什么是文本文件和文本编辑器
文本文件
文本文件是纯字符文件,它含有的所有字节必然能够采用某种字符集编码显示出字符,除了BOM字节。
字符集和换行符。
SUMMARY
作者:Keen Kwok
链接:https://www.zhihu.com/question/41426907/answer/90924168
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 字符集就是编码和字符的对应关系,比如说,在 ASCII 编码中,一个'A'字符对应'0x42'。不同的对应关系导致了不同字符集的出现。
- 字符编码就是字符在内存中的二进制显示(也可以理解为从理论到实践)。比如,'爱'这个的Unicode对应的字符编码为'0x7231',而使用UTF-8的编码方式,'爱'的字符编码(内存中存储数据格式)为'0xE788B1',UTF-16BE的字符编码为'0x7231'
默认是 ANSI
Windows早期(至少是95年以前的事情了)是ANSI字符集的,也就是说一个中文文本,在Windows简体中文版显示的是中文,到Windows日文版显示的就不知道是什么东西了。
后来,Windows支持了Unicode,但当时大部分软件都是用ANSI编码的,unicode还不流行,怎么办?Windows想了个办法,就是允许一个默认语言编码,就是当遇到一个字符串,不是unicode的时候,就用默认语言编码解释。(在区域和语言选项里可以改默认语言)
这个默认语言,在不同Windows语言版本里是不同的,在简体中文版里,是GBK,在繁体中文版里,是BIG5,在日文版里是JIS
而记事本的ANSI编码,就是这种默认编码,所以,一个中文文本,用ANSI编码保存,在中文版里编码是GBK模式保存的时候,到繁体中文版里,用BIG5读取,就全乱套了。
记事本也不甘心这样,所以它要支持Unicode,但是有一个问题,一段二进制编码,如何确定它是GBK还是BIG5还是UTF-16/UTF-8?记事本的做法是在TXT文件的最前面保存一个标签,如果记事本打开一个TXT,发现这个标签,就说明是unicode。标签叫BOM,如果是0xFF 0xFE,是UTF16LE,如果是0xFE 0xFF则UTF16BE,如果是0xEF 0xBB 0xBF,则是UTF-8。如果没有这三个东西,那么就是ANSI,使用操作系统的默认语言编码来解释。
Unicode的好处就是,不论你的TXT放到什么语言版本的Windows上,都能正常显示。而ANSI编码则不能。(UTF-8的好处是在网络环境下,比较节约流量,毕竟网络里英文的数据还是最多的)
概念区分:字符集和字符集编码
字符集:character set。 囊括某种或某几种文化的符号的集合,并且为这些符号分配一个唯一的数字编号。
字符集编码:character set encoding。把字符集内的每个符号的数字编号,按照某种规则,映射成二进制数值来存储到计算机,二进制数值并不一定要求等于数字编号。 encode & decode
ASCII
ASCII (American Standard Code for Information Interchange)
字符集:阿拉伯数字(0123456789),英文字母(a-z A-Z),英文符号(!@#$*等),控制打印机的字符,以上4种字符组成的字符集合。字符的数字编号范围是0-127.
字符集编码:一个字节,最高位恒0,其他位保持与数字编号相等。如 字符A -> 编号65 -> 编码01000001.
字符集编码和字符集编号的关系:字符集编码和字符集编号相等。
表示范围:0000 0000 - 0111 1111 (0X00 - 0X7F)
ASCII固定占用一个字节,最高位恒0,共计128个字符。33个字符是控制打印机动作的,称为控制字符,95个字符是可打印的,称为可见字符。
| 显示字符 | 控制字符 | |
|---|---|---|
| 32-126 (阿拉伯数字,英文字母,符号) | 0-31 , 127 (控制字符) |
部分控制打印机的字符的解释如下:(有些控制字符随着IT发展和设备的进步,已经失去原有的意义或者其作用已经发生改变。)
NUL (0)
NULL,空字符。空字符起初本意可以看作为 NOP(中文意为空操作,就是啥都不做的意思),此位置可以忽略一个字符。
之所以有这个空字符,主要是用于计算机早期的记录信息的纸带,此处留个 NUL 字符,意思是先占这个位置,以待后用,比如你哪天想起来了,在这个位置在放一个别的啥字符之类的。
后来呢,NUL 被用于C语言中,表示字符串的结束,当一个字符串中间出现 NUL 时,就意味着这个是一个字符串的结尾了。这样就方便按照自己需求去定义字符串,多长都行,当然只要你内存放得下,然后最后加一个\0,即空字符,意思是当前字符串到此结束。
BEL (7)
BELl,响铃。在 ASCII 编码中,BEL 是个比较有意思的东西。BEL 用一个可以听得见的声音来吸引人们的注意,既可以用于计算机,也可以用于周边设备(比如打印机)。
注意,BEL 不是声卡或者喇叭发出的声音,而是蜂鸣器发出的声音,主要用于报警,比如硬件出现故障时就会听到这个声音,有的计算机操作系统正常启动也会听到这个声音。蜂鸣器没有直接安装到主板上,而是需要连接到主板上的一种外设,现代很多计算机都不安装蜂鸣器了,即使输出 BEL 也听不到声音,这个时候 BEL 就没有任何作用了。
LF (10)
Line Feed,直译为“给打印机等喂一行”,也就是“换行”的意思。LF 是 ASCII 编码中常被误用的字符之一。
LF 的最原始的含义是,移动打印机的头到下一行。而另外一个 ASCII 字符,CR(Carriage Return)才是将打印机的头移到最左边,即一行的开始(行首)。很多串口协议和 MS-DOS 及 Windows 操作系统,也都是这么实现的。
而C语言和 Unix 操作系统将 LF 的含义重新定义为“新行”,即 LF 和 CR 的组合效果,也就是回车且换行的意思。
从程序的角度出发,C语言和 Unix 对 LF 的定义显得更加自然,而 MS-DOS 的实现更接近于 LF 的本意。
现在人们常将 LF 用做“新行(newline)”的功能,大多数文本编辑软件也都可以处理单个 LF 或者 CR/LF 的组合了。
CR (13)
Carriage return,回车,表示机器的滑动部分(或者底座)返回。
CR 回车的原意是让打印头回到左边界,并没有移动到下一行的意思。随着时间的流逝,后来人们把 CR 的意思弄成了 Enter 键,用于示意输入完毕。
在数据以屏幕显示的情况下,人们按下 Enter 的同时,也希望把光标移动到下一行,因此C语言和 Unix 重新定义了 CR 的含义,将其表示为移动到下一行。当输入 CR 时,系统也常常隐式地将其
DEL (127)
Delete,删除。
有人也许会问,为何 ASCII 编码中其它控制字符的值都很小(即 0~31),而 DEL 的值却很大呢(为 127)?
这是由于这个特殊的字符是为纸带而定义的。在那个年代,绝大多数的纸带都是用7个孔洞去编码数据的。而 127 这个值所对应的二进制值为111 1111(所有 7 个比特位都是1),将 DEL 用在现存的纸带上时,所有的洞就都被穿孔了,就把已经存在的数据都擦除掉了,就起到了删除的作用。
Latin1
扩展的ASCII字符集,又称作 EASCII 和 ISO 8859-1
字符集:ASCII和欧洲字符组成的字符集合。字符的数字编号范围是0-255
字符集编码:一个字节,保持与数字编号相等。如字符 ß->编号223->编码1101 1111
字符集编码和字符集编号的关系:字符集和字符集编号相等。
ASCII只能覆盖英文符号,欧洲国家让最高位可为1,又扩展了128个字符,来存放欧洲国家的语言字符,如丹麦语,德语,法语,瑞典语等。
表示范围:0000 0000 - 1111 1111 (0X00 - 0XFF)。其中 0000 0000 - 0111 1111仍旧是ASCII字符,1000 0000 - 1111 1111表示扩展的欧国国家语言文化字符。
它兼容ASCII字符集。
[EASCII字符表?](D:\OneDrive\repository\asserts\ASCII_ISO 8859 (Latin-1) Table (2023_4_12 20_51_54).html)
ANSI
ANSI字符串转换成的字节数组,会把首字节置于字节数组的前部分(低地址),所以不存在大小端问题,且无BOM概念,文本文件中的字节全是有效数据。
Latin1同ASCII一样,仅使用一个字节满足了欧美国家。但是使用象形文字的亚洲国家一个字节(至多256个字符)完全不够用,所以亚洲国家的本土化字符编码会使用多字节。如大陆的GB2312,GBK;港澳台的BIG5;日本的Shift-JIS。
这些本土化字符集仍旧使用1个字节表示ASCII,完全兼容ASCII,但是使用2个字节表示本土化的字符。双字节的第一个字符和单字节不一样,所以很容易区分出字节表示的是单字节还是双字节从而保证了解码的效率。
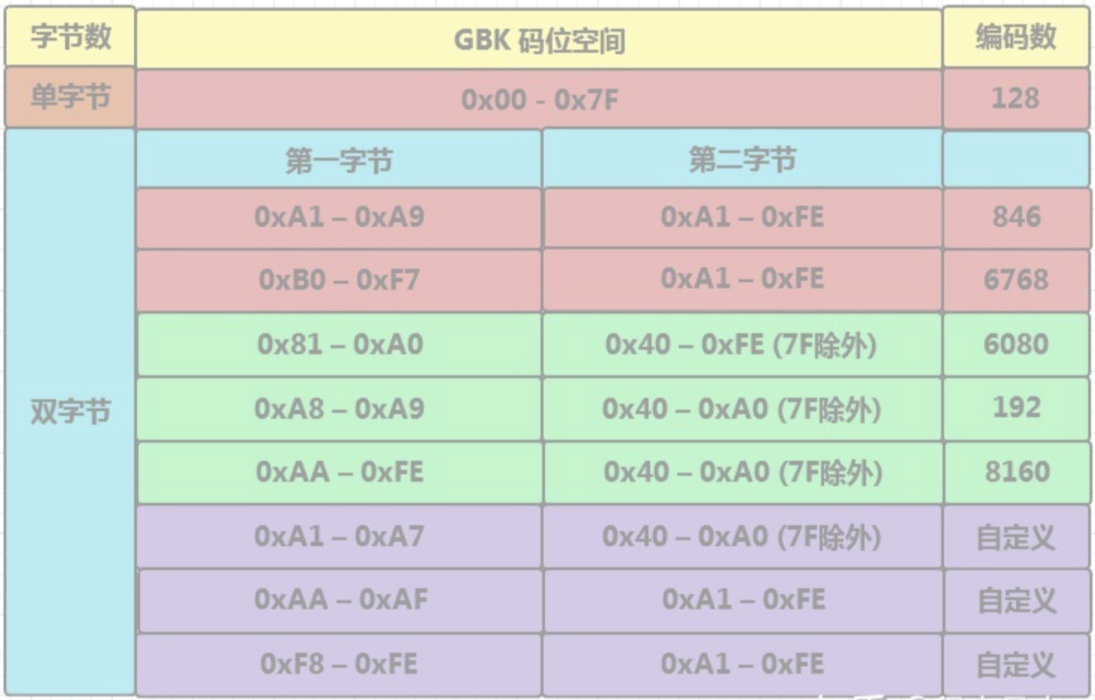
这些本土化的字符集称作ANSI,ANSI具体指什么字符编码,取决于操作系统的语言和区域设置,如中文操作系统,ANSI是指GBK,日文操作系统则是指Shift-JIS。
ANSI解决了字符本土化的问题,但是各个国家的字符编码除了ASCII外的其他字符都无法兼容,导致大量乱码现象。如使用BIG5生成的文本文件,在简体中文操作系统上使用GBK解码(虽然GBK也包含繁体字)得到的却是乱码文件。
能不能诞生出一种编码方式能统一全世界的字符呢?那就要说起Unicode了。
unicode,code point,utf
首先区分一个概念:
Unicode为世界上的所有字符分配了一个唯一的编号。
Unicode 本身只规定了每个字符的数字编号是多少,并没有规定这个编号如何存储。
Unicode是字符集,相当于接口,只是对字符进行编号。UTF是字符编码,相当于具体类,参照Unicode的编号决定二进制的存储形式。
Unicode 是国际标准字符集,它旨在囊括世界上所有的符号,且为符号分配一个唯一的数字符号,以满足跨语言、跨平台的文本信息转换。Unicode 字符集的编码范围是 0x000000 - 0x10FFFF , 可以容纳一百多万个字符,每个字符都有一个数字编号和它对应,这里的数字编号也叫码位(code point)。
Unicode字符集的编码存储方案有三种:UTF8,UTF16,UTF32.
UTF8
UTF8是变长编码,长度1-4个字节,常用字符用少字节存储,单字节与ASCII相同,兼容ASCII。
UTF32
| Unicode编号 | UTF32-LE | UTF32-BE |
|---|---|---|
| 0X006C49 | 0X496C0000 | 0X00006C49 |
UTF32采用一一映射的方式,存储二进制等于Unicode数字编号。
再次强调,Unicode只是编号,只是字符集,UTF是字符编码存储方案。
有的人会说了,那我可以直接把 Unicode 编号直接转换成二进制进行存储,是的,你可以,貌似也解决了问题。但是这有很大的缺点,比如Unicode 0x01只需要一个字节即可,但是采用上述策略必须使用0x000001,这浪费了极大的存储空间和传输成本,比如UTF16和UTF32就有上述缺点。所以,计算机采用根据Unicode码点映射成其他二进制进行存储,存储的二进制形式和Unicode码点的二进制形式并不相同。如,
汉字 中 Unicode编号是0x4E2D,对应的UTF并不是0x4E2D,而是0xE4B8AD。
UTF-8存储单个字符,可能是1或2或3或4个字节,1个字节兼容ASCII。
UTF-16存储单个字符,可能是2或4个字节,2个字节的字符相当于直接拷贝Unicode。不兼容ASCII。
UTF-32存储单个字符,全部都是4个字节,不兼容ASCII。
UTF意思是unicode转换格式(Unicode transform format),出现UTF8、UTF16、UTF32是出于要在内存中存储字符的目的而对unicode字符编号进行编码。
UTF8、UTF16、UTF32区别:(8、16、32可看做每种字符编码存储所需的最少的比特位数)
综上所述,UTF-8、UTF-16、UTF-32 都是 Unicode 的一种实现。
小于128的(即Ox00-0x7E之间的字符),编码与Ascii码一样,最高位为0。其他编号的第一个字节有特殊含义,最高位有几个连续的1表示一共用几个字节表示,而其他字节都以10开头。4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位Ox10EEEE也只有21位。
对于一个Unicode编号,具体怎么编码呢?首先将其看做整数,转化为二进制形式(去掉高位的O),然后将二进制位从右向左依次填入到对应的二进制格式x中,填完后,如果对应的二进制格式还有没填的x,则设为0。
| 字节数 | Unicode | UTF-8编码 |
|---|---|---|
| 1 | 000000-00007F | 0xxxxxxx |
| 2 | 000080-0007FF | 110xxxxx 10xxxxxx |
| 3 | 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF16
UTF16结合了定长和变长,2个字节或4个字节。2个字节已经包含了常用的字符,常用作系统内部编码。Windows采用Unicode作为默认编码,其实就是utf16,且只采用2个字节。所以常误导我们以为utf16就是2个字节的固定长编码。 2个字节已经包含最常用的字符。
注意: UTF-8和UTF-32/UTF-16不同的地方是UTF-8是兼容Ascii的,对大部分中文而言,一个中文字符需要用三个字节表示。UTF-8的优势是网络上数据传输英文字符只需要1个字节,可以节省带宽资源。所以当前大部分的网络应用都使用UTF-8编码,因为网络应用的代码编写全部都是使用的英文编写,占据空间小,网络传输速度快。(这就是为什么网站采用utf-8编码的原因)
问题: 比如一个文本软件,在打开一个文件的时候,如何判断这个文件是使用的什么编码呢,该用什么编码进行解码呢?
那么就需要通过BOM (Byte Order Mark)来指明了。
Unicode标准建议用BOM (Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符"零宽无中断空格"。这个字符的编码是FEEE,而反过来的FFEE(UTEF-16)和EFFFE0000(UTE-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。
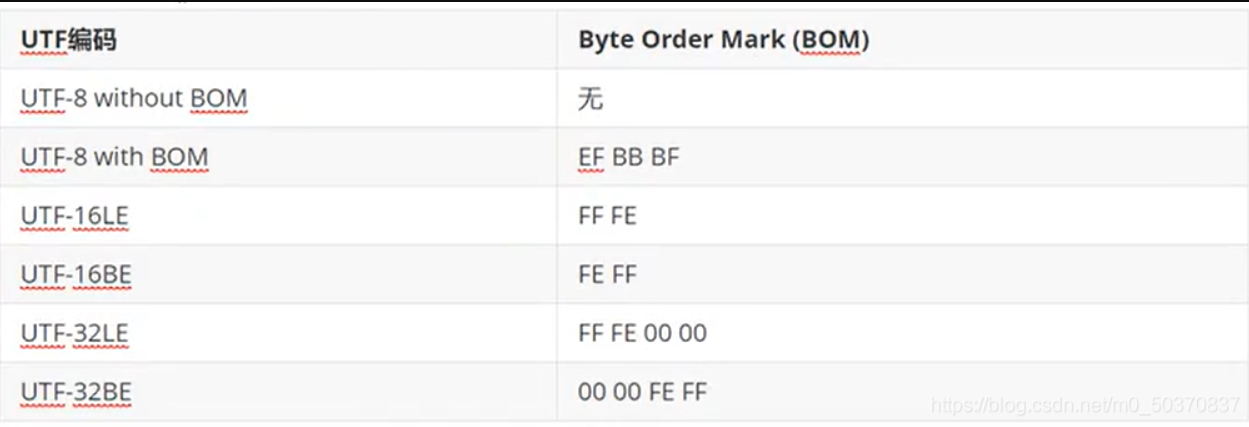
注意:UTF-8不需要BOM来表明字节顺序(其没有大端小段之分),但可以用BOM来表明文件是UTF-8的编码方式。根据BON的规则,在一段字节流开始时,如果接收到以下字节,则分别表明了该文本文件的编码。而如果不是以BOM开头,那程序则会以ANSI,也就是系统默认编码读取。
问: 为什么系统默认编码是GBK,而不是Unicode编码呢?
其实究其原因还是为了节省系统资源,GBK基本上可以代表绝大多数的中文字符.
UTF和BOM
BOM : Byte Order Mark
假设在小端主机上运行下行代码
byte[] bytesLE = Encoding.Unicode.GetBytes("中");
中的UTF16是0X4e2d,相当于一个具有高低权重2个字节的的整数,如果主机是小端,则bytesLE[0] = 0X2d,bytesLE[1] = 0X4e,存储在磁盘中的字节顺序是0X2d,0X4e。
当大端主机读取磁盘文件到内存时得到的字节数组bytesBE的顺序必然也是0X2d,0X4e。在大端主机运行
string s = Encoding.Unicode.GetString(bytesBE);
会被认作0X4e2d这个整数对应的UTF16字符,这样就出现了解码错误。
为解决上述现象,国际组织规定,在使用UTF16字符编码的文本文件的头部采用4个字节标识是大端模式还是小端模式,即UTF16-Little Endian和UTF16-Big Endian。
FEFF表示UTF16-Big Endian,FFFE表示UTF16-Little Endian。
UTF32同理会和UTF16一样。
UTF-8不会被解读成整数,而是单个字节,所以不存在这种问题。所以不需要BOM,但是微软为了统一,也会为UTF-8文本添加BOM,EF BB BF,表示此文本是UTF-8,其实这不是必须的。
UTF-8 BOM 和 UTF-8
通过前文我们知道UTF-8的BOM不是必须的,但加上也不错。不同的文本编辑器有的允许加BOM,有的不允许,导致凉凉。
PHP脚本解析失败,MYSQL脚本运行失败,CSV乱码等。
字符集和字符编码
UTF-8不需要BOM来表明字节顺序(其没有大端小段之分),但可以用BOM来表明文件是UTF-8的编码方式。根据BON的规则,在一段字节流开始时,如果接收到以下字节,则分别表明了该文本文件的编码。而如果不是以BOM开头,那程序则会以ANSI,也就是系统默认编码读取。
UTF8,ANSI,UTF16如何相互转换
在Windows平台下,ANSI、UTF-8、Unicode三者之间的转换主要依赖于WideCharToMultiByte和MultiByteToWideChar两个函数。
- Unicode转UFT-8:设置
WideCharToMultiByte的CodePage参数为CP_UTF8; - UTF-8转Unicode:设置
MultiByteToWideChar的CodePage参数为CP_UTF8 - Unicode转ANSI:设置
WideCharToMultiByte的CodePage参数为CP_ACP; - ANSI转Unicode:设置
MultiByteToWideChar的CodePage参数为CP_ACP; - UTF-8转ANSI:先将UTF-8转换为Unicode,再将Unicode转换成ANSI;
- ANSI转UTF-8:先将ANSI转换为Unciode,再将Unicode转换成ANSI。
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
1)GBK、GB2312 --先转--> Unicode --再转--> UTF8
2)UTF8 --先转--> Unicode --再转--> GBK、GB2312
C# API转换字符集
Unicode作为中介。
必然的,不然就是组合问题,太他妈复杂了。
如果有机会选择应用程序要使用的编码,则应使用 Unicode 编码,最好是 UTF8Encoding 或 UnicodeEncoding。 (.NET 还支持第三种 Unicode 编码,即 UTF32Encoding。)
如果打算使用 ASCII 编码 (ASCIIEncoding),请选择 UTF8Encoding 。 这两个编码对于 ASCII 字符集而言是相同的,但 UTF8Encoding 具有以下优点:
- 它可以表示每个 Unicode 字符,而 ASCIIEncoding 仅支持 U+0000 到 U+007F 之间的 Unicode 字符值。
- 它提供错误检测,具有更高的安全性。
- 速度已达到最优,应快于任何其他编码。 即使对于全是 ASCII 的内容,使用 UTF8Encoding 执行操作的速度要快于 ASCIIEncoding。
UTF8Encoding encoding = new UTF8Encoding(); // 定制编码参数,如大小端,BOM头,错误处理方式
UnicodeEncoding unicodeEncoding = new UnicodeEncoding();
Encoding.UTF8;
Encoding.Unicode;
文本编辑器自动识别文本的编码的策略
识别BOM,有BOM头,则按照BOM头去解码,无BOM则按照操作系统的默认字符集编码去解读。
比如在一台简体中文的操作系统上去打开一个日本人。
所以,最好使用UTF8编码。
使用Excel打开CSV为什么是乱码?
含有中文的CSV文件的编码若是UTF8 NO BOM,使用Excel打开是乱码。
原因:Excel加载CSV文件时发现没有BOM,就认为不是UTF,转而采用操作系统默认编码ANSI(GBK)解码打开,最终乱码了。
解决方案有以下3种:
- 改用UTF8 With BOM生成CSV。
- 改用GBK生成CSV。
- 打开Excel,在菜单栏选择【数据】-【自文本】,选中CSV文件后指定65001-UTF8打开。