求,收到 fetch 响应后,拿到 HW 值,并更新本地 HW 值。
此时,B 的高水位值,会从 HW = 2 更新为 HW = 1,此时,B 会做日志截断,这样就会导致 offsets = 1 的消息被永久地删除了。
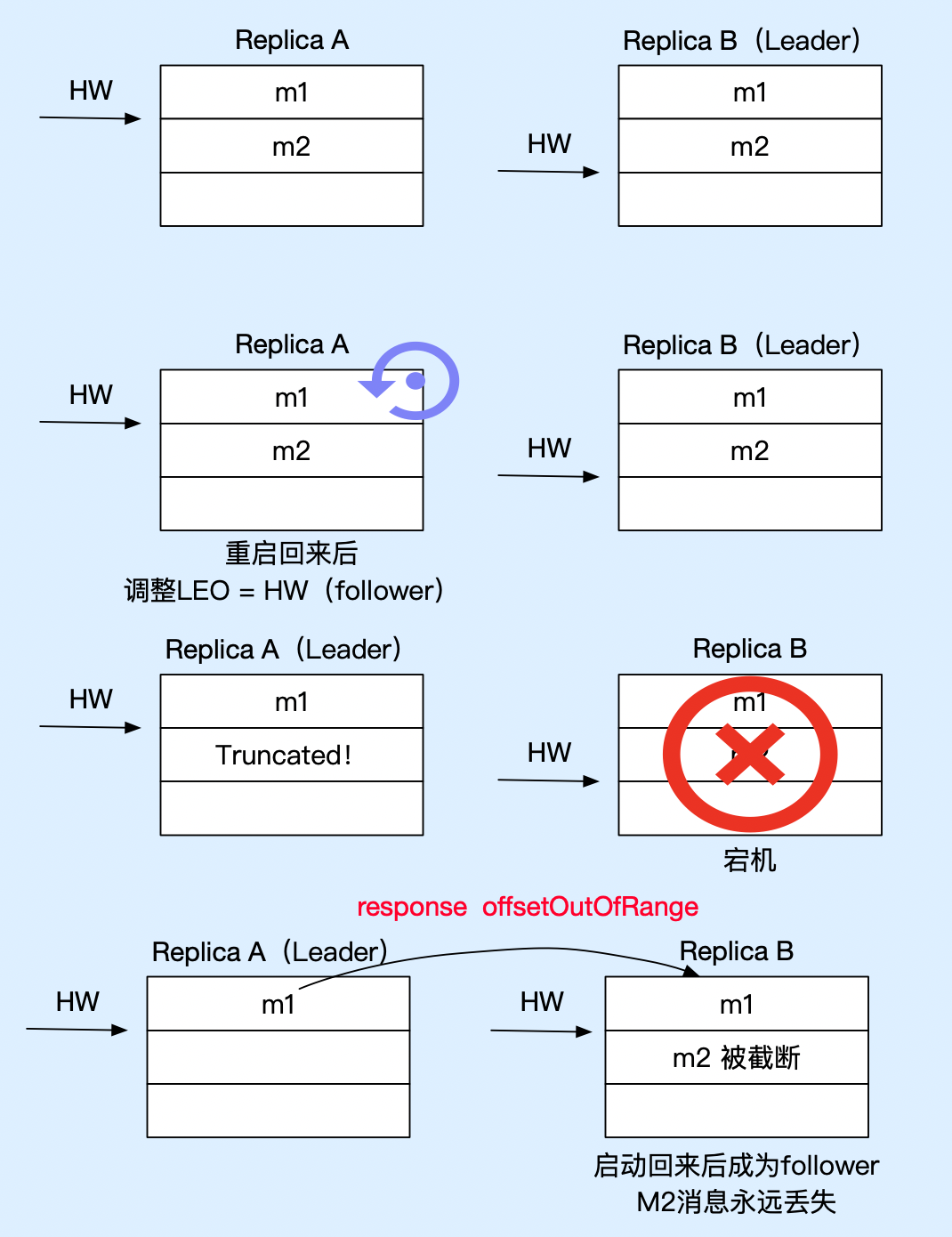
消费者发送的消息会先被记录到 leader 副本,follower 再从 leader 中拉取消息进行同步,这就导致 leader LEO 会比 follower 的要大。
假设,此时出现 leader 切换,有可能选举了一个 LEO 较小的 follower 成为新的 leader,这时,该副本的 LEO 就会成为新的标准,这就会导致 follower LEO 值,有可能会比 leader LEO 值要大的情况。
因此,follower 在进行同步之前,需要从 leader 获取 LastOffset 的值,如果 LastOffset 小于当前 LEO,则需要进行日志截断,然后再从 leader 拉取数据实现同步。
由于,HW 值以上的消息是没有“已提交”或“已备份”的,因此,位移值大于 HW 的消息是对消费者不可见的,即这些消息不对用户作承诺,也即是说从 HW 值截断日志,并不会导致数据丢失(承诺用户范围内)。
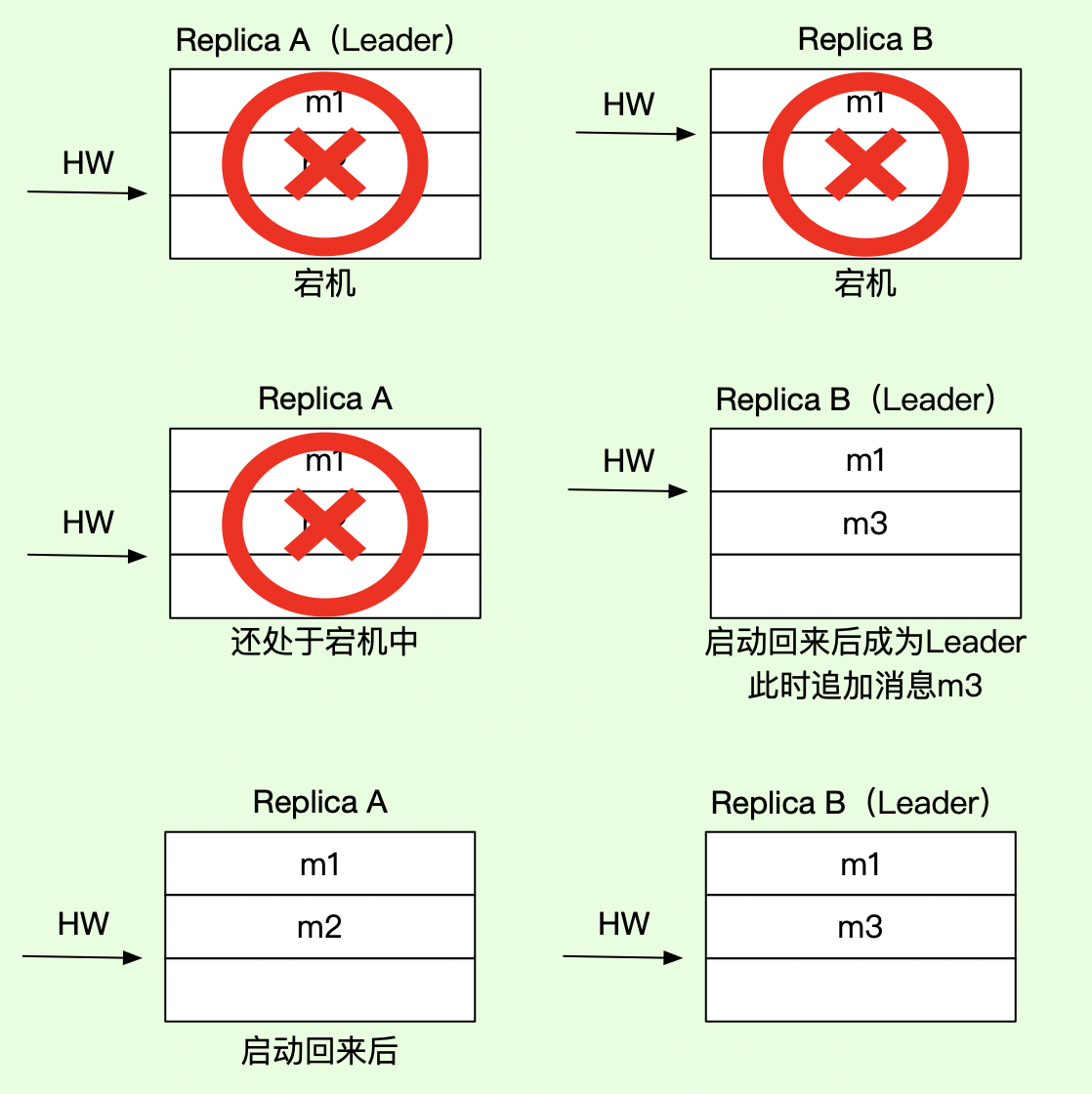
数据一直性问题
如下图所示,假设有两个副本 A 和 B,其中,A 为 leader 副本,B 为 follower 副本。
我们考虑,如下时序:
-
leader A 已经写入两条消息,且高水位已经更新为 HW = 2,同时,follower B 只写了 1条消息,且 HW = 1;
-
此时,A 和 B 同时宕机,follower B 先重启完成,并且,B 被选举成为了 leader 副本;
-
接着,生产者发送了一条消息,保存到 B 中,由于此时分区只有 B,B 在写入消息时,立刻就把高水位更新为 HW =2;
-
然后,A 重新启动,发现 A的高水位 HW = 2,跟自己的 HW 一样,因此,就没有执行日志截断,这就造成了 A 的 offset=1 的日志与 B 的 offset=1 的日志不一样的现象。
以上情况,需要满足以下其中一个条件才会发生:
-
宕机之前,B 已不在 ISR 列表中,
unclean.leader.election.enable=true,即允许非 ISR 中副本成为 leader; -
B 消息写入到 PageCache,但尚未 flush 到磁盘。
Leader Epoch
为了解决 HW 更新时机是异步延迟的,而 HW 又是决定日志是否备份成功的标志,从而造成数据丢失和数据不一致的现象,Kafka 引入了 leader epoch 机制,在每个副本日志目录下都创建一个 leader-epoch-checkpoint 文件,用于保存 leader 的 epoch 信息,如下,leader epoch 长这样:
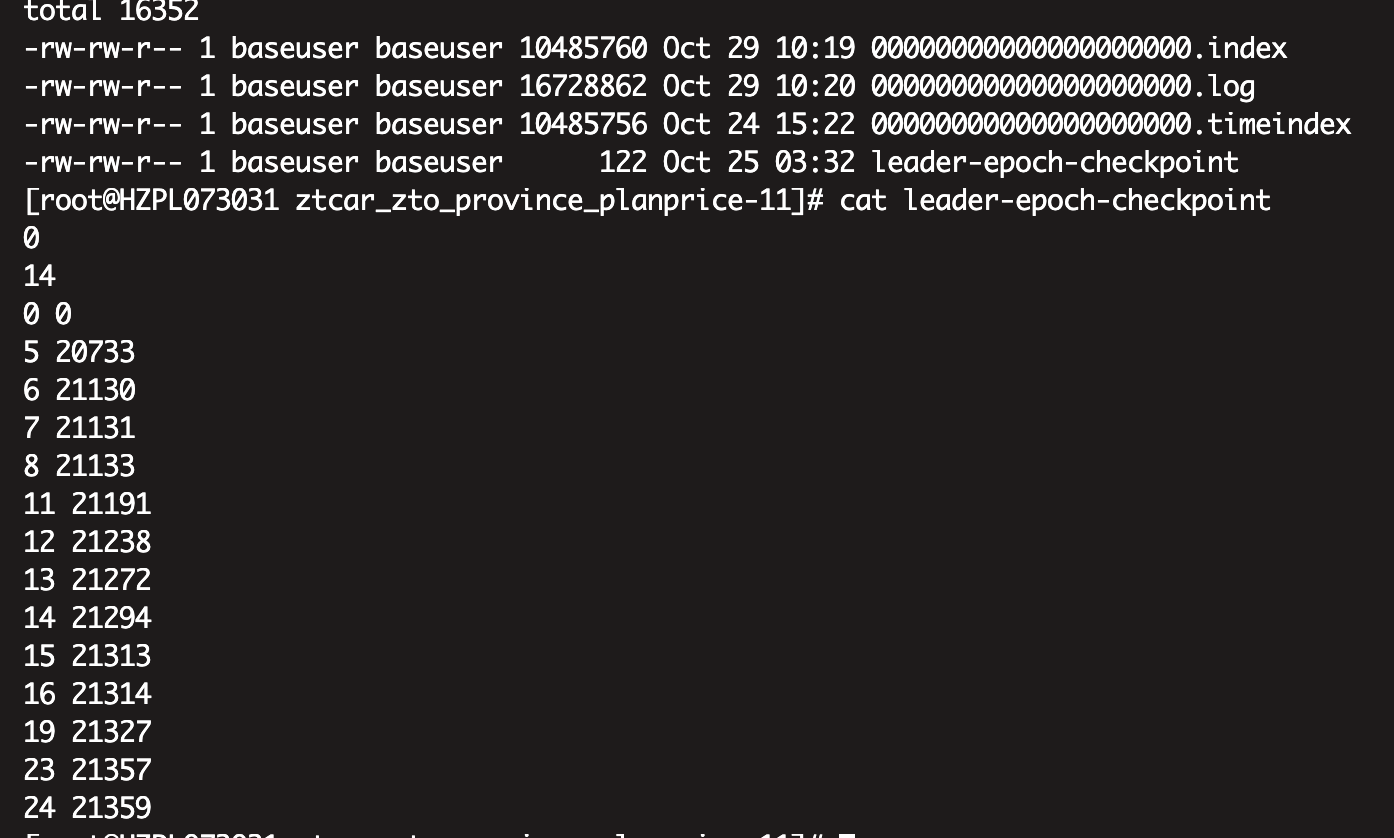
leader-epoch-checkpoint 文件中内容的格式为:<epoch offset>
-
epoch:是 leader 版本,它是一个单调递增的一个正整数值,每次 leader 变更,epoch 版本都会 +1,
-
offset:是每一代 leader 写入的第一条消息的位移值
leader epoch 工作机制
leader epoch 具体的工作机制如下:
1)当副本成为 leader 时:
这时,如果此时生产者有新消息发送过来,会首先新的 leader epoch 以及 LEO 添加到 leader-epoch-checkpoint 文件中。
2)当副本变成 follower 时:
发送 LeaderEpochRequest 请求给 leader 副本,该请求包括了 follower 中最新的 epoch 版本;
leader 返回给 follower 的相应中包含了一个 LastOffset,如果 follower last epoch = leader last epoch,则 LastOffset = leader LEO,否则取大于 follower last epoch 中最小的 leader epoch 的 start offset 值,举个例子:假设 follower last epoch = 1,此时 leader 有 (1, 20) (2, 80) (3, 120),则 LastOffset = 80;
follower 拿到 LastOffset 之后,会对比当前 LEO 值是否大于 LastOffset,如果当前 LEO 大于 LastOffset,则从 LastOffset 截断日志;
follower 开始发送 fetch 请求给 leader 保持消息同步。
基于 leader epoch 的工作机制,我们接下来看看它是如何解决水印备份缺陷的:
解决数据丢失问题
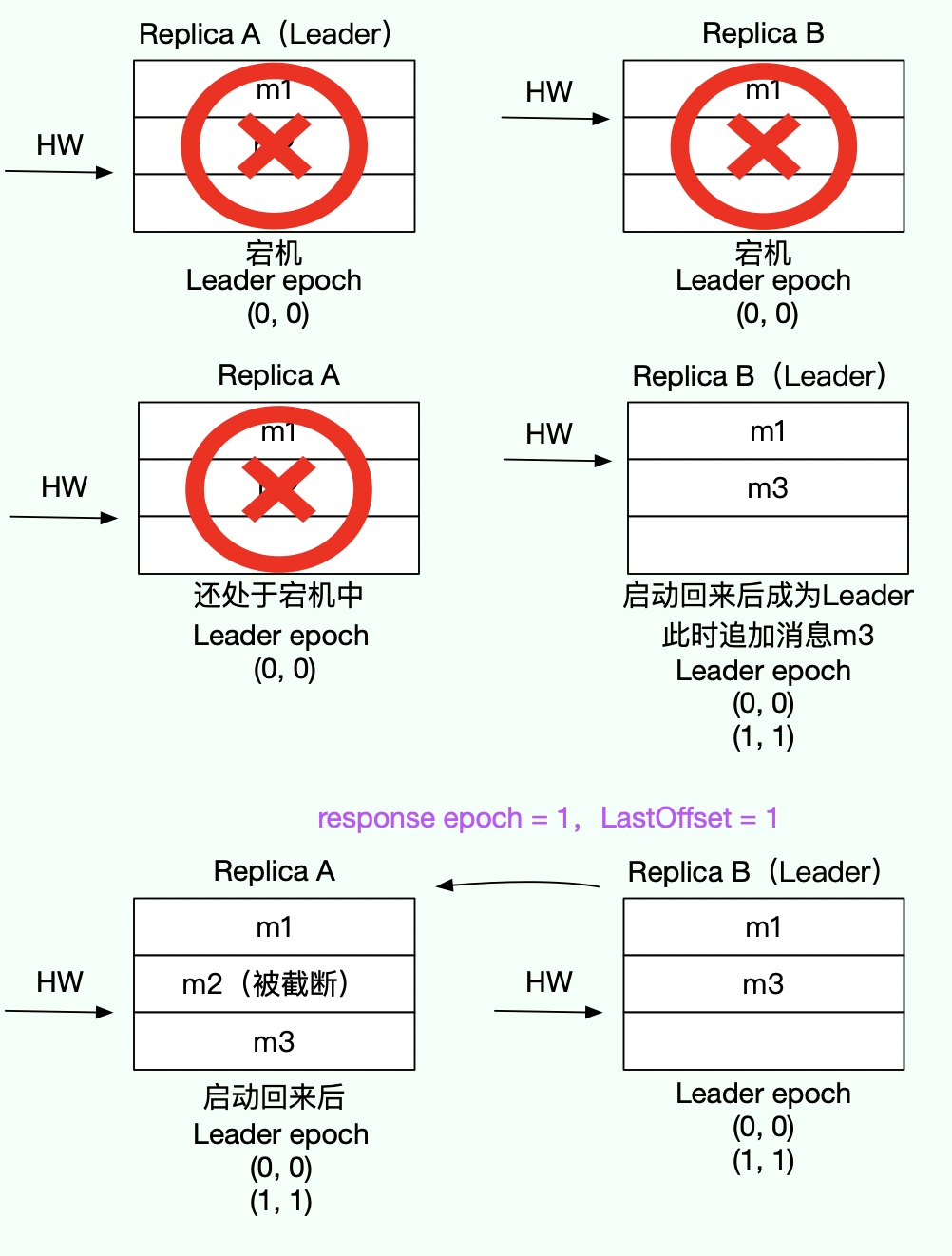
如上图所示,A 重启之后,发送 LeaderEpochRequest 请求给 B,由于 B 还没追加消息,此时 epoch = request epoch = 0,因此返回 LastOffset = leader LEO = 2 给 A,A 拿到 LastOffset 之后,发现等于当前 LEO 值,故不用进行日志截断。就在这时 B 宕机了,A 成为 leader,在 B 启动回来后,会重复 A 的动作,同样不需要进行日志截断,数据没有丢失。
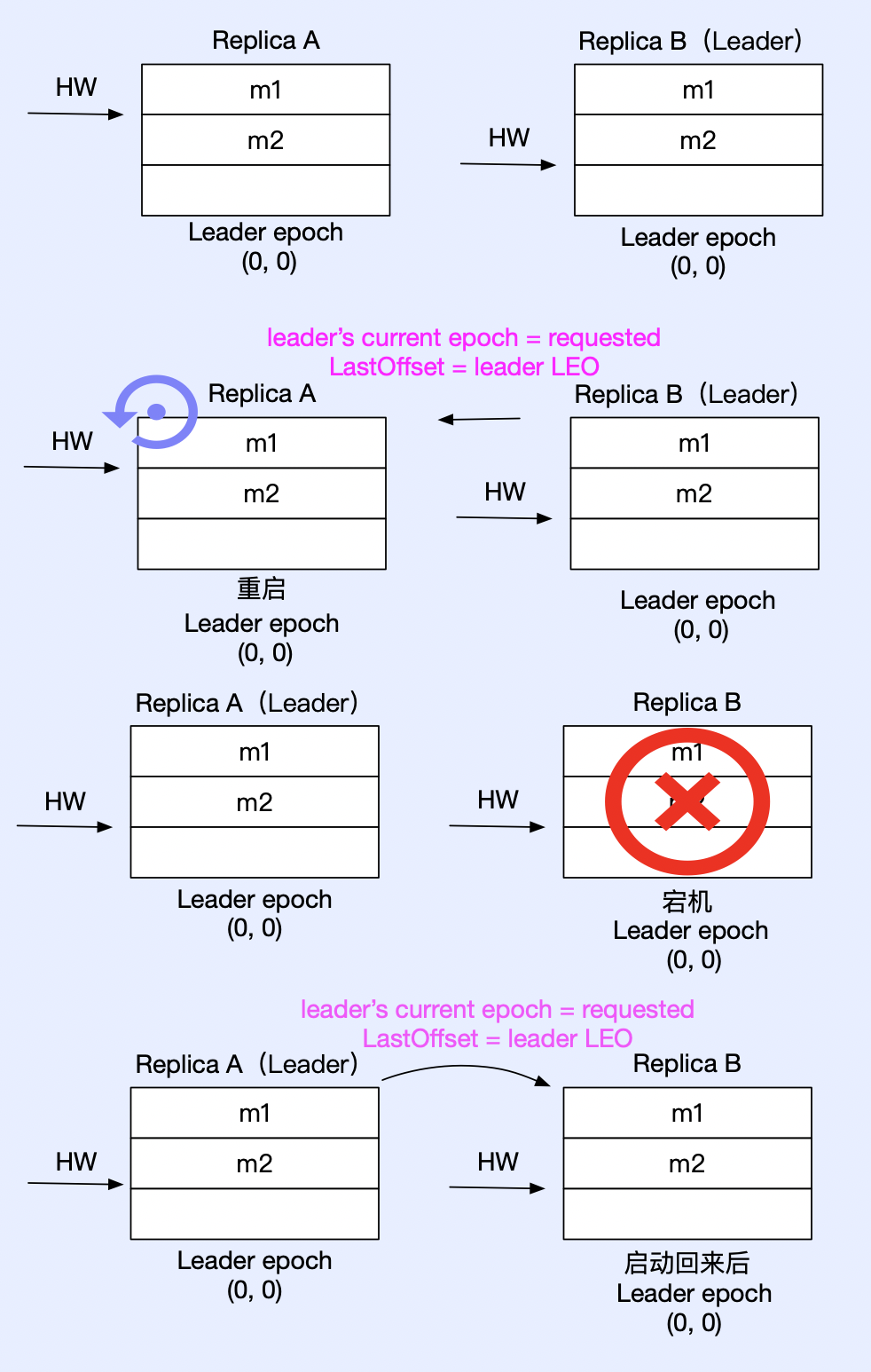
解决数据不一致问题
如上图所示,A 和 B 同时宕机后,B 先重启回来成为分区 leader,这时候生产者发送了一条消息过来,leader epoch 更新到 1,此时 A 启动回来后,发送 LeaderEpochRequest(follower epoch = 0) 给 B,B 判断 follower epoch 不等于 最新的 epoch,于是找到大于 follower epoch 最小的 epoch = 1,即 LastOffset = epoch start offset = 1,A 拿到 LastOffset 后,判断小于当前 LEO 值,于是从 LastOffset 位置进行日志截断,接着开始发送 fetch 请求给 B 开始同步消息,避免了消息不一致/离散的问题。
参考:
-
《Kafka 核心技术与实战》