前一篇实现了ResNet18训练自定义数据集,详细介绍了数据集制作、模型构建及训练,并且介绍了相应模块如何可视化。前面训练阶段是在python环境下进行的,但实际工程部署的时候大都采用C++实现推理,这一篇我们借助OpenCV实现ResNet18推理。
一、准备
1、OpenCV编译及安装
借助OpenCV实现ResNet18推理,首先需要准备好工具,OpenCV源码编译及安装可参考:
https://www.cnblogs.com/xiaxuexiaoab/p/15894993.html
2、其他环境
Windows10
visual Studio 2019
二、OpenCV推理ResNet18
依据前一篇python模型测试脚本来看,主要分为图片预处理和模型预测两大步,但OpenCV的dnn模块读取ONNX格式模型,所以这里分成模型转换,数据预处理和推理三部分。
1、模型转换
将pytorch训练的模型转换为ONNX格式,这里借助torch.onnx.export()接口进行实现。
- 加载权重
类似模型测试一样,先加载训练好的权重参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = resnet18()
model = nn.Sequential(*list(model.children())[:-1], # [b, 512, 1, 1] -> 接全连接层
# torch.nn.Flatten(),
nn.Linear(512, 2)).to(device) # 添加全连接层
model.load_state_dict(torch.load("./resnet18-2Class.pth"))
model.eval()
- 准备数据
生成固定大小的随机数,便于后期进行转换
img_size = 64
data = torch.randn(1, 3, img_size, img_size).to(device)
- 模型转换
这里利用torch.onnx.export()接口进行转换
onnx_save_path = "./resnet18_2class.onnx"
print("Start convert model to onnx...")
torch.onnx.export(model,
data,
onnx_save_path,
opset_version=10,
do_constant_folding=True, # 是否执行常量折叠优化
input_names=["input"], # 输入名
output_names=["output"], # 输出名
dynamic_axes={"input": {0: "batch_size"}, # 批处理变量
"output": {0: "batch_size"}}
)
print("convert onnx is Done!")
- 验证转换是否正确
要验证转换是否正确,只需要加载不同模型,对同一份数据进行推理,对比其结果是否正确
# check
import onnx
import onnxruntime
torch_out = model(data)
print("torch_out: ", torch_out)
onnx_model = onnx.load(onnx_save_path)
onnx.checker.check_model(onnx_model) # onnx自带检查工具
print(onnx.helper.printable_graph(onnx_model.graph))
session = onnxruntime.InferenceSession(onnx_save_path)
inputs = {session.get_inputs()[0].name: data}
onnx_out = session.run(None, inputs)[0]
print("onnx_out: ", onnx_out)
# 对比
def test_diff(o_output, f_output):
print("Max abs diff: ", (o_output - f_output).abs().max().item())
assert(o_output.argmax() == f_output.argmax())
# print(o_output[0][0].item(), f_output[0][0].item())
print("MSE diff: ", torch.nn.MSELoss()(o_output, f_output).item())
test_diff(torch_out, onnx_out)
- onnx模型简化
有时候转换出来的模型有些算子可以合并,这里采用ONNX Simplifier库对转换后的模型进行简化处理。
安装完成后执行
python -m onnxsim resnet18_2class.onnx resnet18_2class_sim.onnx
打开后可以看到conv, BN层被合并,模型大小也相应变小

2、数据预处理
从python测试脚本可知,数据预处理主要包含以下几步:
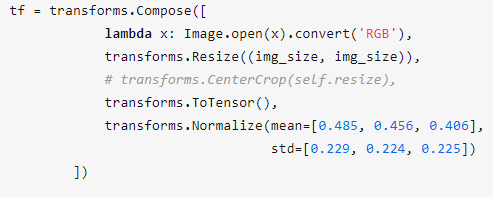
现分别将其转换成C++
- 通道转换
lambda x: Image.open(x).convert('RGB')是将图片的通道格式转换为RGB,这里我们利用OpenCV库读取图片并实现通道格式转换,注意:OpenCV读取图片后默认是BGR格式
#include "opencv2/imgproc.hpp"
#include <opencv2/highgui.hpp>
#include "opencv2/dnn/dnn.hpp"
std::string imgPath = "./test.png";
cv::Mat img = cv::imread(imgPath);
img.convertTo(img, CV_32FC3);
cv::cvtColor(img, img, cv::COLOR_BGR2RGB);
- 图片缩放
transforms.Resize((img_size, img_size))将图片缩放至指定大小,转成OpenCV的话其C++代码如下:
cv::resize(img, img, cv::Size(img_size, img_size));
- 归一化处理
transforms.ToTensor()将数据格式转换成torch张量类型,并将其值转变到[0, 1]的范围。因此这里需要对图片像素值除以255。
img = img / 255.0;
- 标准化处理
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])将输入数据减均值后在除以方差。转为C++代码如下:
std::vector<float> mean_value{ 0.485, 0.456, 0.406 };
std::vector<float> std_value{ 0.229, 0.224, 0.225 };
cv::Mat dst;
std::vector<cv::Mat> rgbChannels(3);
cv::split(img, rgbChannels);
for (auto i = 0; i < rgbChannels.size(); i++)
{
rgbChannels[i] = (rgbChannels[i] - mean_value[i]) / std_value[i];
}
cv::merge(rgbChannels, dst);
经过以上过程,图片已经预处理完成。接下来借助OpenCV的DNN模块完成推理。
3、模型推理
将输入数据转换为input,blobFromImage()接口也可以执行一些缩放、通道转换以及标准化等操作
# 加载模型
std::string modelPath = "./resnet18_2class_sim.onnx"
cv::dnn::Net net = cv::dnn::readNetFromONNX(modelPath);
std::cout << net.empty() << std::endl;
cv::Mat inputBolb = cv::dnn::blobFromImage(dst); // 也可进行缩放 通道转换 均值等操作
net.setInput(inputBolb);
cv::Mat result = net.forward();
执行forward()后会输出模型推理的结果,接下来找出最大值所在的索引即为类别。
double minValue, maxValue; // 最大值,最小值
cv::Point minIdx, maxIdx; // 最小值坐标,最大值坐标
cv::minMaxLoc(result, &minValue, &maxValue, &minIdx, &maxIdx);
std::cout << "res: " << result << std::endl;
/*std::cout << "maxValue: " << maxValue << "maxIdx: " << maxIdx.x << std::endl;
std::cout << "minValue: " << minValue << "minIdx: " << minIdx.x << std::endl;*/
classId = maxIdx.x;