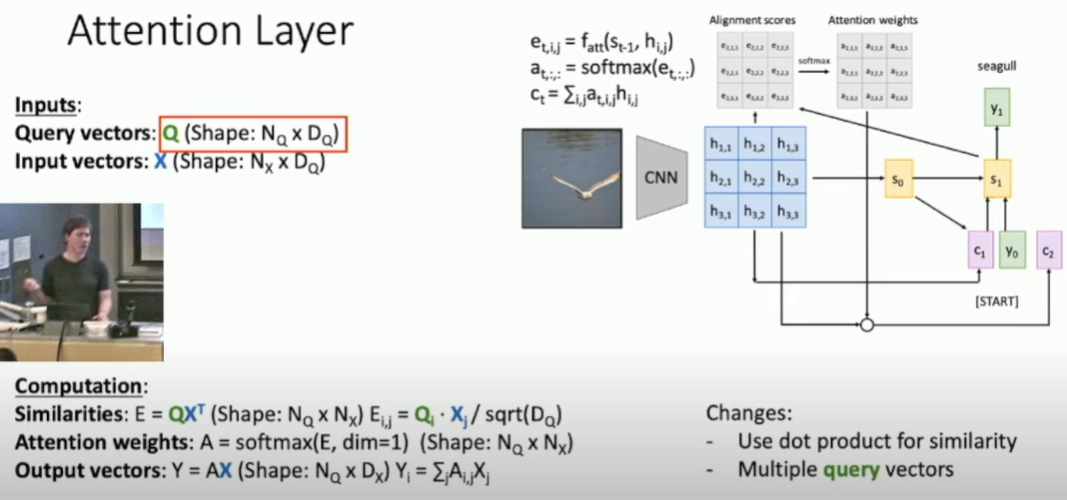
attention层计算过程:
相似度函数fatt计算输入X和查询向量q之间的相似度e;
相似度e经过softmax计算得到权重 a。 向量e和a的长度与输入X的第一个维度相同。
权重a与输入X相乘,得到输出y。

相似度计算可使用 点积dot prodecut,由于输入X的维度通常较高,q.X值会很大,因此使用sqrt(Dq)进行normailize,Dq是数据的长度。

query vector查询向量可以有多个,即类似下图右部分有多个s0, s1, ...。 这样可以使用矩阵运算 加快计算速度,
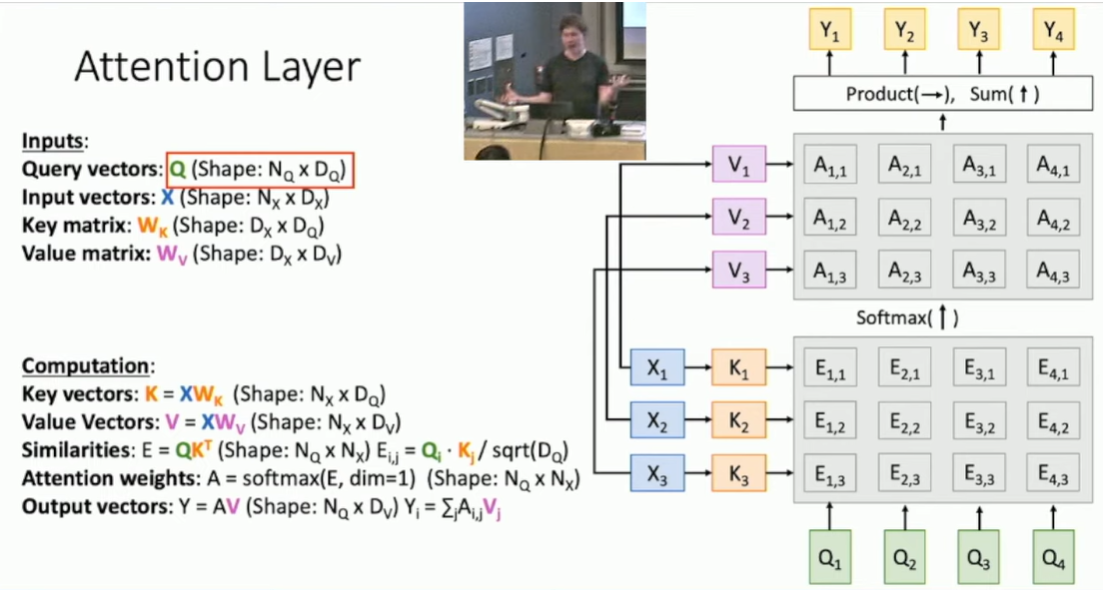
输入X的2种使用方式:1. 计算注意力相似度 每个x与每个q相乘。 2. 计算输出Y,输入x与注意力权重a相乘。上述两个过程由两个function进行计算。
使用的是同一个输入X,可以将上述过程分隔开,分别增加两个可以学习的参数矩阵Wk、Wv,将输入X转成2个不同的矩阵,K=XWk, V=XWv。好处是可以让模型更加flexibility自由的使用其输入数据X,attention layer层的输出Y和计算相似度时的过程更加独立。
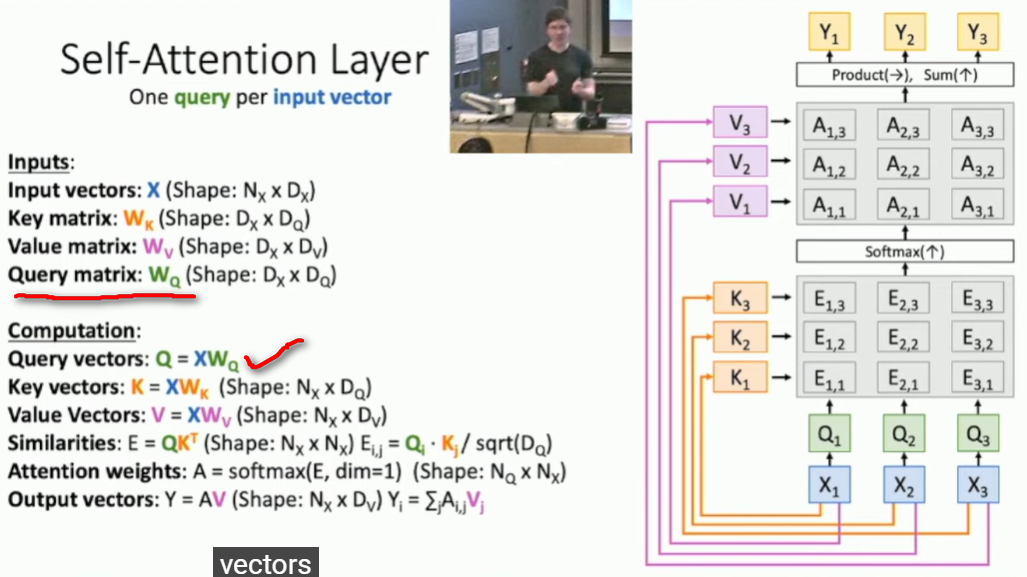
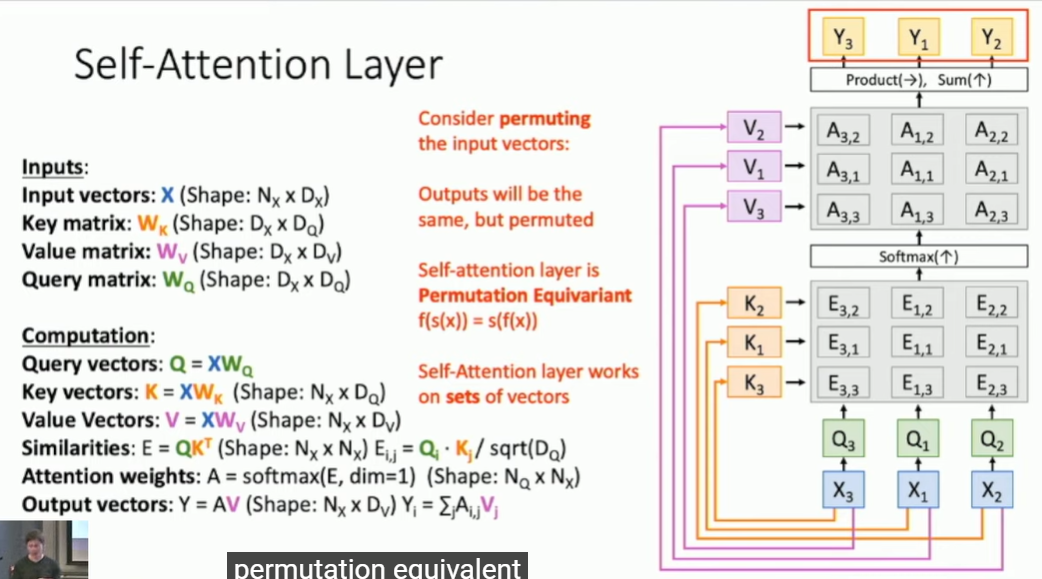
自注意力层self-attention-layer:输入X中各向量xi与其他部分xj的关系。与上图相比 标红的部分是多出来的,即增加了query matrix查询权重矩阵Wq( 同样需要训练更新)。正常注意力层中(上图) query matrix Q是给定的,自注意力层的Q是通过输入X得到的。
self-attention-layer对输入X的顺序不敏感,即改变X1 X2 X3的顺序 并不影响相应Y的值。 self attention layer is doing that you get a set of vectors it compares them all with each other and then gives you another set of vectors, and dosenot know what order of the input X
Masked self-attention layer:比如只想让当前输入xi看到过去的输入x1..xi,不能看到未来的输入xi+1...。 下图中Eij是Qi 与 Kj的乘积。每一行是Ki计算得到的,每一列是Qj计算得到的。E12与Q2有关,E13与Q3有关,将E12、E13进行mask掩盖,这样输入Q1就无法看到Q2 Q3的信息了。

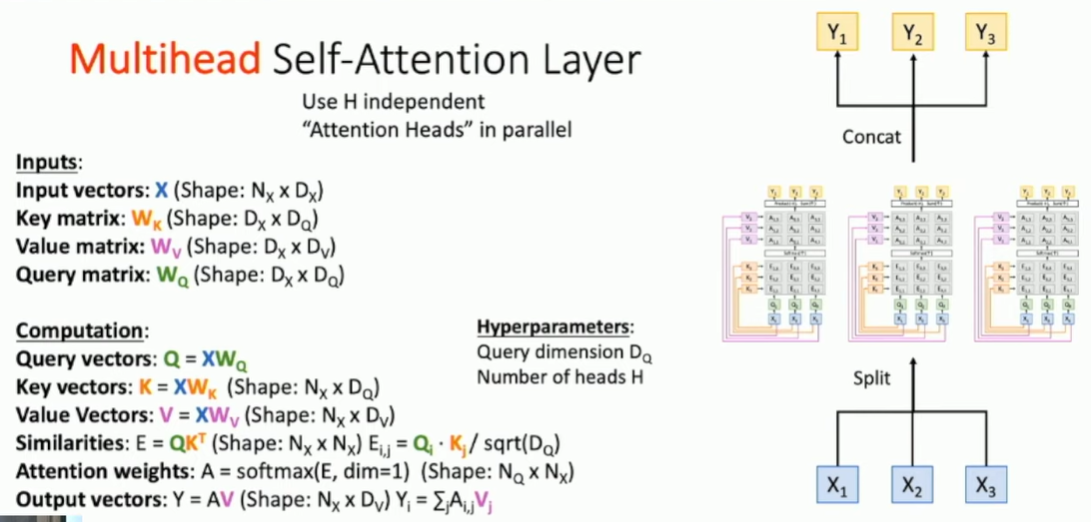
多头注意力层:两个超参数 query matrix的维度Dq,heads的个数H。
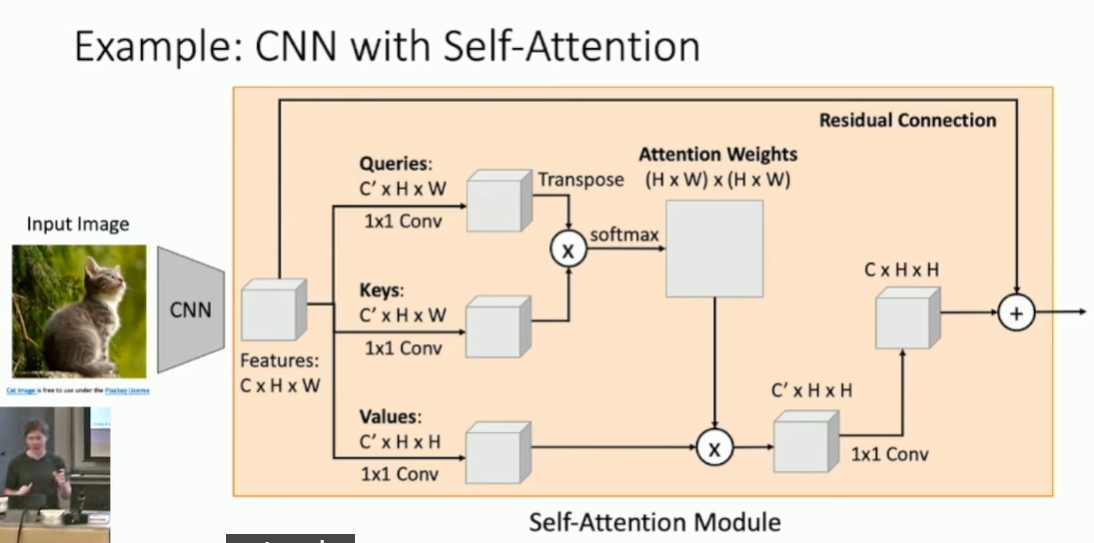
self-attention计算示例:attention weights: 图像中每个位置ij,与其他位置的关联程度或者叫attention程度。然后将其与 Values矩阵做运算。
RNN、1D卷积、self-attention三种序列处理方法的对比:

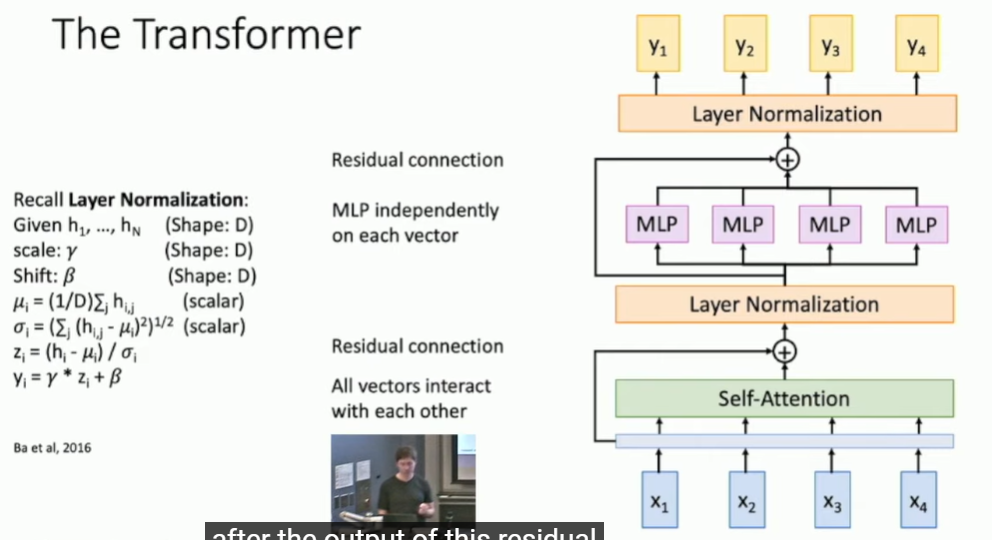
Transformer架构:
transformer block如下图:layer normalization层独立normalize每个vector,不会对self-attention层输出的vectors做任何interaction处理。