2023数据采集与融合技术实践作业4
作业1
要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
▪使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
o 候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
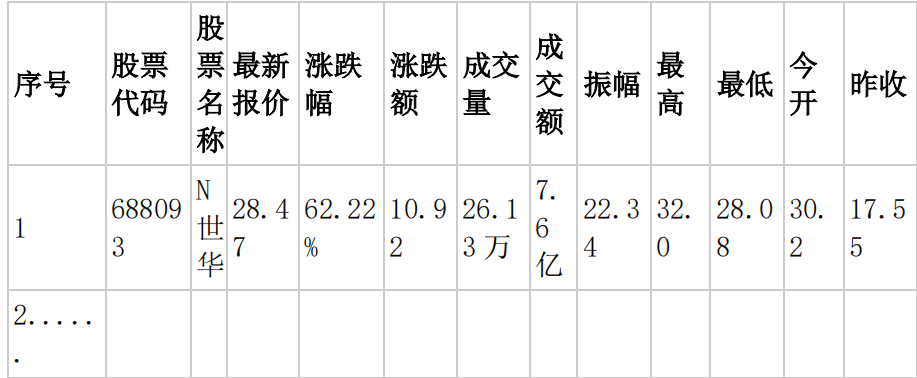
o 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
• Gitee 文件夹链接
(1)代码
整体代码逻辑
spider=Spiders()
urls=["http://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"http://quote.eastmoney.com/center/gridlist.html#nav_sh_a_board",
"http://quote.eastmoney.com/center/gridlist.html#nav_sz_a_board"]
for url in urls:
spider.init(url)
spider.processSpider()
spider.closeUp()
创建一个 WebDriver 实例
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
self.driver = webdriver.Chrome(options=chrome_options)
通过XPATH定位元素:
def processSpider(self):
trs = self.driver.find_elements(By.XPATH,"//table[@id='table_wrapper-table']/tbody/tr")
for tr in trs:
id = tr.find_element(By.XPATH,".//td[1]").text
StockNo = tr.find_element(By.XPATH,"./td[2]/a").text
StockName= tr.find_element(By.XPATH,"./td[3]/a").text
StockQuote = tr.find_element(By.XPATH,"./td[5]/span").text
Changerate = tr.find_element(By.XPATH,"./td[6]/span").text
Chg = tr.find_element(By.XPATH,"./td[7]/span").text
Volume = tr.find_element(By.XPATH,"./td[8]").text
Turnover = tr.find_element(By.XPATH,"./td[9]").text
StockAmplitude = tr.find_element(By.XPATH,"./td[10]").text
highest = tr.find_element(By.XPATH,"./td[11]/span").text
lowest = tr.find_element(By.XPATH,"./td[12]/span").text
Pricetoday = tr.find_element(By.XPATH,"./td[13]/span").text
PrevClose = tr.find_element(By.XPATH,"./td[14]").text
实现翻页
if self.page_num < 3:
self.page_num += 1
nextPage = self.driver.find_element(By.XPATH,"//div[@class='dataTables_paginate paging_input']/a[2]")
nextPage.click()
time.sleep(4)
#递归爬取
self.processSpider()
数据库操作
#初始化
def init(self, url):
# 爬取页数
self.pagenum = 0
#板块的名称
self.board=["沪深京A股票","上证A股","深证A股"]
self.driver.get(url)
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="....", db="spiders", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
for table_name in self.board:
self.cursor.execute(f"DROP TABLE IF EXISTS {table_name}")
self.cursor.execute(f"CREATE TABLE {table_name}(id INT(4) PRIMARY KEY, StockNo VARCHAR(16), StockName VARCHAR(32), StockQuote VARCHAR(32), Changerate VARCHAR(32), Chg VARCHAR(32), Volume VARCHAR(32), Turnover VARCHAR(32), StockAmplitude VARCHAR(32), Highest VARCHAR(32), Lowest VARCHAR(32), Pricetoday VARCHAR(32), PrevClose VARCHAR(32))")
except Exception as err :
print(err)
#插入数据
def insertDB(self,board,id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose):
try:
sql = f"insert into {board}(id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose))
except Exception as err:
print(err)
#关闭
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
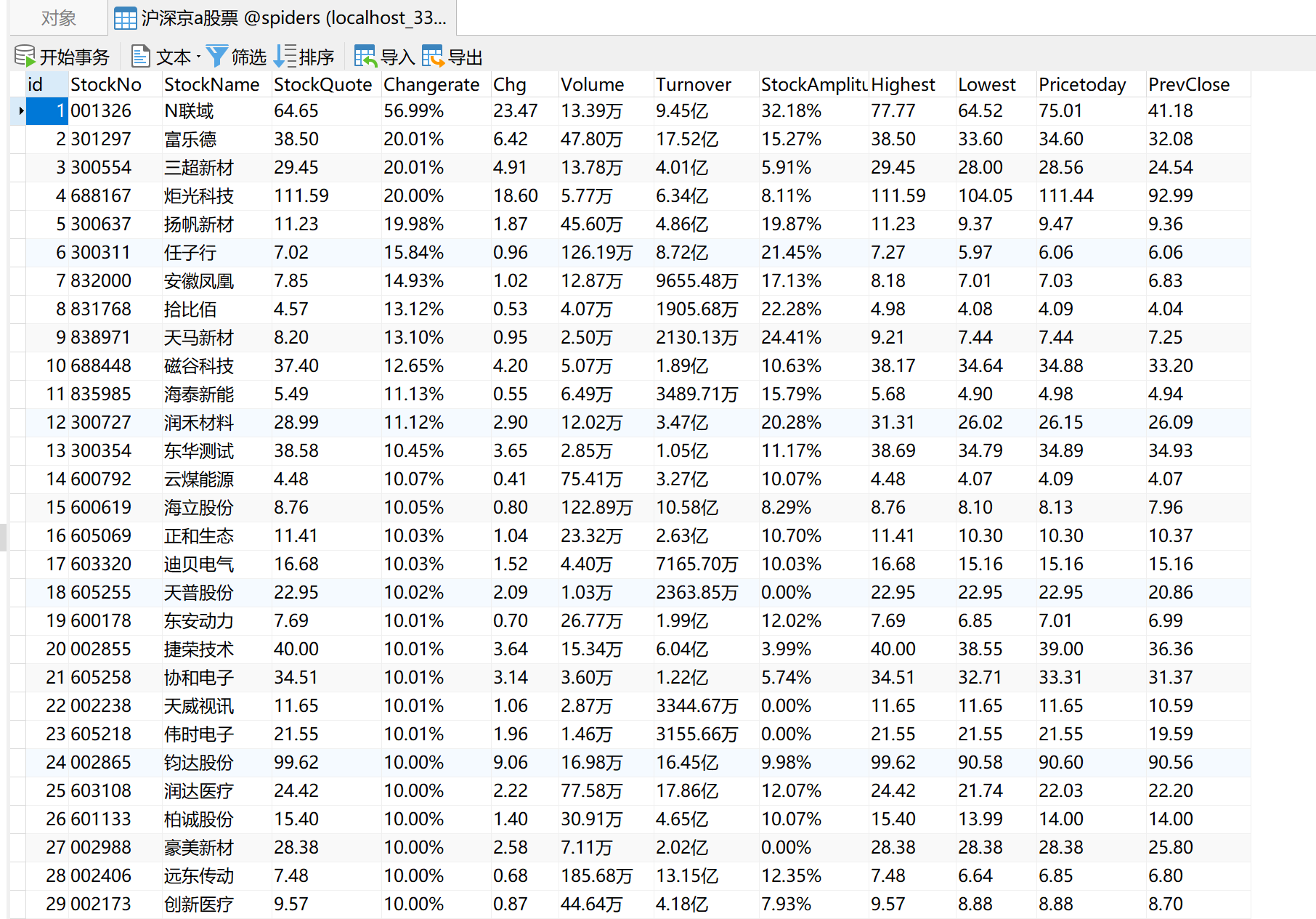
查看数据库
(2)心得
1、google自动更新,导致原来下载的驱动器不能使用,于是下载对应版本的,再上网搜索取消谷歌浏览器自动更新

2、不同板块的url后缀不一样,于是可以修改后缀来实现不同板块的切换
3、爬取多页时要注意翻页的速度和爬取的页数,一般翻页时会设置休眠时间,来模拟人的翻页行为。
作业2
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国 mooc 网:https://www.icourse163.org
o 输出信息:MYSQL 数据库存储和输出格式

• Gitee 文件夹链接
(1)代码
先切换到登录界面所在的iframe中才可以输入账号密码
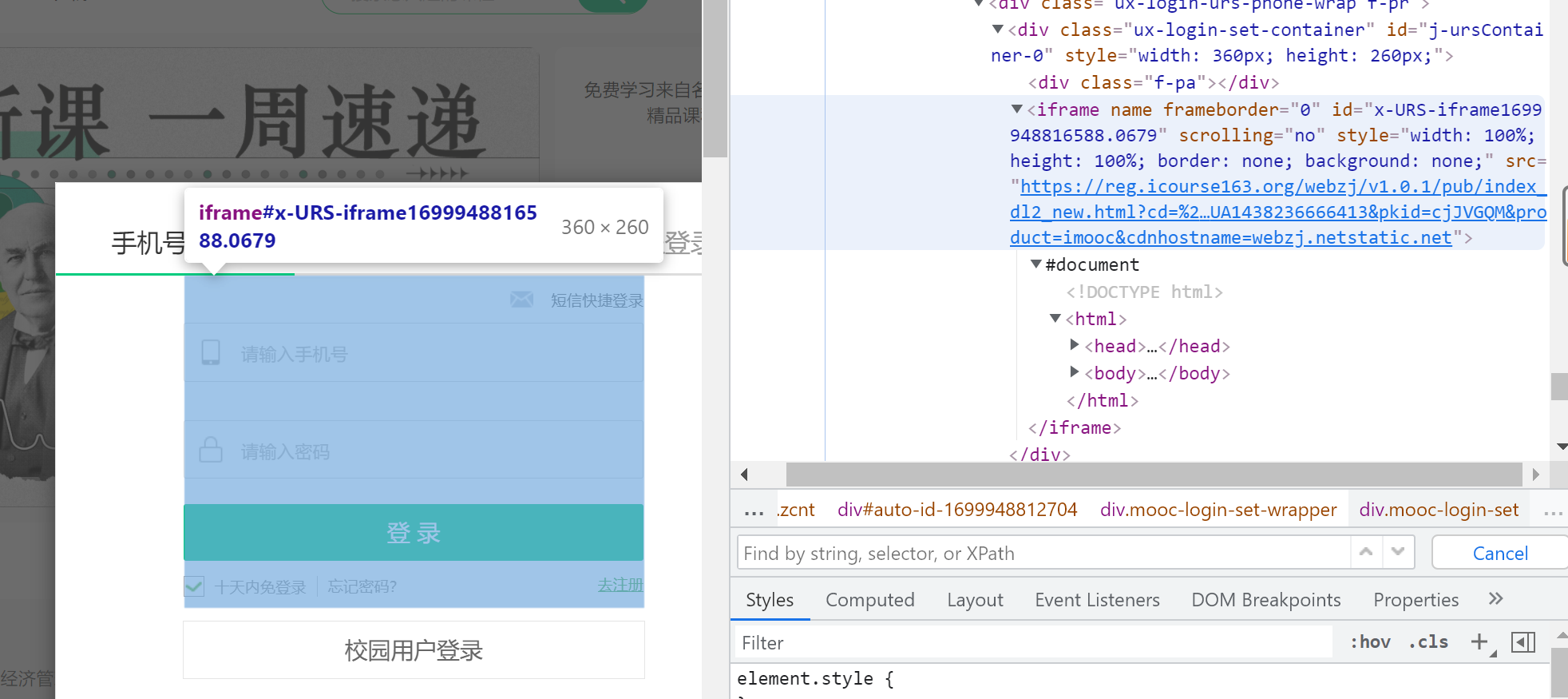
定位按键元素,输入账号密码信息实现自动登录
from selenium.webdriver.support import expected_conditions as EC
#等待登录元素加载好再执行操作
WebDriverWait(driver, 10, 0.5).until(
EC.presence_of_element_located((By.XPATH, '//a[@class="f-f0 navLoginBtn"]'))).click()
iframe = WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.XPATH, '//*[@frameborder="0"]')))
#切换到登录界面中
driver.switch_to.frame(iframe)
# 输入账号密码
driver.find_element(By.XPATH, '//*[@id="phoneipt"]').send_keys("*****")
time.sleep(3)
driver.find_element(By.XPATH, '//*[@class="j-inputtext dlemail"]').send_keys("*****")
time.sleep(3)
#点击登录按钮
driver.find_element(By.ID, 'submitBtn').click()
解析数据
courses = self.driver.find_elements_by_xpath("//div[@class='m-course-list']//div[@class='u-clist f-bgw f-cb f-pr j-href ga-click']")
for course in courses:
name = course.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']//a//span").text
college = course.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']//a[@class='t21 f-fc9']").text
teacher = course.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']//a[@class='f-fc9']").text
teacher1 = teacher
teachers= course.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0']//span[@class='f-fc9']").text
team = teacher1 + teachers
participants = course.find_element_by_xpath(".//div[@class='t2 f-fc3 f-nowrp f-f0 margin-top0']//span[@class='hot']").text
url = course.find_element_by_xpath(".//div[@class='t1 f-f0 f-cb first-row']//a").get_attribute("href")
time.sleep(3)
定位详情页数据
#实例化另一个driver来爬取详情页
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver2 = webdriver.Chrome(chrome_options=chrome_options)
driver2.get(url)
time.sleep(2)
实现翻页,爬取三页
if self.page_num < 3:
self.page_num += 1
nextPage = self.driver.find_element(By.XPATH,"//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-main-gh']")
nextPage.click()
time.sleep(4)
#递归爬取
self.processSpider()
数据库操作
#初始化
def init(self, url):
try:
db = pymysql.connect(host='127.0.0.1', user='root', password='....', port=3306, database='spiders')
cursor = db.cursor()
cursor.execute('DROP TABLE IF EXISTS mooc')
sql = '''CREATE TABLE mooc(cCourse varchar(64),cCollege varchar(64),cTeacher varchar(16),cTeam varchar(256),cCount varchar(16),
cProcess varchar(32),cBrief varchar(2048))'''
cursor.execute(sql)
except Exception as e:
print(e)
#插入数据
def insertDB(self,cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief):
try:
cursor.execute('INSERT INTO mooc VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (
cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
except Exception as e:
print(e)
#关闭
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
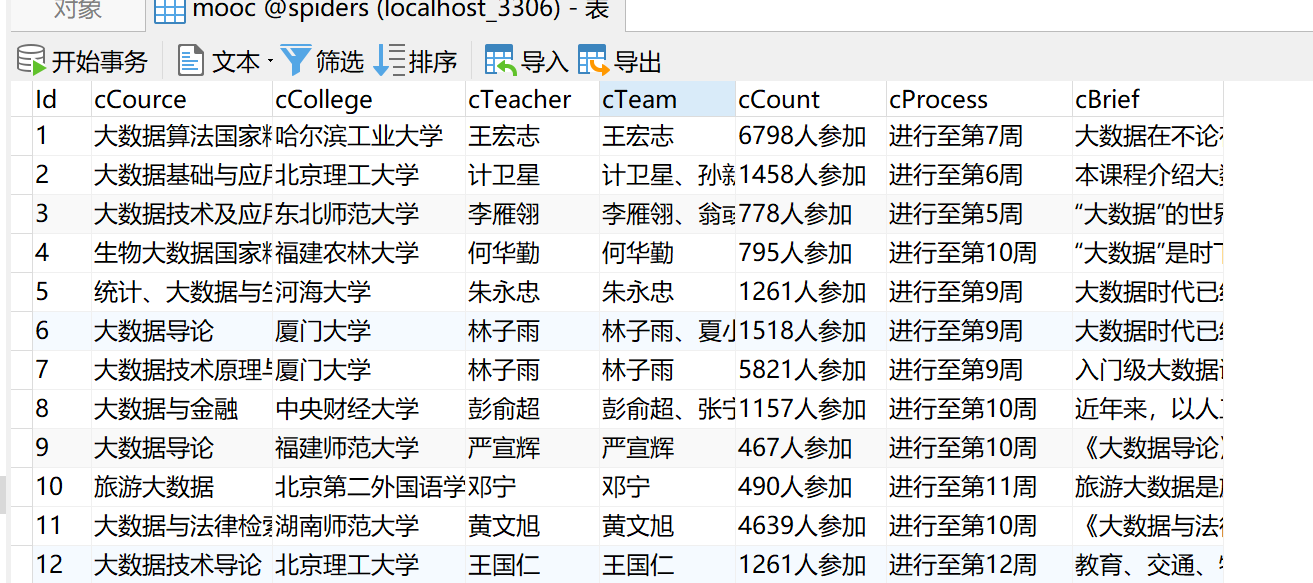
查看数据库
(2)心得
(1)一开始没注意到弹出的登录界面在iframe里,这是一个网页嵌套,于是之间复制的xpath路径定位不到输入框,需要切换到iframe中就可以,若有多个iframe可以根据id、class等定位不同的iframe。
(2)切换到iframe后,点击登录按钮还是没有反应,想想老师说过的,得等到页面中的元素加载好了之后才可以定位到元素,于是加了WebDriverWait,在等待登录的按钮出现后执行相应的操作,确保页面加载完成并且元素可见后再进行后续操作。
(3)登录成功后要切换回原来的主界面,因为信息都还是在原来界面中,不在iframe中,在爬取详情页时开了另一个driver来提高爬取效率。
(4)慕课网页和之前爬取的普通页面都不一样,学到了很多。
作业3
要求:
掌握大数据相关服务,熟悉 Xshell 的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建:
任务一:开通 MapReduce 服务
实时分析开发实战:
任务一:Python 脚本生成测试数据
任务二:配置 Kafka
任务三: 安装 Flume 客户端
任务四:配置 Flume 采集数据
输出:实验关键步骤或结果截图。
(1)代码
1.1Python脚本生成测试数据
使用Xshell 7连接服务器,进入/opt/client/目录,用xftp7将本地的autodatapython.py文件上传至服务器/opt/client/目录下。
创建目录,使用mkdir命令在/tmp下创建目录flume_spooldir,我们把Python脚本模拟生成的数据放到此目录下,后面Flume就监控这个文件下的目录,以读取数据。
执行Python命令,测试生成100条数据并查看数据

1.2配置Kafka
步骤1首先设置环境变量,执行source命令,使变量生效
步骤2在kafka中创建topic(注意更换为自己Zookeeper的ip,端口号一般不动)

步骤3查看topic信息

1.3安装Flume客户端
进入MRS Manager集群管理界面,打开服务管理,点击flume,进入Flume服务,点击下载客户端

解压下载的flume客户端文件,校验文件包,安装Flume客户端
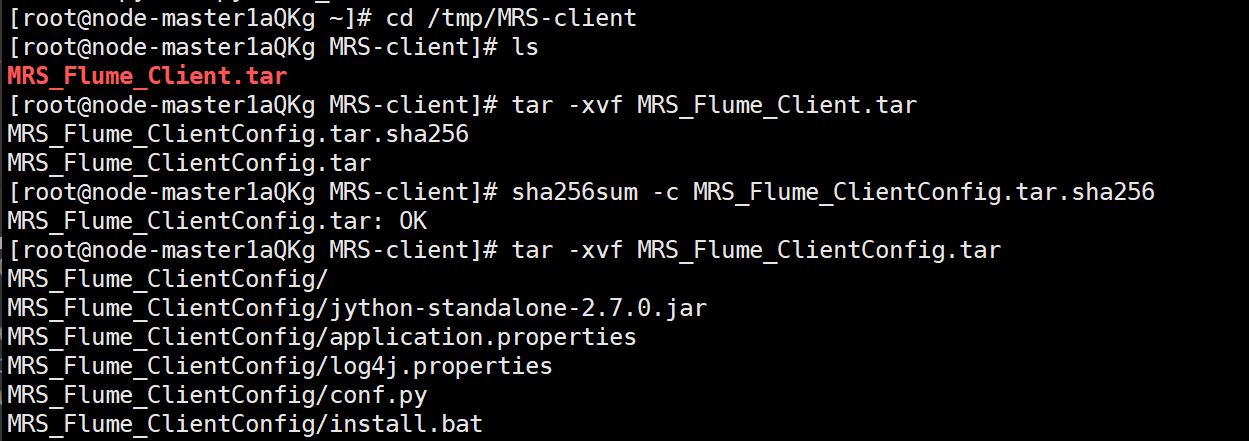

1.4配置Flume采集数据
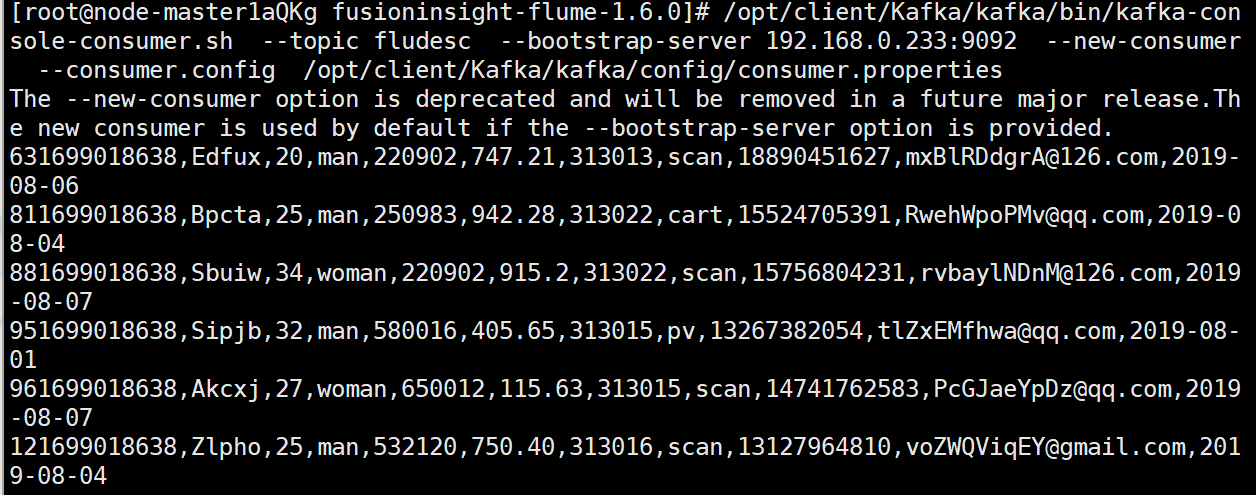
修改配置文件,创建消费者消费kafka中的数据。

执行完毕后,在新开一个Xshell 7窗口(右键相应会话-->在右选项卡组中打开),执行2.2.1步骤三的Python脚本命令,再生成一份数据,查看Kafka中是否有数据产生:

(2)心得
1、申请服务器时要认真配置服务器,尽快做实验并及时释放资源避免产生过多额外费用,毕竟资源有效
2、实验内容是跟着实验书一步一步做的,还算顺利,了解了Python脚本生成测试数据、配置Kafka、安装Flume客户端、配置Flume采集数据这四个过程。