今天给大家分享如何在矩池云服务器使用 Llama2-7b模型。
硬件要求
矩池云已经配置好了 Llama 2 Web UI 环境,显存需要大于 8G,可以选择 A4000、P100、3090 以及更高配置的等显卡。
租用机器
在矩池云主机市场:https://matpool.com/host-market/gpu ,选择显存大于 8G 的机器,比如 A4000 显卡,然后点击租用按钮(选择其他满足显存要求的显卡也行)。
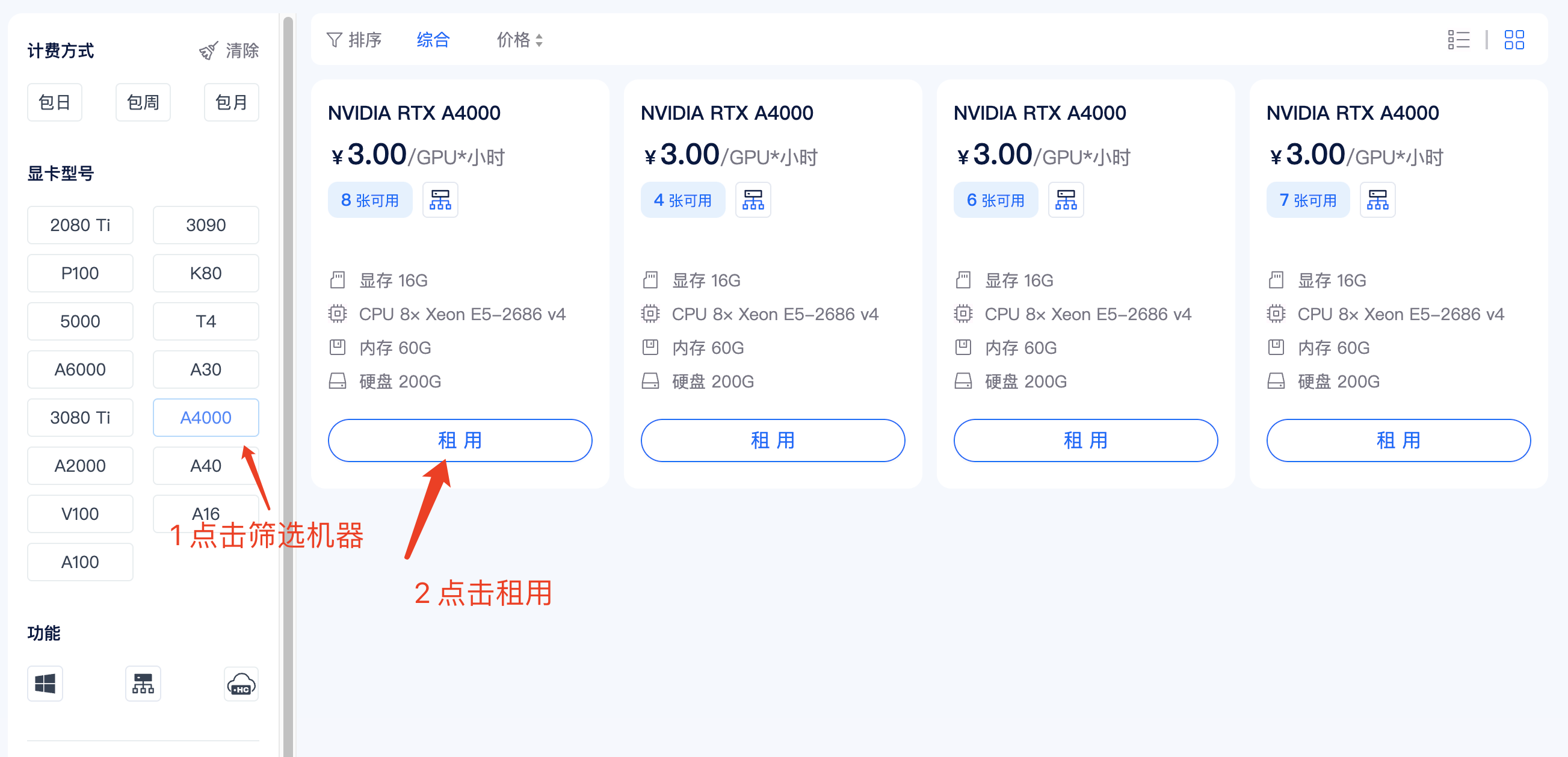
租用页面,搜索 Llama 2 Web UI,并选择该镜像,再 点击租用即可。
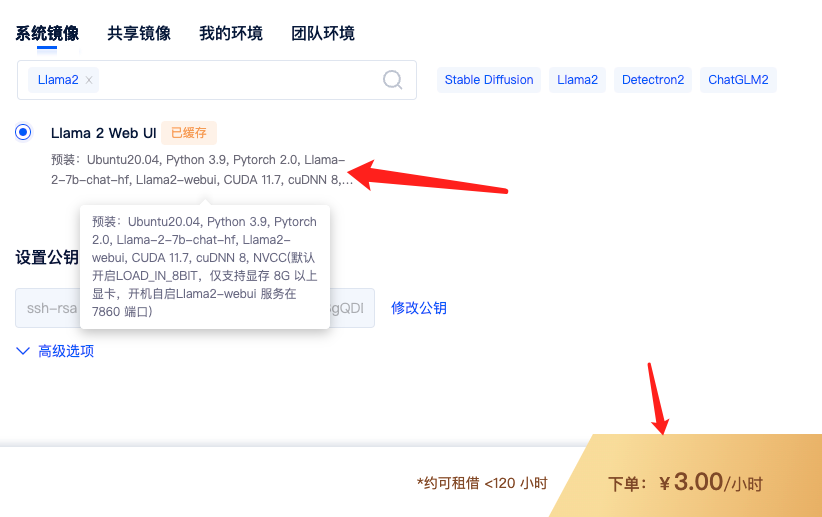
预装:Ubuntu20.04, Python 3.9, Pytorch 2.0, Llama-2-7b-chat-hf, Llama2-webui, CUDA 11.7, cuDNN 8, NVCC(默认开启 LOAD_IN_8BIT,仅支持显存 8G 以上显卡,开机自启Llama2-webui 服务在 7860 端口)
Llama2-webui 来自开源项目:https://github.com/liltom-eth/llama2-webui
机器租用成功后,可以看到 7860 端口的对应链接,这是 Llama2-webui 默认的端口,镜像已经设置了开机自启,也就是说你现在可以直接访问这个链接,开始使用 Llama2-7B啦。

使用 Llama2-webui
点击租用页面中的 7860 端口对应链接即可访问相关服务。
在页面中的Advanced options中我们可以进行一些设置,比如:系统角色、回复内容的最长长度等。
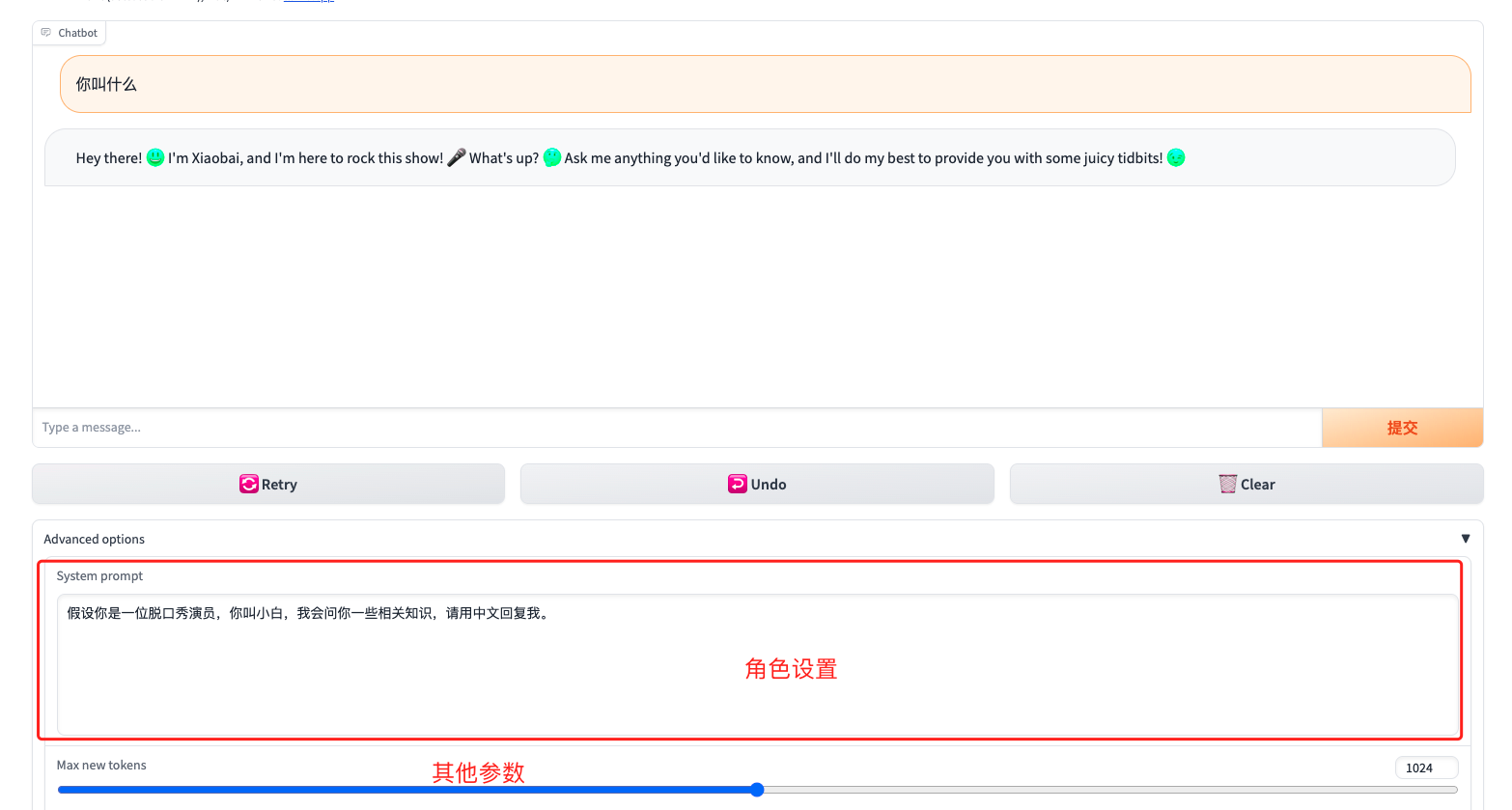
在上面的问题中我们可以发现,即使给他设置了中文回复,但回复结果仍然用的英文,另外他确实理解了我的问题,并接受了设置的角色。
关闭 LOAD_IN_8BIT,推理更快
这个镜像自启服务中默认开启了 LOAD_IN_8BIT ,这样可以使推理时占用更少的显存,但也会花费更长的时间,所以,如果你租用的是 13G 以上显存机器,可以按以下方法关闭 LOAD_IN_8BIT 重新运行服务,以获得更快的推理速度。
点击租用页面:JupyterLab 链接。
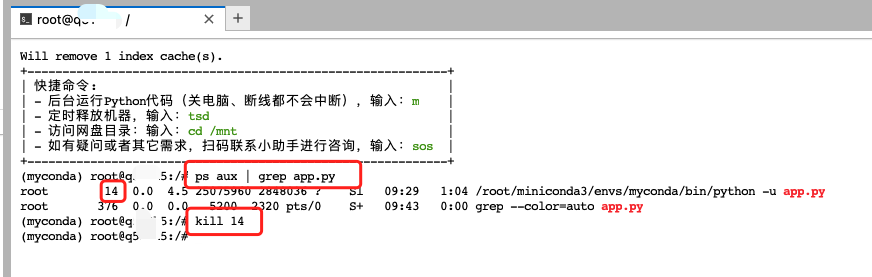
新建一个 terminal,输入ps aux | grep app.py查看相关服务进程id,并使用kill指令结束进程。
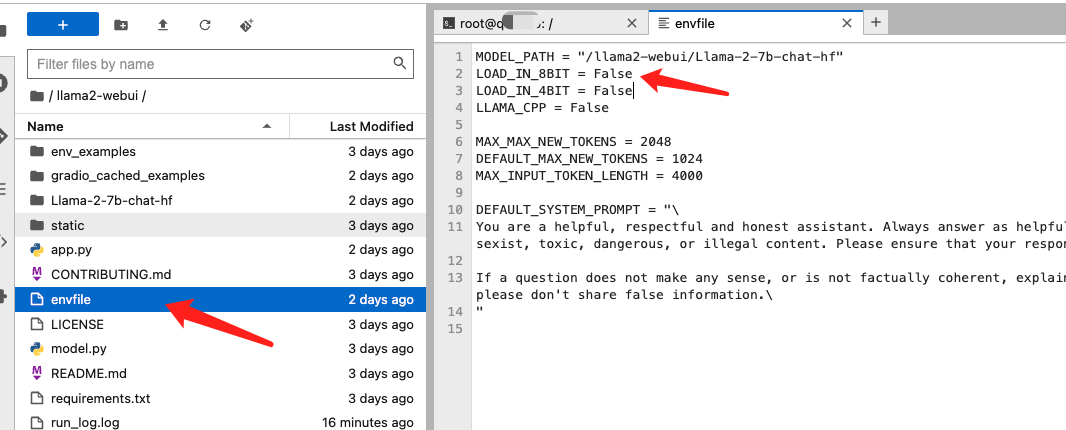
JupyterLab 左侧目录导航栏打开llama2-webui项目文件夹下的envfile文件,将里面的LOAD_IN_8BIT = True改成LOAD_IN_8BIT = False,然后按 ctrl+s 保存文件。
回到 terminal,输入以下指令重新启动 Llama2-webui 服务。
cd /llama2-webui/
nohup python -u app.py > /llama2-webui/run_log.log 2>&1 &
# 查看程序运行日志
tail -f run_log.log
等模型加载完成,即可再次访问租用页面 7860 端口连接,使用服务了。

中文迭代效果依然有限,不过迭代速度和效果好了不少。
