产品官网:https://www.huaweicloud.com/product/hecs-light.html

今天我们采用可靠更安全、智能不卡顿、价优随心用、上手更简单、管理特省心的华为云耀云服务器L实例为例,介绍MapReduce 和 YARN(Yet Another Resource Negotiator)部署,它们是Apache Hadoop生态系统的两个关键组件,用于支持大规模分布式计算。以下是对它们的简单介绍:
MapReduce:
● 定义: MapReduce 是一种编程模型,用于处理和生成大规模数据集。它分为两个主要阶段:Map 阶段和 Reduce 阶段。
● Map 阶段: 输入数据被分割成小块,每个块由一个 Mapper 处理。Mapper 生成中间键值对(key-value pairs)作为输出,其中 key 用于分组相关的数据。
● Shuffle and Sort 阶段: 中间数据被传送到 Reduce 阶段,经过分区、排序和分组,确保具有相同 key 的数据被传递到相同的 Reduce 任务。
● Reduce 阶段: Reduce 任务处理中间数据,最终生成最终的输出。
● 应用: MapReduce 可以用于处理大规模的数据,例如在分布式存储系统(如Hadoop分布式文件系统)中运行。
YARN (Yet Another Resource Negotiator):
● 定义: YARN 是Hadoop的资源管理器,负责集群中的资源分配和作业调度。它扩展了Hadoop的能力,使得不仅可以运行MapReduce作业,还可以运行其他类型的分布式应用程序。
● 角色:
ResourceManager: 主要负责集群资源的分配和调度。
NodeManager: 在集群中的每个节点上运行,负责管理节点上的资源,接受来自 ResourceManager 的指令并执行相应的任务。
● 应用: YARN 使得 Hadoop 集群可以同时运行多个应用程序,而不仅仅是 MapReduce 作业。这使得 Hadoop 集群更加通用,可以支持多种不同类型的工作负载。
总体而言,MapReduce 和 YARN 是 Hadoop 的核心组件,它们使得处理和分析大规模数据变得更加容易和可扩展。
以下是在华为云耀云服务器L实例配置MapReduce 和 YARN步骤。请确保已经按照前文教程在服务器上配置好Hadoop。
(1)在 $HADOOP_HOME/etc/hadoop 文件夹内,添加:
```bash
export JAVA_HOME=/export/server/jdk
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
```

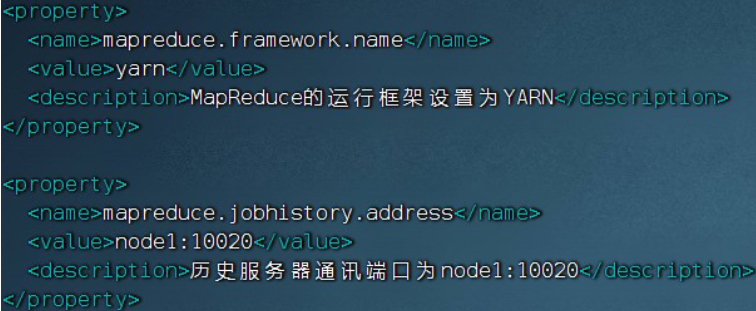
(2)mapred-site.xml文件,添加:
```bash
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
```

(3) $HADOOP_HOME/etc/hadoop 文件夹内,修改yarn-env.sh文件,添加:
```bash
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
```

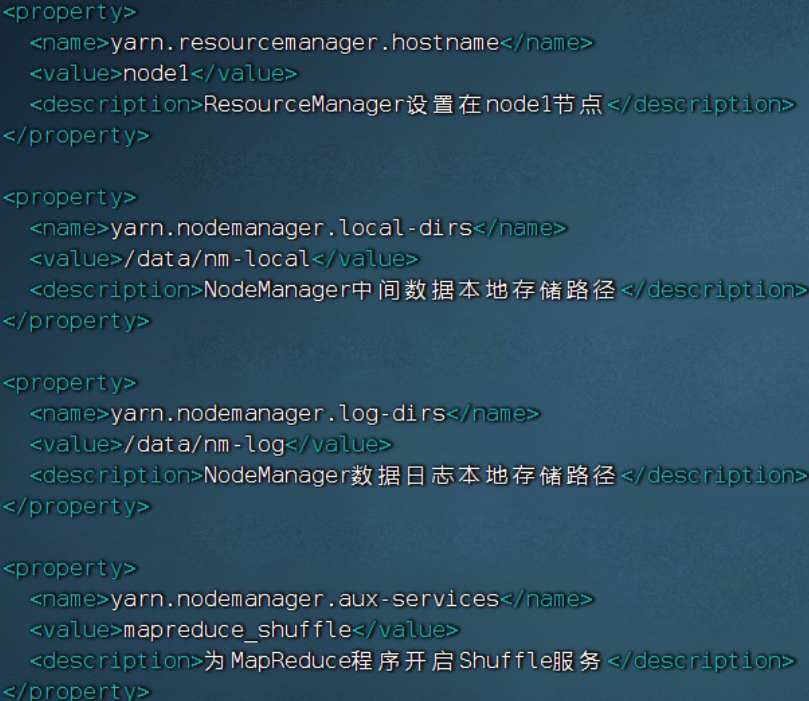
(4) $HADOOP_HOME/etc/hadoop 文件夹内,修改yarn-site.xml
```bash
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>
</configuration>
```
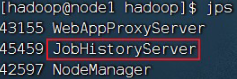
(5)执行 $HADOOP_HOME/sbin/start-yarn.sh 启动
• ResourceManager
• NodeManager
• ProxyServer

(6)执行: $HADOOP_HOME/bin/mapred --daemon start historyserver 启动 :
• HistoryServer (历史服务器)
至此,我们已经完成了在华为云耀云服务器L实例上的mapreduce和yarn的基本配置,接下来,我们将正式开始启动进程。