Scala迭代器与RDD五大属性
迭代器就是读数据的工具
Scala迭代器的理解
迭代器是读数据的工具,例如Scala的List就提供了它自己的迭代器(读数据工具),而我们也可以自己写迭代器去读List里面的数据,而不使用List的迭代器。
自己编写迭代器读List数据
class MyFileIterable(filePath:String) extends Iterable[String]{
override def iterator: Iterator[String] = new MyFileIterator(filePath)
}
class MyFileIterator(filePath:String) extends Iterator[String]{
private val br = new BufferedReader(new FileReader(filePath))
var line: String = null
override def hasNext: Boolean = {
line = br.readLine()
line != null
}
override def next(): String = {
line
}
}
需要实现hasNext()和next()方法。注:由于后文需要使用groupBy,而Iterator并没有这个方法,因此我们再继承一个Iterable
- 测试WordCount
object MyFileIteratorTest{
def main(args: Array[String]): Unit = {
val iterable = new MyFileIterable("data/wordcount/input/a.txt")
iterable
.flatMap(s=>s.split("\\s+"))
.map(s=>(s,1))
.groupBy(tp => tp._1)
.map(tp => (tp._1,tp._2.size))
.foreach(println)
}
}
迭代器中map方法探究
map方法和hasnext、next方法是不同的,map是对原来迭代器里的数据做一个指定映射,而hasnext,next是一个取数的过程。让我们看看iterator.map的源码。

可以看到,map传入了一个计算逻辑f,返回了一个新的迭代器。而新迭代器的next()是原来迭代器next上套了一层计算逻辑A。
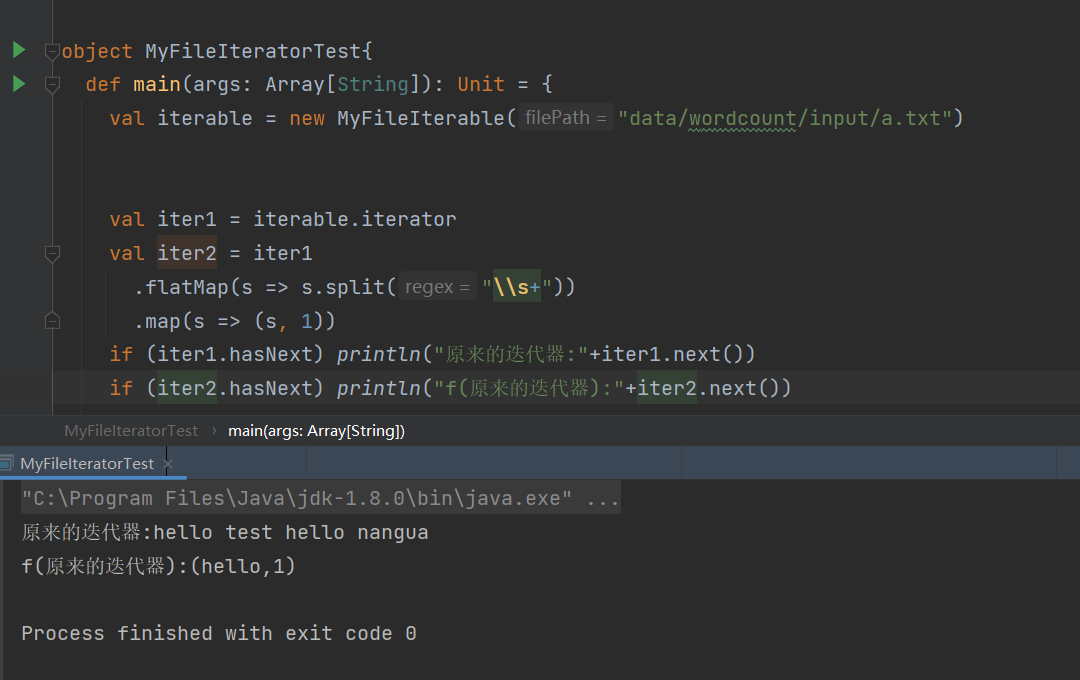
如果我们不进行hasnext next的话,就只是定义了iter1和iter2,并不会有数据计算,这就是lazy特性。
那源头迭代器是怎么样的呢?在末端迭代器调用next后,一直调用到最开始的源头迭代器,那源头迭代器一定是需要真正读数据的了,而读的方式则根据数据源的不同而设计的,就如上面的例子是用BufferedReader;而数据源有很多,例如:
- hdfs
- 本地磁盘文件
- 内存中的数据
- mysql
联系scala迭代器与RDD
经过上文,是不是感觉到迭代器和RDD有巨多的相似之处,RDD的本质就是迭代器!
RDD中的两种计算操作
Transcation转换操作
transcation转换操作的基本思路就和scala迭代器中的map操作基本一致,都是套计算逻辑。上源码。
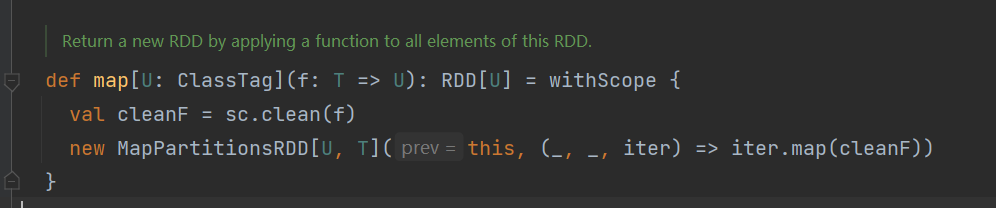
Action执行操作
action执行操作也和上文一样,就是调用迭代器的next


Compute
transaction和action综合起来就是RDD里面的计算函数compute,而compute就是返回了一个迭代器!

RDD的五大属性
- 一个分区列表
- 作用到每个分区的计算函数
- 依赖RDD列表
- 【可选】对于KV类型的RDD会有一个Partitioner(例如,定义某个RDD是Hash分区的)
- 【可选】每个分区的首选计算执行位置
计算函数(最核心)
抽象理解:计算函数就是作用在每一个partition上的逻辑运算函数;
具象理解:上文已经看到了,compute实质就是返回了一个迭代器,这个迭代器保存了这个RDD的计算逻辑。
依赖RDD列表(重要)
计算函数的核心是迭代器,而迭代器又需要依赖上一个迭代器,因此RDD也需要依赖上一个RDD。
依赖RDD列表存储了当前RDD所依赖的一个或多个前序RDD。
那列表代表什么意思呢?这里的列表并不是说记录了整条RDD链,它仅仅记录上一层RDD,但是上一层RDD并不一定只有一个;如map就确实只有一个父RDD,但如join则有两个父RDD了;所以这里需要使用列表。
分区列表(重要)
在分布式环境中,数据源需要被分成多块进行并行计算,而Spark也是如此的。
RDD中数据集的基本组成单位是分区。
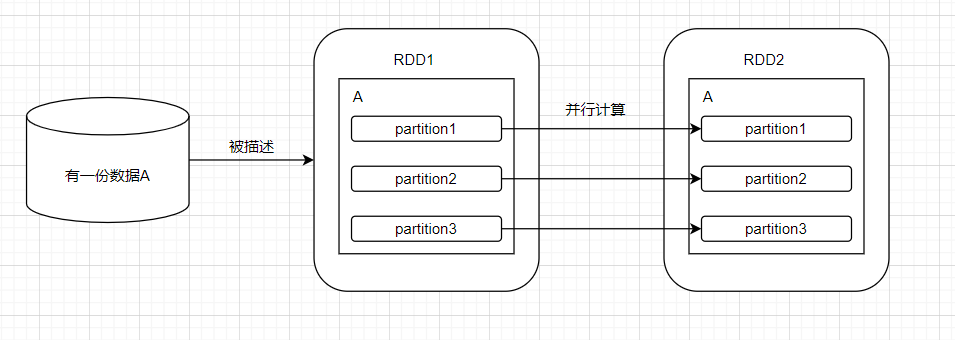
(注:并不一定RDD1的分区一一对应RDD2的分区,可以了解一下宽窄依赖)
对于RDD1来说,它的分区数是3,决定了并行度也是3,而每一个分区都会被一个计算任务处理。
因此,一个RDD一定需要记录数据的分区信息,这就是分区列表。这里再强调一下,RDD只描述数据,而不实际存储数据,这个分区也只是一种描述。

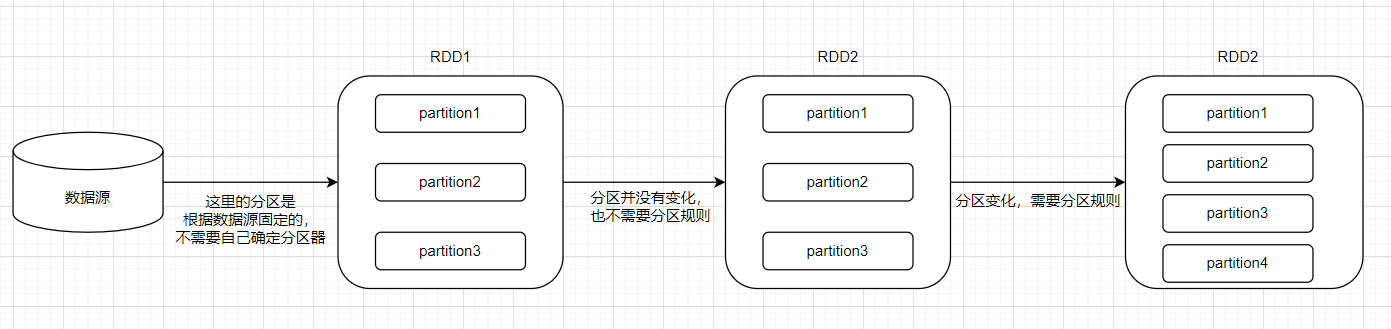
KV类型RDD的分区器【可选】
分区器就是一种分区规则,但分区发生变化的时候,需要有分区规则来对数据进行分区。
那什么时候需要用到分区器呢?
每个分区的首选计算执行位置【可选】
分区放在哪台机器计算是有讲究的,设想,如果分区1的数据存在机器A上,那是不是在机器A执行该分区的执行任务更为合理呢?减少网络传输能有效提高效率。而这个属性就是记录了哪个分区在哪里算最好。
总结
本文从Scala迭代器引出了RDD的本质,并且介绍了RDD源码所说的五大属性的含义。再进一步理解,就需要从整个Spark的运行模式开始了。