哈夫曼编码
我们的任务是选一篇英语文章统计每个字符的概率,并实现哈夫曼前缀编码
所选文章内容:
life is too short to spend time with people who suck the happiness out of you if someone wants you in their life they ll make room for you You shouldnt have to fight for a spot never ever insist yourself to someone who continuously overlooks your worth and remember its not the people that stand by your side when youre at your best but the ones who stand beside you when youre at your worst that are your true friends
程序主要包括统计文章字符数组函数、哈夫曼前缀码的实现
//全部代码
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
struct Node {
int weight;//权重
int parent, lchild, rchild; //游标
char code;
};
class HuffmanTree {
private:
Node* huffman;//定义结构体指针
int num;
void Select(int n, int &i1, int &i2);
public:
HuffmanTree(int w[], int n);//构造函数,传入的数组是文章每个字母的权值,n是字母个数
// ~HuffmanTree();
void Print();//输出函数
void Encode(int i);//解码函数
void Codeing();//编码函数
};
//构造函数
HuffmanTree::HuffmanTree(int w[], int n) {
int i, k, i1, i2;
huffman = new Node [2 * n - 1];//开辟一个长度为2*n-1的结构体数组
num = n;
for ( i = 0; i < 2 * num - 1; i++) {//初始化权值的游标
huffman[i].parent = -1;
huffman[i].lchild = -1;
huffman[i].rchild = -1;
}
for ( i = 0; i < num; i++) {//赋初始值
huffman[i].weight = w[i];
}
for (k = num; k < 2 * num - 1; k++) {
Select(k, i1, i2);//调用select函数,遍历每个权值数据
huffman[k].weight = huffman[i1].weight + huffman[i2].weight;
huffman[i1].code = '0';huffman[i2].code = '1';
huffman[i1].parent = k;huffman[i2].parent = k;
huffman[k].lchild = i1;huffman[k].rchild = i2;
}
}
//筛选函数
void HuffmanTree::Select(int n, int &i1, int &i2) {
int i = 0, temp;
for (; i < n; i++) { //遍历每个权值
if (huffman[i].parent == -1) {
i1 = i;break;
}
}
for ( i = i + 1; i < n; i++) {
if (huffman[i].parent == -1) {
i2 = i;break;
}
}
if (huffman[i1].weight > huffman[i2].weight) {
//如果发现i1>i2就换掉换
temp = i1;i1 = i2;i2 = temp;
}
for ( i = i + 1; i < n; i++) {
if (huffman[i].parent == -1) {
if (huffman[i].weight < huffman[i1].weight) {
i2 = i1;i1 = i;
} else if (huffman[i].weight < huffman[i2].weight) {
i2 = i;
}
}
}
}
//输出函数
void HuffmanTree::Print() {
int i, k;
cout << "每个叶子到根结点的路径是:" << endl;
for ( i = 0; i < num; i++) {
cout << huffman[i].weight;
k = huffman[i].parent;
while (k != -1) {
cout << "-->" << huffman[k].weight;
k = huffman[k].parent;
}
cout << endl;
}
}
//解码函数
void HuffmanTree::Encode(int i) {
if (huffman[i].parent == -1) {
return;
} else {
Encode(huffman[i].parent);
}
cout << huffman[i].code;
}
//编码函数
void HuffmanTree::Codeing() {
for (int i = 0; i < num; i++) {
if (huffman[i].lchild == -1 && huffman[i].rchild == -1) {
Encode(i);cout<<" ";
}
}
}
//统计字符频率的函数(外部函数)
void Statistic(string ch, int weight[]) {
//用来统计字符出现的次数,你也可以认为是权值的集合。i表示对应的元素,sum[i]表示对应元素出现的次数
int sum[26];
for (int i = 0; i < 26; i++) {
sum[i] = 0; //将数组元素置0
}
for (int i = 0; i < ch.length(); i++) {
if ((ch[i] >= 'a') && (ch[i] <= 'z')) {
sum[ch[i] - 'a']++;
}
}
char a = 'a';
for (int i = 0; i < 26; i++) {
cout << a << " : " << sum[i] << " ";
a++;
weight[i] = sum[i];
}
}
int main() {
ifstream fin;
fin.open("document.txt", ios::in);
if (!fin.is_open()) {
cout << "无法找到这个文件!";
return 0;
}
string buf;
cout << "结果:" << endl;
int weight[26];
int i = 0;
while (getline(fin, buf)) {
Statistic(buf, weight);
}
cout<<endl;
HuffmanTree h(weight, 26);
cout<<"编码结果为:"<<endl;
h.Codeing();
cout<<endl;
h.Print();
return 0;
}
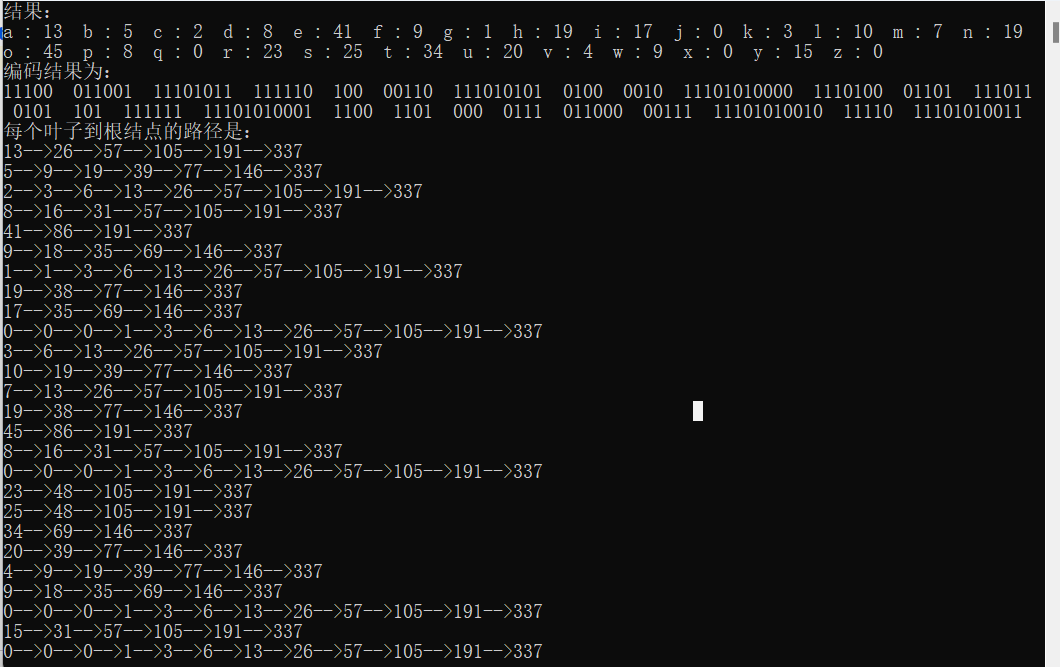
结果: