电力信息技术复习
前言
计算机专业开电力课,把?整乐了,花个时间速通一手?
1、大数据技术
1.1大数据技术的产生
大数据的基本概念
-
计算机技术从面向计算逐步转到面向数据的过程,即 “面向数据的计算”。
-
大数据定义:大数据是指无法在一定时间内用常规 软件工具对其内容进行抓取、管理和处理的数据集合 。
-
图灵奖获得者Jim Gray 博士指出,在科学研究方面, 人类先后历经了实验、理论、计算和数据四种范式。
-
在思维方式方面,大数据完全颠覆了传统思维方式(大数据思维):
- 全样而非抽样(要获取全部数据)
- 效率而非精确(数据多,所以精确)
- 相关而非因果(不需要去考虑因果)
-
大数据与云计算的关系
- 云计算与大数据是一对相辅相成的概念,描述了面向 计算时代信息技术的两个方面。
- 云计算侧重于描述资源和应用的网络化交付方法, 大数据侧重于描述面向数据时代由于数据量巨大所带来的 技术挑战。
- 云计算是基础设施架构,大数据是数据资产。
- 云计算与大数据是一对相辅相成的概念,描述了面向 计算时代信息技术的两个方面。
-
物联网:物联网是物物相连的互联网,是互联网的延伸,它利用局部 网络或互联网等通信技术把传感器、控制器、机器、人员和物等通 过新的方式联在一起,形成人与物、物与物相联,实现信息化和远 程管理控制。
1.2大数据的4V特征
-
多样性(Variety)
数据来源多样性。主要分为三类:结构化数据、非结构化数据、半结构化数据。
-
规模性(Volume)
-
高速性(Velocity)
增长速度和处理速度
-
价值密度低(Value)
1.3大数据的应用
1.4大数据的关键技术
- 数据处理任务包括:数据生成、数据存储、数据处理和数据应用
- 大数据存储与管理技术
- 结构化数据:数据库表等。
- 非结构化数据:图片、视频、Word、PDF等文件存储。
- 半结构化数据:XML、HTML、JSON等
- 大数据计算技术
- 批处理计算:针对大规模数据的批量处理,例如MapReduce、Spark等。
- 流计算:针对流数据的实时计算,例如Storm、S4、Flume、Streams等。
- 图计算:针对大规模图结构数据的处理,例如Pregel、GraphX、Hama等。
- 查询分析计算:大规模数据的存储管理和查询分析,例如Hive等。
1.5典型大数据计算架构
典型大数据计算架构有三个:Hadoop、Spark和Storm。
-
Hadoop是最基础的分布式计算架构,是开源计算框架,优势在于处理大规模分布式数据的能力,但算法处理非实时。
-
Spark是基于内存的大数据计算框架,提高了在大数据环境下数据处理 的实时性,Spark处理数据是准实时的。
-
Storm是基于拓扑的流数据计算框架,处理数据是完全实时。不同的机 制决定了Spark和Storm适用场景的不同
2、数据处理技术
2.1 Hadoop基础
-
Hadoop是Apache基金会旗下分布式大数据开发平台
-
Hadoop提供的功能是利用服务器集群,根据用户业务逻辑进行分布 式处理;
-
Hadoop的核心是分布式文件系统(HDFS)和分布式计算框架 (MapReduce);
-
Hadoop是Java语言开发的,具跨平台特性;
-
Hadoop被公认为行业大数据标准开源软件
-
围绕Hadoop开展的工作:开发工具、开源软件、商业化工具和技术服务
-
特性
- 高可靠性
- 高效性
- 成本低
- 高扩展性
- 支持多种编程语言
2.2 搭建Hadoop开发环境
- 部署模式选择
- 单机模式:Hadoop 默认模式,只运行在一台机器 上,无需进行其他配置即可运行。
- 伪分布式模式:在一台机器上用不同的进程模拟分布式运行中的各类节点。
- 分布式模式:使用多个节点构成集群环境来运行 Hadoop
- 分布式文件系统定义:文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连的文件系统
- 最早的分布式文件系统-NFS
2.3 HDFS
-
采用主从架构,由以下元素组成:
- 名称节点
- 数据节点
- 数据块(最小单位存储单位)
-
采用数据块的好处
- 支持大规模文件存储
- 简化系统设计
- 适合数据备份
-
名称节点的两个核心数据结构:
- FsImage
- Editlog
存在第二名称节点对这个备份
2.4 MapReduce
-
是一种编程模型,提供用户算法逻辑编写框架;
-
是一种抽象过程,将复杂的、大规模集群上的并
-
行计算任务抽象为Map和Reduce两个过程
-
Mapper产生的数据并不会直接写入磁盘,而是先存储在内存中,当内 存中的数据达到设定阈值时,再把数据写到本地磁盘 ◦
-
进行Reduce处理之前,必须等到所有的map函数做完,最终汇总所有 Reduce的输出结果即可获得最终结果 ◦
-
不同的Map任务之间不会进行信息交换 ◦
-
不同的Reduce任务之间也不会进行信息交换 ◦
-
所有的数据交换都是通过MapReduce框架自身去实现
-
对MapReduce 而言,处理单位是split。
3、大数据处理技术(2)
3.1 spark概述
-
Spark基于线程,只启动一次Java虚拟机
-
Hadoop基于进程,每次任务都会启动Java虚拟机
3.2 MLlibc
- 机器学习库MLlib,包含机器学习算法的分布式实现
- 算法包包括:
- 算法工具包
- 特征化工具包
- 流水线(Pipeline)
- 实用工具包
- 两类库函数
- spark.mllib
- spark.ml
4、大数据安全与治理
- 通过法律机制保障数据安全
5、大数据采集、清洗与规约
5.1 数据采集
-
大数据采集:在确定用户目标基础上,对传感器数据、 互联网数据、RFID数据、社交数据等进行获取的过程
-
对数据来源划分,分为三大主要来源
- 互联网数据
- 物联网数据
- 数据库数据
-
日志消息可通过通用协议syslog协议实现数据传递
-
异常值判断
例如:如果所给的数据集用20个不同的值描述年龄特征: 3, 56, 23, 39, 156, 52, 41, 22, 9,28, 139, 31, 55, 20, -67, 37, 11, 55, 45, 37 均值=39.9; 标准差=45.65 阈值=均值±(2×标准差) 所有在[-54.1, 131.2]区间以外的数据都是潜在的异常值。根据实际可 以把区间缩减到[0, 131.2],由这个标准发现3个异常值:156, 139, -67。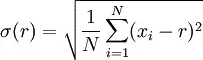
-
属性类型变换:数据概化、属性构造
6、云计算技术
-
云计算的定义
将硬件基础设施、软件系统平台等资源通过互联网 以按需使用、按量计费的方式为用户提供动态的、 高性价比的、规模可扩展的计算、存储和网络等服 务的信息技术
-
OpenStack是什么?
定义:OpenStack是一个开源的云计算管理平台,通过 数据中心控制大型的计算、存储、网络资源池,并可以 使用Web界面和API进行管理,最终为用户提供Iaas层解决方案。