Linux图形驱动与图形调度分析
Linux图形驱动
Linux图形堆栈在过去几年中经历了许多演变。本节的目的是详细说明这段历史,并给出多年来所做更改背后的理由。今天,设计仍然深深植根于这段历史,本节将解释这段历史,以更好地推动Linux图形堆栈的当前设计。下面简述Linux图形驱动架构涉及的各个模块或概念:
- PCI (Peripheral Component Interconnect):用户需要将图形卡插入主板上的PCI插槽。PCI规范不能免费向公众提供,此计算机总线的编程入口点是PCI配置空间,是通过x86体系结构I/O端口地址空间中的0xCF8和0xCFC I/O端口访问的。更具体地说,0xCF8是地址端口,0xCFC是数据端口。每个PCI实体(总线上的最小可寻址单元,如内存中的字节)有自己的配置空间。实体的配置空间中将有3种类型的资源:
- 输入/输出内存。这是实体解码的物理内存块。签出/proc/iomem的内容。
- 输入/输出端口。将由实体解码的I/O端口空间中的数据。签出/proc/ioports文件的内容。
- IRQ(中断请求)。签出/proc/irq目录的内容。
此类资源的配置使用2个系统完成:
- PCI PNP(即插即用)已过时。
- ACPI(高级配置和电源接口),目前实现的方法,是一项由OS(操作系统)内核完成的任务。
- AGP (Accelerated Graphic Port)、PCI Express card:系统将看到插入AGP插槽或PCI Express插槽的图形卡,就像PCI设备一样。
- ACPI (Advanced Configuration and Power Interface):如今的计算机通常具有ACPI功能,ACPI取代PCI PNP用于实体配置,并为该批次添加电源管理、多处理器sweet和其他内容。与PCI不同,ACPI规范是免费提供的。ACPI基于内存表:在计算机启动时,操作系统必须在物理内存中找到RSDP(根系统描述指针)。在x86体系结构上,需要在特定的物理内存区域中查找“RSD PTR”字符串。
- XORG、DDX (Device Dependent X)和DIX (Device Independent X):XORG是X Window系统客户端libs和服务器的一部分、整个项目的参考实现,需要了解X Window核心协议。请记住,XORG有多个服务器,如DMX(分布式多头X)服务器、kdrive服务器或著名的XGL服务器。DIX是XORG的一部分,负责处理客户端、网络透明度和软件渲染。DDX是XORG处理硬件(以及在一定程度上处理操作系统)的一部分。
- EXA:EXA是XORG加速的API,xfree86 DDX是唯一实现它的DDX。每次初始化屏幕时(例如,在新服务器生成开始时),都会初始化EXA加速(如果启用)。
- DRI (Direct Rendering Infrastructure) 和DRM (Direct Rendering Manager):DRI和DRM是图形卡硬件编程的管道,主要由mesa(即“libre”opengl实现)使用,但由于对硬件的访问必须在所有图形卡硬件客户端之间同步,xfree86 DDX视频驱动模块必须处理它,因为它本身就是这样的客户端。然后,EXA当想要执行加速操作时,必须与硬件进行DRI对话。有一个用于xfree86 DDX代码的DRI xfree86 DDX模块,希望通过DRI方式进行硬件访问。此模块和相关的xfree86 DDX代码将使用DRM用户级接口库libdrm。理论上,未来的DRM演进将允许我们摆脱XORG服务器的PCI编程代码。

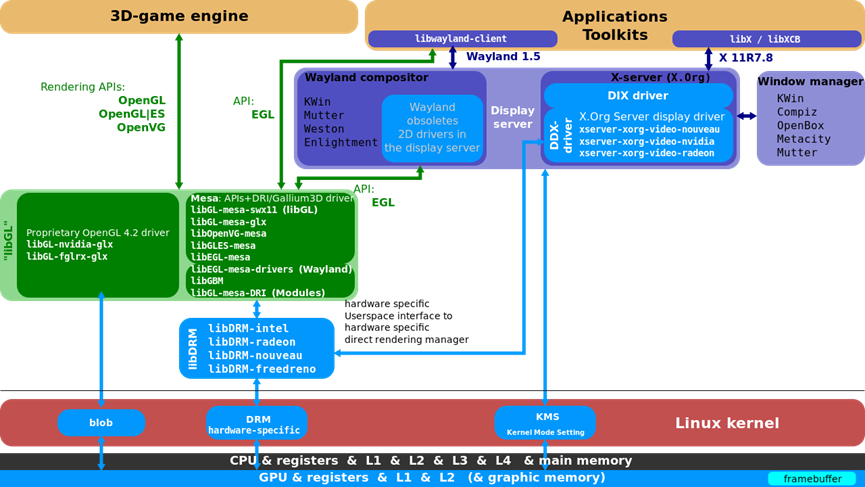
1 X11基础架构
X11架构图如下,包含DIX(设备无关X)、DDX(设备相关X)、Xlib、套接字、X协议、X扩展,shm->用于传输的共享内存,XCB->异步等。
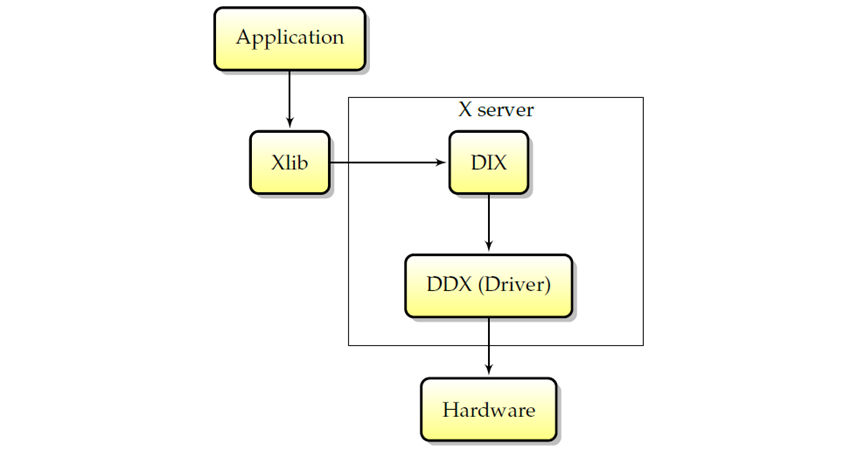
X服务的内部交互图如下:
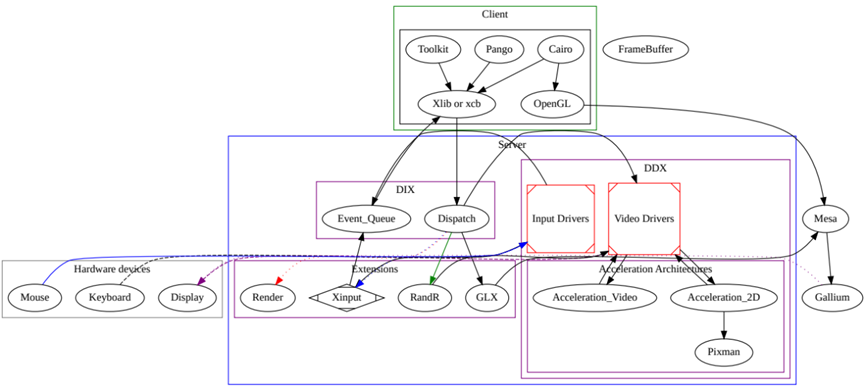
2 DRI/DRM基础架构
直接渲染管理器(DRM)是Linux内核的一个子系统,负责与现代视频卡的GPU接口。DRM公开了一个API,用户空间程序可以使用该API向GPU发送命令和数据,并执行诸如配置显示器的模式设置等操作。DRM最初是作为X Server直接渲染基础设施的核心空间组件开发的,但从那时起,它已被其他图形堆栈替代品(如Wayland)使用。
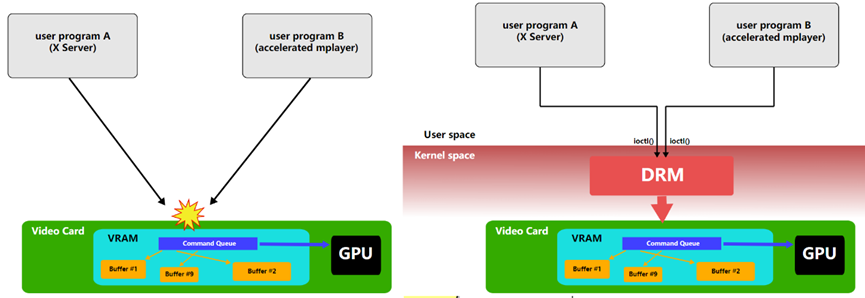
DRM允许多个程序同时访问3D视频卡,避免冲突。
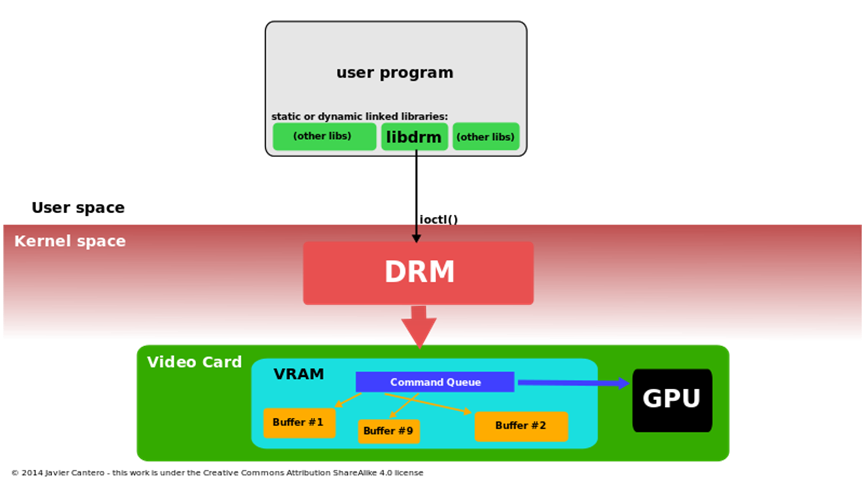
使用Linux内核的直接渲染管理器访问3D加速图形卡的过程。
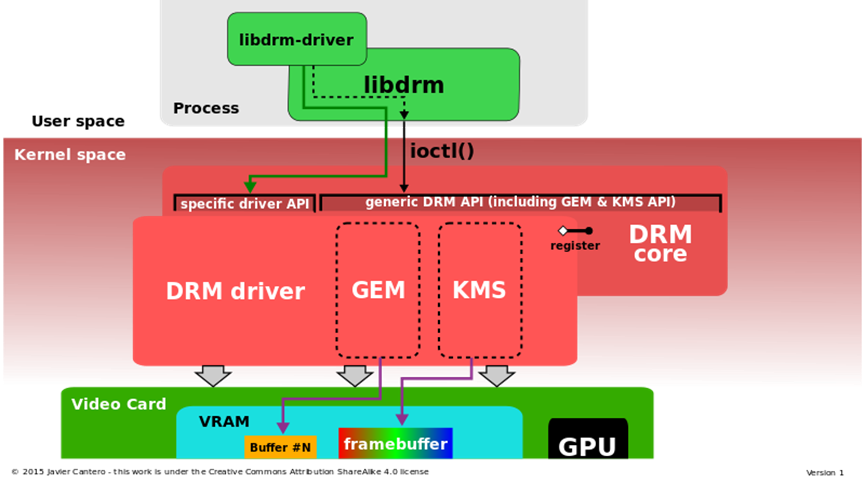
直接渲染管理器体系结构详细信息:DRM核心和DRM驱动程序(包括GEM和KMS),由libdrm接口。
最初(当Linux首次支持图形硬件加速时),只有一段代码可以直接访问图形卡:XFree86服务器。设计如下:通过以超级用户权限运行,XFree86服务器可以从用户空间访问卡,并且不需要内核支持来实现2D加速。这种设计的优点是简单,而且XFree86服务器可以很容易地从一个操作系统移植到另一个操作系统,因为它不需要内核组件。多年来,这是最广泛的X服务器设计(尽管也有明显的例外,比如XSun,它在内核中为一些驱动程序实现了modesetting)。
后来,第一个独立于硬件的3D加速设计Utah-GLX出现在Linux上,Utah-GLX基本上包含一个实现GLX的附加用户空间3D驱动程序,并以类似于2D驱动程序的方式从用户空间直接访问图形硬件。在3D硬件与2D明显分离的时代(因为2D和3D使用的功能完全不同,或者因为3D卡是一个完全独立的卡,即3Dfx),拥有一个完全独立的驱动程序是有意义的。此外,从用户空间直接访问硬件是在Linux下实现3D加速的最简单方法和最短途径。
与此同时,帧缓冲区驱动程序越来越广泛,它代表了可以同时直接访问图形硬件的另一个组件。为了避免帧缓冲区和XFree86驱动程序之间的潜在冲突,决定在VT交换机上,内核将向X服务器发出信号,告诉其保存图形硬件状态。要求每个驱动程序在VT交换机上保存其完整的GPU状态使驱动程序更加脆弱,对于突然面临不同驱动程序之间容易出现错误的交互的开发人员来说,生活变得更加困难。请记住,XFree86驱动程序至少有两种可能(xf86视频vesa和本机XFree86驱动程序)和两种内核帧缓冲区驱动程序(vesafb和本机帧缓冲区驱动程序),因此每个GPU至少有四种共存驱动程序的组合。
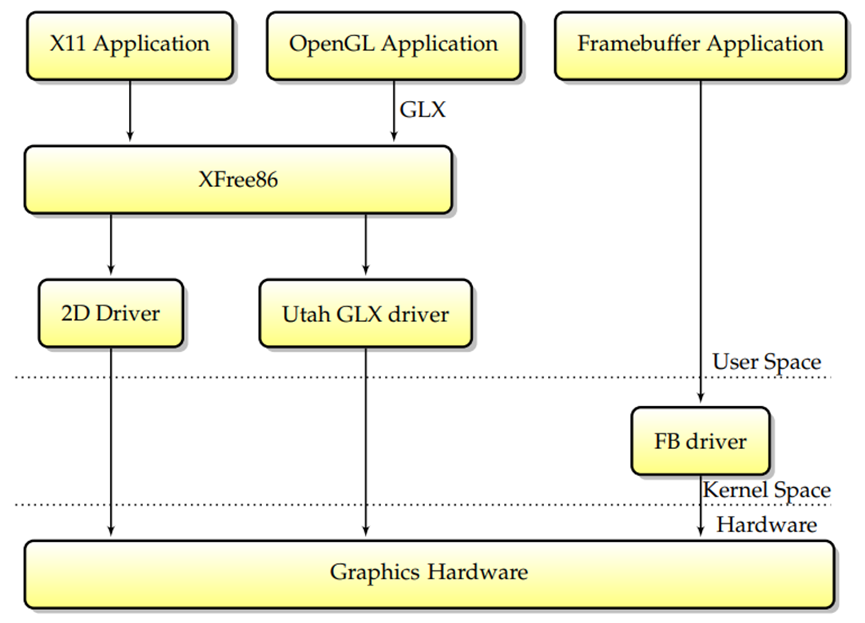
显然,这种模式有缺点。首先,它要求允许未经授权的用户空间应用程序访问3D图形硬件。其次,如上图所示,所有GL加速都必须通过X协议间接进行,将显著降低其速度,尤其是对于纹理上传等数据密集型功能。由于人们越来越担心Linux的安全性和性能缺陷,需要另一种模型。
为了解决Utah-GLX模型的可靠性和安全性问题,将DRI模型放在一起;XFree86及其后续版本X.Org都使用了它。该模型依赖于一个额外的内核组件,其职责是从安全角度检查3D命令流的正确性。现在的主要变化是,没有权限的OpenGL应用程序将向内核提交命令缓冲区,内核将检查它们的安全性,然后将它们传递给硬件执行,而不是直接访问卡。这种模型的优点是不再需要信任用户空间,但XFree86的2D命令流仍然没有通过DRM,因此X服务器仍然需要超级用户权限才能直接映射GPU寄存器。
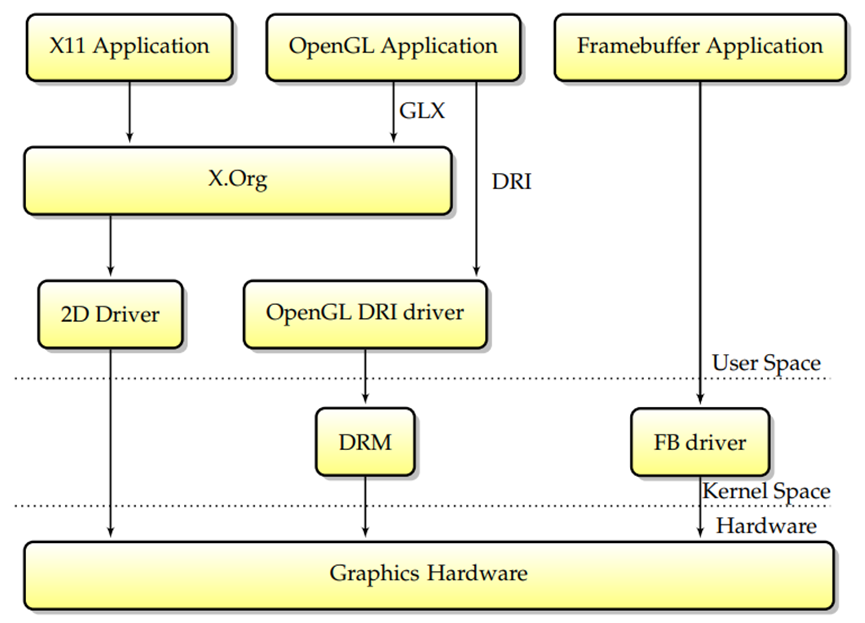
当前堆栈是从一组新的需求演变而来的。首先,要求X服务器具有超级用户权限总是会带来严重的安全隐患。其次,在以前的设计中,不同的驱动程序接触单个硬件,通常会导致问题。为了解决这个问题,关键有两个方面:第一,将内核帧缓冲区功能合并到DRM模块中,第二,让X.Org通过DRM模块访问图形卡并无权限运行。这种模型被称为内核模式设置(KMS),在这个模型中,DRM模块现在负责作为帧缓冲区驱动程序和X.Org提供模式设置服务。

总之,应用程序通过封装绘图调用的特定库与X.Org通信,当前的DRI设计随着时间的推移在许多重要步骤中不断发展,在现代堆栈中,所有图形硬件活动都由内核模块DRM控制。Linux总的模块交互图如下:

更详细的交互和分层架构如下:
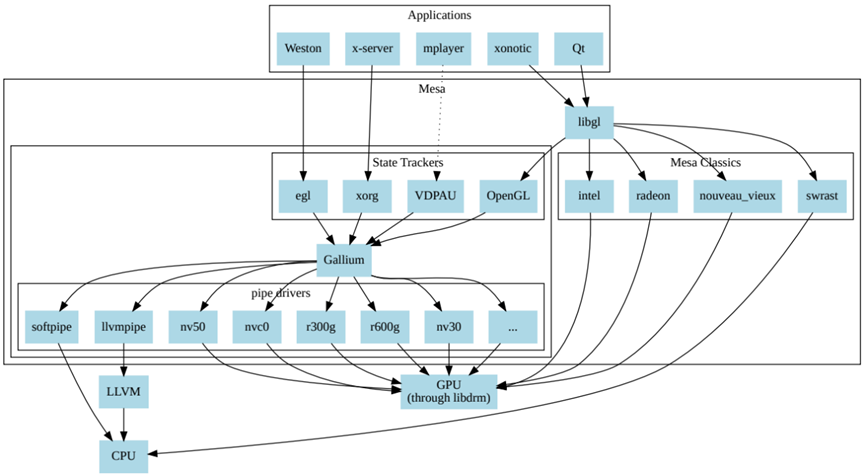
3 Framebuffer驱动
在核心,帧缓冲区驱动程序实现以下功能:
- 模式设置。模式设置包括配置视频模式以在屏幕上获取图片,包括选择视频分辨率和刷新率。
- 可选2d加速。帧缓冲区驱动程序可以提供用于加速linux控制台的基本2D加速,包括视频内存中的拷贝和实体填充。加速有时通过挂钩提供给用户空间(然后用户空间必须对特定于卡的MMIO寄存器进行编程,需要root权限)。
通过只实现这两部分,帧缓冲区驱动程序仍然是最简单、最合适的linux图形驱动程序形式。帧缓冲区驱动程序并不总是依赖于特定的卡型号(如nvidia或ATI)。存在vesa、EFI或Openfirmware之上的驱动程序,这些驱动程序不是直接访问图形硬件,而是调用固件功能来实现模式设置和2D加速。
帧缓冲区驱动程序是linux图形驱动程序的最简单形式。只需很少的实现工作,帧缓冲区驱动程序提供了较低的内存占用,因此对嵌入式设备很有用。实现加速是可选的,因为存在软件回退功能。
4 直接渲染管理器
在复杂的世界中,使用内核模块是一项要求。此内核模块称为直接渲染管理器(DRM),可用于多种用途:
- 将图形卡的关键初始化放在内核中,例如上载固件或设置DMA区域。
- 在多个用户空间组件之间共享渲染硬件,并处理访问。
- 通过防止应用程序对任意内存区域执行DMA,以及更一般地防止以任何可能导致安全漏洞的方式对卡进行编程来加强安全性。
- 通过向用户空间提供视频内存分配功能来管理卡的内存。
- DRM得到了改进,以实现模式设置,简化了以前DRM和帧缓冲区驱动程序争用同一GPU的情况。相反,将删除帧缓冲区驱动程序,并在DRM中实现帧缓冲区支持。
内核模块(DRM)是全局DRI/DRM用户空间/内核方案(下图包含libdrm-DRM-入口点-多个用户空间应用程序):

当设计一个Linux图形驱动程序以实现不仅仅是简单的帧缓冲区支持时,首先要做的是一个DRM组件,应该派生出一种既高效又能加强安全性的设计。DRI/DRM方案可以以不同的方式实现,并且接口确实完全是特定于卡的。
DRM批量缓冲区提交模型:DRM设计的核心是DRM_GEM_EXECBUFFER ioctl,允许用户空间应用程序向内核提交一个批处理缓冲区,然后内核将其放在GPU上。此ioctl允许许多事情,如共享硬件、管理内存和强制执行内存保护。
DRM的职责之一是在多个用户空间进程之间复用GPU本身。如果GPU保持图形状态,那么当多个应用程序使用同一GPU时,就会出现一个问题:如果什么都不做,应用程序就会破坏彼此的状态。根据当前的硬件,主要有两种情况:
1、当GPU具有硬件状态跟踪功能时,硬件共享会更简单,因为每个应用程序都可以发送到单独的上下文,GPU会跟踪每个应用程序本身的状态。此种方法就是新驱动的工作方式。
2、当GPU没有多个硬件上下文时,复用硬件的常见方法是在每个批处理缓冲区的请求时重新提交状态,是intel和radeon驱动程序多路复用GPU的方式。请注意,重新提交状态的职责完全依赖于用户空间。如果用户空间没有在每个批处理缓冲区开始时重新提交状态,那么来自其他DRM进程的状态将泄漏到它身上。DRM还防止同时访问同一硬件。
内核能够移动内存区域来处理内存压力大的情况。根据硬件的不同,有两种实现方法:
1、如果硬件具有完整的内存保护和虚拟化,则可以在分配内存资源时将其分页到GPU中,并隔离每个进程。因此,支持GPU内存的内存保护不需要太多。
2、当硬件没有内存保护时,仍然可以完全在内核中实现,用户空间完全不受其影响。为了允许重新定位对用户空间进程起作用,而用户空间进程在其他方面并不知道它们,命令提交ioctl将通过将所有硬件偏移量替换到当前位置来重写内核中的命令缓冲区。由于内核知道所有内存缓冲区的当前位置,使得前述方法成为可能。为了防止访问任意GPU内存,命令提交ioctl还可以检查这些偏移量中的每一个是否为调用进程所有,如果不是,则拒绝批处理缓冲区。这样,当硬件不提供该功能时,就可以实现内存保护。
DRM管理现代linux图形堆栈中的所有图形活动,是堆栈中唯一受信任的部分,负责安全,因此,不应信任其他组件。它提供基本的图形功能:模式设置、帧缓冲区驱动程序、内存管理。
5 Mesa
Mesa也称为Mesa3D和Mesa3D图形库,是OpenGL、Vulkan和其他图形API规范的开源软件实现。Mesa将这些规范转换为特定于供应商的图形硬件驱动程序。其最重要的用户是两个图形驱动程序,它们主要由Intel和AMD为各自的硬件开发和资助(AMD在不推荐的AMD Catalyst上推广其Mesa驱动程序Radeon和RadeonSI,Intel只支持Mesa驱动程序)。专有图形驱动程序(如Nvidia GeForce驱动程序和Catalyst)取代了所有Mesa,提供了自己的图形API实现,开发名为Nouveau的Mesa Nvidia驱动程序的开源工作主要由社区开发。
除了游戏等3D应用程序外,现代显示服务(X.org的Glamer或Wayland的Weston)也使用OpenGL/EGL;因此,所有图形通常都要使用Mesa。Mesa由freedesktop托管,该项目于1993年8月由布莱恩·保罗发起。Mesa随后被广泛采用,现在包含了世界各地各种个人和公司的众多贡献,包括管理OpenGL规范的Khronos集团图形硬件制造商的贡献。
Mesa有两个主要用途:
1、Mesa是OpenGL的软件实现,被认为是参考实现,在检查一致性时很有用,因为官方的OpenGL一致性测试并不公开。
2、Mesa为linux下的开源图形驱动程序提供了OpenGL入口点。
Mesa是Linux下的参考OpenGL实现,所有开源图形驱动程序都使用Mesa for 3D。

视频游戏通过OpenGL将渲染计算实时外包给GPU,着色器使用OpenGL着色语言或SPIR-V编写,并在CPU上编译,编译后的程序在GPU上执行。(下图)

Linux图形堆栈见下图:DRM&libDRM,Mesa 3D,其中显示服务属于窗口系统,只用于游戏等上层应用。
Wayland的免费实现依赖于EGL的Mesa实现,名为libwayland EGL的特殊库是为支持对帧缓冲区的访问而编写的,EGL 1.5版本已过时。在GDC 2014上,AMD正在探索使用DRM而不是其内核内blob的战略变化。
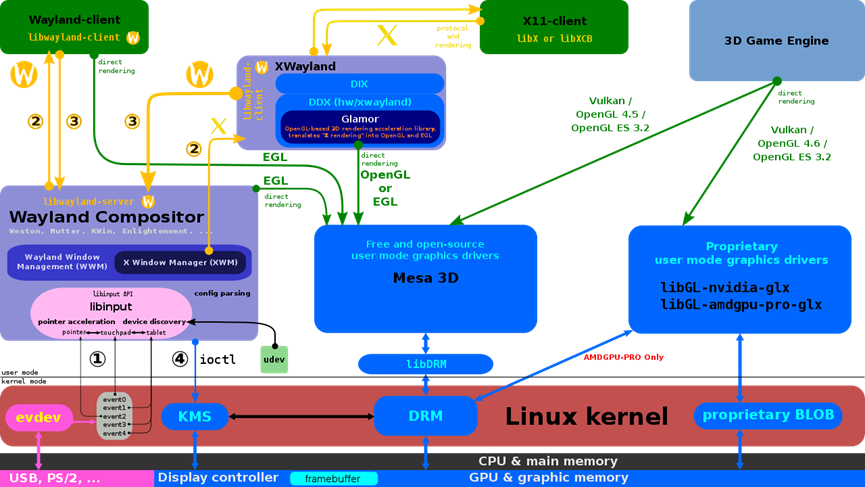
6 Wayland
Wayland旨在更简单地替代X,更易于开发和维护。Wayland是一种用于合成器与其客户机对话的协议,也是该协议的C库实现。合成器可以是在Linux内核模式设置和evdev输入设备上运行的独立显示服务器、X应用程序或wayland客户端本身。客户端可以是传统应用程序、X服务器(无根或全屏)或其他显示服务器。Wayland项目的一部分也是Wayland合成器的Weston参考实现,Weston可以作为X客户端或Linux KMS运行,Weston合成器是一种最小且快速的合成器,适用于许多嵌入式和移动用例。
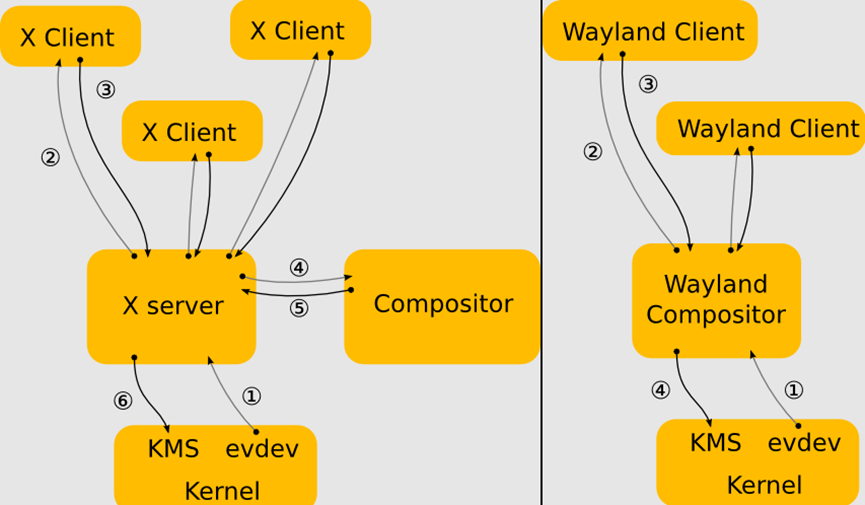
使用X(左)和Wayland(右)的驱动架构对比。
调度机制
1 OS And GPU abstraction
早在10年前,微软联合大学的科研人员在Operating Systems must support GPU abstractions中指出,缺乏对GPU抽象的操作系统支持从根本上限制了GPU在许多应用领域的可用性。操作系统为最常见的资源(如CPU、输入设备和文件系统)提供抽象。相比之下,操作系统目前将GPU隐藏在笨拙的ioctl 接口后面,将抽象的负担转移到用户库和运行时上。因此,操作系统无法为GPU提供系统范围的保证,例如公平性和隔离性,开发人员在构建集成GPU和其他操作系统管理资源的系统时,必须牺牲模块化和性能。他们提出了新的内核抽象,以支持GPU和其他加速器设备作为一流的计算资源。
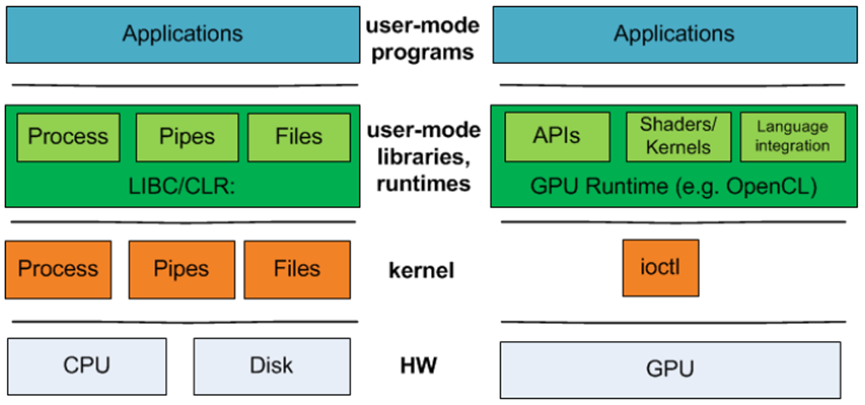
CPU与GPU程序的技术堆栈。对于GPU程序,CPU程序的操作系统级别和用户模式运行时抽象之间没有1对1的对应关系。
不存在对GPU抽象的直接操作系统支持,因此利用GPU完成此工作负载必然需要一个用户级GPU编程框架和运行时,如CUDA或OpenCL。在这些框架中实现xform和detect会大大提高隔离运行的组件的速度,但组合系统(catusb | xform | detect | hidinput)会因跨用户内核边界和跨PCI-e总线的硬件的过度数据移动而受损。
现代操作系统目前无法保证GPU的公平性和性能隔离,主要是因为GPU不是作为共享计算资源(如CPU)管理的,而是作为I/O设备管理的,其接口仅限于一小部分已知操作(如init_module、read、write、ioctl)。当操作系统需要使用GPU来实现其功能时,这种设计就成为了一个严重的限制。实际上,NVIDIA GPU Direct实现了这样一个功能,但需要在所涉及的任何I/O设备的驱动程序中提供专门的支持。自己计算(例如,Windows 7与Aero用户界面一样)。在当前的制度下,时间分割和超时可以确保屏幕刷新率保持不变,但在执行公平性和系统负载平衡时,操作系统在很大程度上取决于GPU驱动程序。
新的体系结构可能会改变跨GPU和CPU内存域管理数据的相对难度,但软件将继续发挥重要作用,在可预见的未来,优化数据移动仍然很重要。AMD的Fusion将CPU和GPU集成到一个芯片上,然而,它将CPU和GPU内存分区。Intel的Sandy Bridge(另一种CPU/GPU组合)表明,未来几年将出现各种形式的集成CPU/GPU硬件上市。新的混合系统,例如NVIDIA Optimus,在芯片和高性能离散图形卡上都具有能效,即使使用组合的CPU/GPU芯片,数据管理也更加明确。但即使是一个完全集成的虚拟内存系统,也需要系统支持来最小化数据拷贝。
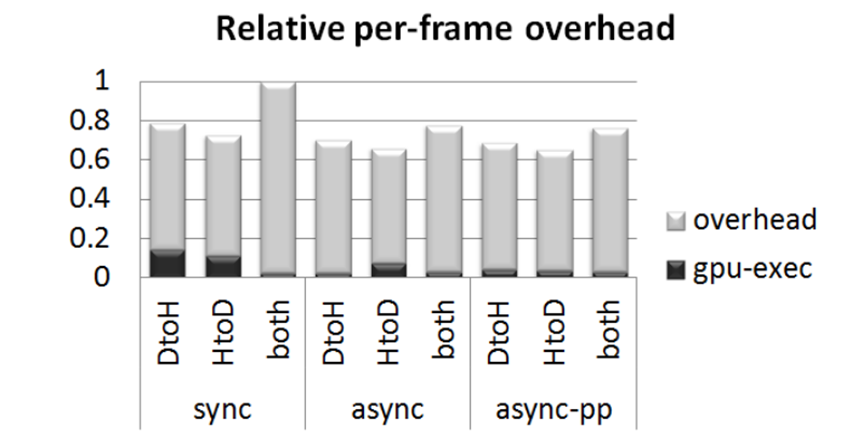
原型系统中基于CUDA的xform程序实现的相对GPU执行时间和开销(越低越好)。sync使用CPU和GPU之间的缓冲区同步通信,async使用异步通信,async pp同时使用异步和乒乓缓冲区来进一步隐藏延迟。条形图分为在GPU上执行的时间和系统开销。DtoH表示设备和主机之间在每个帧上进行通信的实现,反之亦然,并且两者都表示每个帧的双向通信。报告的执行时间与同步、双向情况(同步两者)相关。
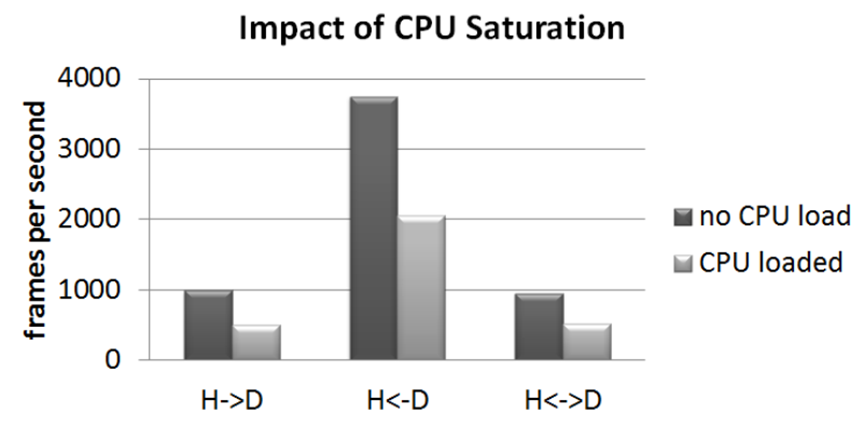
CPU密集工作对GPU密集任务的影响。当系统中存在并行GPU和CPU工作时,当前的操作系统抽象限制了操作系统提供性能隔离的能力。H→D是一个CUDA工作负载,它具有从主机到GPU设备的通信,而H←D具有从GPU到主机的通信,H↔D具有双向通信。

g)
GPU密集工作对CPU密集任务的影响。这些图显示了操作系统能够在程序大量使用GPU的60秒内传递鼠标移动事件的频率(以Hz为单位)。在此期间的平均CPU利用率低于25%。
他们提出了以下新的操作系统抽象,可以使GPU适用于更广泛的应用程序域。这些抽象允许将计算表示为有向图,从而实现高效的数据移动和高效、公平的调度。
- PTask。PTask类似于传统的OS进程抽象,但PTask基本上在GPU上运行。PTask需要来自OS的一些编排来协调其执行,但不需要用户模式主机进程。PTask有一个可以绑定到端口的输入和输出资源列表(类似于POSIX stdin、stdout、stderr文件描述符)。
- Port。Port是内核命名空间中的一个对象,可以绑定到PTask输入和输出资源。一个Port是一个数据源或接收器,提供了一种方法来公开GPU代码中的数据和参数,这些数据和参数必须动态绑定,并且可以由GPU或CPU内存中的缓冲区填充。
- Channel。Channel类似于POSIX管道:它将端口连接到其他端口,或连接到系统中的其他数据源和接收器,如I/O总线、文件等。Channel具有子类型GraphInputChannel、GraphOutChannel和GraphInternalChannel。
- Graph。Graph是PTask节点的集合,其输入和输出端口通过通道连接。可以独立创建和执行多个图,PTask运行时负责公平地调度它们。
在操作系统接口上支持这些新的抽象需要新的系统调用来创建和管理ptask、端口和通道,额外的系统调用类似于POSIX中的进程API、进程间通信API和调度器提示API。
与GPU协调操作系统调度的两个主要好处是:
- 效率性。是指ptask准备就绪和在GPU上调度之间的低延迟,以及在GPU上调度足够的ptask工作以充分利用其计算带宽。
- 公平性。是指操作系统调度器在GPU利用率和用户界面响应性之间取得平衡。此外,与GPU竞争的PTAK都能获得其计算带宽的合理份额。并非所有PTASK都有所有这些调度要求,如典型的CUDA程序不关心低延迟调度。
总之,他们主张对内核抽象进行根本性的重组,以管理交互式、大规模并行设备。内核必须根据需要只公开足够的硬件细节,以使程序员能够实现良好的性能和低延迟,同时提供根据机器拓扑进行封装和专门化的通信抽象。GPU是一种通用的共享计算资源,必须由操作系统进行管理,以提供公平性和隔离性。
2 Halide Pipeline
Schedule Synthesis for Halide Pipelines on GPUs揭示了Halide DSL和编译器通过分离算法描述和优化调度,实现了针对异构体系结构的图像处理管道的高性能代码生成。然而,自动调度生成目前仅适用于多核CPU体系结构。因此,在为具有GPU功能的平台进行优化时,仍然需要专家级知识。他们使用新的优化过程扩展了当前的Halide自动调度程序,以高效地生成基于CUDA的GPU体系结构的调度。实验结果表明,该调度平均比手动调度快10%,比以前的自动调度快2倍以上。
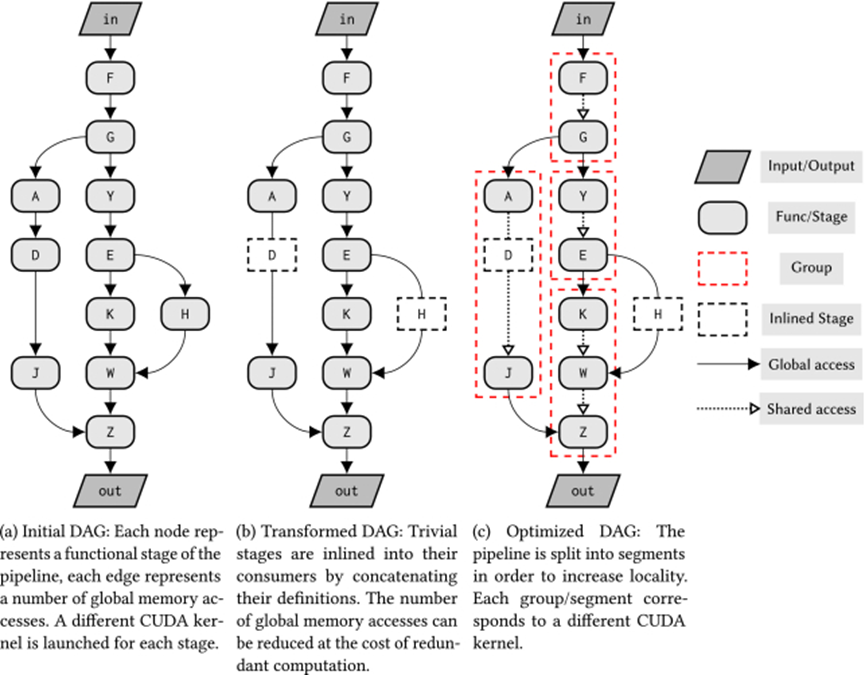
通用管道示例:在将管道拆分为分配了优化计划的较小阶段组之前,将普通阶段内联到其使用者中。

简单的实现会在不同的CUDA内核中完全计算每个阶段,并将所有数据存储到全局内存中。

重叠分块时间表计算一次分块内迭代(或线程块)所需的所有像素,并将其存储在共享内存中。
该文还介绍了在Halide master自动调度程序中实现的新优化过程,以生成针对基于CUDA的GPU架构的优化调度。其遵循一个类似于当前优化流程的过程,其中琐碎(逐点消耗)阶段首先被内联到其消费者中,然后使用Halide master中实现的贪心算法进行分组。下图显示了autoscheduler使用的优化流的概述。
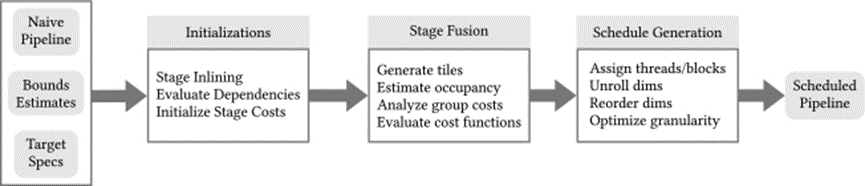
基本调度流程:调度器需要循环边界估计以及用户给定的目标规范描述,以生成给定管道的优化调度。编译流中的大多数步骤都已扩展,以支持自动GPU调度。
3 Hardware Accelerated GPU Scheduling
Hardware Accelerated GPU Scheduling阐述了WDDM在2020年5月引入的一种基于硬件加速的GPU调度机制。
自从Windows显示驱动程序Model 1.0(WDDM)的推出以及GPU调度在Windows中的引入,已经过去了将近14年。很少有人会记得WDDM之前的日子,在那里,应用程序只需向GPU提交他们想要的工作即可。他们提交到一个全局队列,在那里它以严格的“先提交,先执行”方式执行。在大多数GPU应用程序都是全屏游戏的时候,这些最基本的调度方案是可行的,一次运行一个。
随着向使用GPU实现更丰富图形和动画的广泛应用程序的过渡,该平台需要更好地确定GPU工作的优先级,以确保响应的用户体验。因此,WDDM GPU调度程序诞生了。
随着时间的推移,Windows显著增强了WDDM核心的GPU调度程序,支持每个新WDDM版本的其他功能和场景。然而,在整个发展过程中,调度器的一个方面没有改变。他们一直在CPU上运行一个高优先级线程,该线程负责协调、优先排序和安排各种应用程序提交的工作。
这种调度GPU的方法在提交开销以及工作到达GPU的延迟方面有一些基本的限制,这些开销大部分被传统的应用程序编写方式所掩盖。例如,应用程序通常会在第N帧上执行GPU工作,并让CPU提前运行,为第N+1帧准备GPU命令。这种GPU命令的批量缓冲允许应用程序每帧只提交几次,从而最大限度地降低调度成本,并确保良好的CPU-GPU执行并行性。
CPU和GPU之间缓冲的一个固有副作用是,用户体验到的延迟会增加。CPU在“第N+1帧”期间拾取用户输入,但GPU直到下一帧才渲染用户输入,延迟减少和提交/调度开销之间存在根本的紧张关系。应用程序可以更频繁地提交,以小批量方式提交以减少延迟,或者可以提交更大批量的工作以减少提交和调度开销。
随着Windows 2020年5月10日的更新,其引入一个新的GPU调度程序作为用户选择加入,但默认关闭选项。有了正确的硬件和驱动程序,Windows现在可以将大部分GPU调度卸载到基于GPU的专用调度处理器上。Windows系统可以通过Windows设置 -> 系统 -> 显示 -> 图形设置访问设置页面,以便开启或关闭硬件加速的GPU调度。

Windows继续控制优先级,并决定哪些应用程序在上下文中具有优先级。他们将高频任务卸载到GPU调度处理器,处理各种GPU引擎的量子管理和上下文切换。新的GPU调度程序是对驱动程序模型的重大和根本性更改,更改调度程序类似于在仍居住在房屋中的情况下重建房屋的基础。
虽然新的调度器减少了GPU调度的开销,但大多数应用程序都被设计为通过缓冲来隐藏调度成本。硬件加速GPU调度第一阶段的目标是使图形子系统的一个基本支柱现代化,并为将来的事情做好准备。
就目前而言,有评测文章发现,开启此项功能对部分3A游戏并无实际的帧率提升。
4 TimeGraph
GPU现在常用于图形和数据并行计算。随着越来越多的应用程序趋向于在多任务环境中的GPU上加速,其中多个任务同时访问GPU,操作系统必须在GPU资源管理中提供优先级和隔离功能,特别是在实时设置中。当前主流的GPU是命令驱动的:
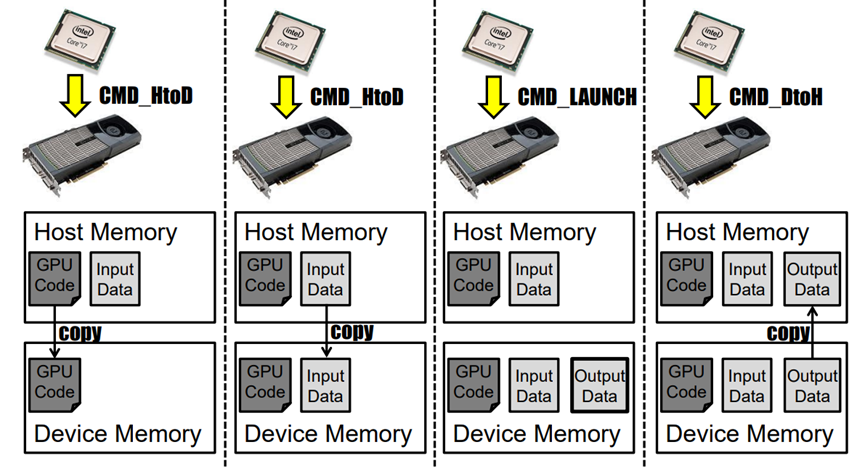
多任务的常见问题是CPU常常会导致GPU阻塞:

TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments介绍了TimeGraph——一种设备驱动程序级别的实时GPU调度器,用于保护重要的GPU工作负载免受性能干扰。
TimeGraph采用了一种新的事件驱动模型,该模型将GPU与CPU同步,以监控从用户空间发出的GPU命令,并以响应方式控制GPU资源的使用。TimeGraph支持两种基于优先级的调度策略,以解决GPU处理的异步性和非抢占性带来的响应时间和吞吐量之间的权衡问题。资源保留机制还用于说明和强制执行GPU资源使用,从而防止行为不端的任务耗尽GPU资源。进一步提供GPU命令执行成本的预测,以增强隔离。
他们使用OpenGL图形基准进行的实验表明,即使面对极端的GPU工作负载,TimeGraph也能将主要GPU任务的帧速率保持在所需的水平,而如果没有TimeGraph支持,这些任务几乎没有响应。此外还发现,施加在时间图上的性能开销可以限制在4-10%,其事件驱动调度器的吞吐量比现有的tick驱动调度器提高了约30倍。
该文假设系统由通用多核CPU和板载GPU组成,不操纵任何GPU内部单元,因此GPU命令在提交到GPU后不会被抢占。TimeGraph独立于库、编译器和运行时引擎,因此,时间图的原理适用于不同的GPU架构(如NVIDIA Fermi/Tesla和ATI Stream)和编程框架(如OpenGL、OpenCL、CUDA和HMPP)。目前,TimeGraph是为Gallium3D OpenGL软件栈中的Nouveau设计和实现的,该软件栈也计划支持OpenCL。此外,TimeGraph已移植到打包在PathScale ENZO套件中的PSCNV开源驱动程序,该套件支持CUDA和HMPP。然而,鉴于目前可用的一组开源解决方案:Nouveau和Gallium3D,该文主要关注OpenGL工作负载。
TimeGraph是设备驱动程序的一部分,它是用户空间程序向GPU提交GPU命令的接口。假设设备驱动程序是基于大多数类UNIX操作系统中采用的直接渲染基础设施(DRI)模型设计的,作为X Window系统的一部分。在DRI模式下,用户空间程序可以直接访问GPU来渲染帧,而无需使用窗口协议,同时仍可以使用窗口服务器将渲染帧blit到屏幕上。GPGPU框架不需要这样的窗口过程,因此它们的模型更加简化。
为了向GPU提交GPU命令,必须为用户空间程序分配GPU通道,这些通道在概念上表示GPU上的单独地址空间。例如,NVIDIA Fermi和Tesla架构支持128个通道,每个通道的GPU命令提交模型如下图所示。

GPU命令提交模型。
每个通道使用两种类型的内核空间缓冲区:用户推送缓冲区和内核推送缓冲区。用户推送缓冲区映射到相应任务的地址空间,其中GPU命令从用户空间推送。GPU命令通常分组为非抢占区域,以匹配用户空间原子性假设。同时,内核推送缓冲区用于内核原语,如主机设备同步、GPU初始化和GPU模式设置。
当用户空间程序将GPU命令推送到用户推送缓冲区时,它们还将数据包写入内核推送缓冲区的特定环形缓冲区部分,称为间接缓冲区,每个数据包都是一个(大小和地址)元组,用于定位某个GPU命令组。驱动程序将GPU上的命令调度单元配置为读取用于命令提交的缓冲区,这个环形缓冲区由GET和PUT指针控制,指针从同一个地方开始。每次数据包写入缓冲区时,驱动程序都会将PUT指针移动到数据包的尾部,并向GPU命令调度单元发送信号,以下载位于GET和PUT指针之间的数据包所在的GPU命令组。然后,GET指针会自动更新到与PUT指针相同的位置。一旦这些GPU命令组提交到GPU,驱动程序将不再管理它们,并继续提交下一组GPU命令组(如果有)。因此,这个间接缓冲区扮演着命令队列的角色。
每个GPU命令组可以包括多个GPU命令,每个GPU命令都由标头(header)和数据组成,标头包含方法和数据大小,而数据包含传递给方法的值。方法表示GPU指令,其中一些指令在计算和图形之间共享,另一些则针对每种指令。我们假设,一旦GPU命令组卸载到GPU上,设备驱动程序不会抢占它们。在同一GPU通道中,GPU命令执行顺序错误。GPU通道由GPU引擎自动切换。
上述驱动程序模型基于直接渲染管理器(DRM),尤其针对NVIDIA Fermi和Tesla架构,但也可以用于其他架构,只需稍加修改。
TimeGraph的体系结构及其与软件堆栈其余部分的交互如下图所示。用户空间程序无需修改,GPU命令组可以通过现有软件框架生成。然而,TimeGraph需要与设备驱动程序空间中名为PushBuf的特定接口进行通信,PushBuf接口允许用户空间提交存储在用户推送缓冲区中的GPU命令组。TimeGraph使用此PushBuf接口将GPU命令组排队,它还使用为GPU到CPU中断准备的IRQ处理程序来调度下一个可用的GPU命令组。
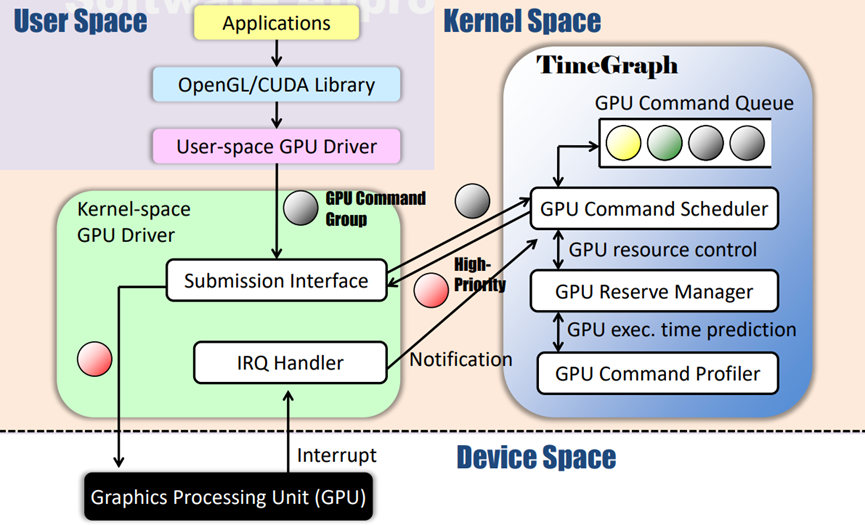
TimeGraph由GPU命令调度器、GPU保留管理器和GPU命令探查器组成。GPU命令调度器根据任务优先级对GPU命令组进行排队和调度,它还与GPU保留管理器协调,以计算和强制执行任务的GPU执行时间。GPU命令探查器支持预测GPU命令执行成本,以避免超出保留范围。支持两种调度策略来解决响应时间和吞吐量之间的权衡问题:
- 可预测响应时间(PRT):此策略最大限度地减少GPU上的优先级反转,以根据优先级提供可预测的响应时间。当GPU不空闲时,GPU命令排队;当GPU空闲时,GPU命令被调度:

- 高吞吐量(HT):此策略增加总吞吐量,允许额外的优先级反转。当GPU不空闲时,只有当优先级低于当前GPU上下文时,GPU命令才会排队;当GPU空闲时,会调度GPU命令:

ng)
它还支持两种GPU保留策略,以解决隔离和吞吐量之间的权衡问题:
- 后验强制(PE):此策略在GPU命令组完成后强制GPU资源使用,而不牺牲吞吐量。优化GPU资源使用,指定每个任务的容量(C)和周期(P)(/proc/GPU/$任务):
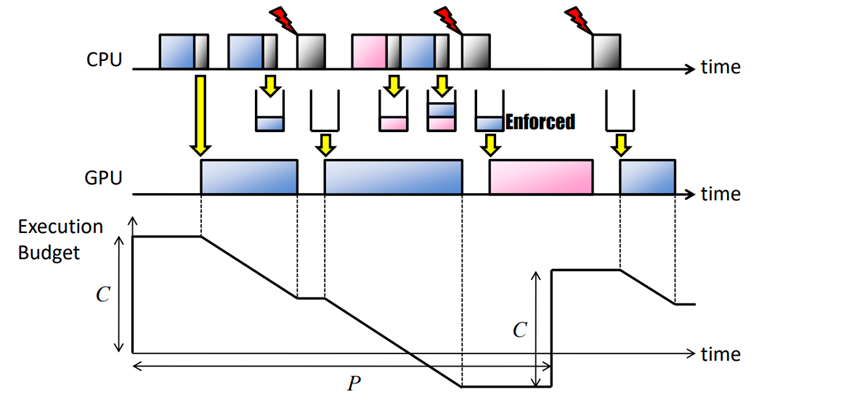
- 先验强制(AE):此策略在提交GPU命令组之前,使用GPU执行成本预测强制GPU资源使用,但会增加额外的开销。指定每个任务的容量(C)和周期(P)(/proc/GPU/$任务):

为了将多个任务统一到一个保留中,TimeGraph保留机制提供了共享保留模式。特别是,TimeGraph在加载时使用PE策略创建一个特殊的共享保留实例(称为Background,它为不属于任何特定保留的所有GPUAccessed任务提供服务)。下图显示了PushBuf接口和IRQ处理程序的高级图,其中TimeGraph引入的修改以粗体框架突出显示。此图基于Nouveau实现,但大多数GPU驱动程序应该具有类似的控制流。
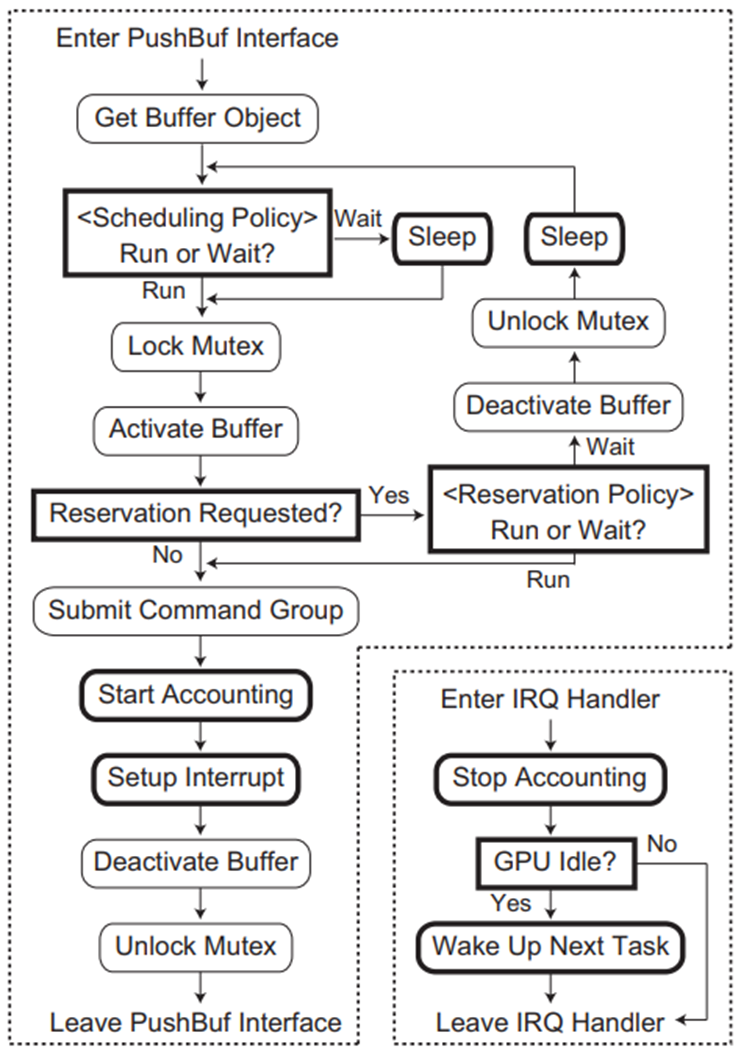
PushBuf接口和IRQ处理程序与时间图方案的关系图。
GPU命令调度器的目标是根据任务优先级对非抢占式GPU命令组进行排队和调度。为此,TimeGraph包含一个暂停任务的等待队列,它还管理GPU联机列表,即指向当前在GPU上执行的GPU命令组的指针列表。
当GPU命令组进入PushBuf界面时,GPU联机列表用于检查当前是否有正在执行的GPU命令组。如果列表为空,则将相应的任务插入其中,并将GPU命令组提交给GPU。否则,任务将插入到要调度的等待队列中。
GPU联机列表的管理需要有关GPU命令组何时完成的信息。TimeGraph采用事件驱动模型,该模型使用GPU到CPU中断来通知每个GPU命令组的完成,而不是以前工作中采用的tick驱动模型。每次中断时,相应的GPU命令组将从GPU联机列表中删除。
TimeGraph支持两种GPU调度策略。可预测响应时间(PRT)策略鼓励此类任务在不影响重要任务的情况下及时执行。此策略在某种意义上是可预测的,GPU命令组是基于任务优先级进行调度的,以使高优先级任务在GPU上响应。另一方面,高吞吐量(HT)策略适用于应该尽可能快地执行的任务。有一个权衡,即PRT策略以牺牲吞吐量为代价防止任务受到干扰,而HT策略实现了一个任务的高吞吐量,但可能会阻止其他任务。例如,桌面小部件、浏览器插件和视频播放器任务需要使用PRT策略,而三维游戏和交互式三维接口任务可以使用HT策略。
PRT策略强制任何GPU命令组等待前面的GPU命令组(如果有)完成。具体而言,如果GPU联机列表为空,则到达设备驱动程序的新GPU命令组可以立即提交给GPU。否则,相应的任务必须在等待队列中休眠。等待队列中的最高优先级任务(如果有)在GPU的每次中断时被唤醒。
下图(a)显示了在PRT策略下如何在GPU上调度具有不同优先级的三个任务,即高优先级、中优先级(MP)和低优先级(LP)。当MP任务到达时,其GPU命令组可以在GPU上执行,因为没有GPU命令组正在执行。如果GPU和CPU异步运行,则MP任务可以在其上一个GPU命令组执行时再次到达。但是,根据PRT策略,由于GPU没有空闲,MP任务这次将排队。由于同样的原因,甚至下一个HP任务也会排队,因为更高优先级的任务可能很快就会到达。TimeGraph附加在每个GPU命令组末尾的特定GPU命令集会向CPU生成一个中断,并相应地调用TimeGraph调度程序以唤醒等待队列中的最高优先级任务。因此,接下来选择在GPU上执行HP任务,而不是MP任务。这样,LP任务的下一个实例和HP任务的第二个实例将根据其优先级进行调度。
鉴于GPU命令组的到达时间未知,且每个GPU命令组都是非抢占的,我们认为PRT策略是提供可预测响应时间的最佳方法。然而,在每个GPU命令组边界进行调度决策不可避免地会带来开销,如下图(a)所示。
HT策略减少了这种调度开销,稍微减少了可预测的响应时间。如果(i)当前正在执行的GPU命令组是由同一任务提交的,并且(ii)等待队列中没有更高优先级的任务,则允许立即将GPU命令组提交给GPU。否则,它们必须以与PRT策略相同的方式暂停。在中断时,只有当GPU联机列表为空(GPU空闲)时,等待队列中优先级最高的任务才会被唤醒。
下图(b)描述了在HT策略下如何调度下图(a)中使用的同一组GPU命令组。与PRT策略不同,MP任务的第二个实例可以立即提交其GPU命令组,因为当前正在执行的GPU命令组是由其自身发出的。MP任务的这两个GPU命令组可以连续执行,而不会产生空闲时间,HP任务的两个GPU命令组也是如此。因此,HT策略更适用于面向吞吐量的任务,但HP任务被MP任务阻塞更长的时间。这是一种权衡,如果优先级反转至关重要,则PRT策略更合适。

TimeGraph中GPU调度的示例。
TimeGraph支持GPU执行时间预测,使用基于历史的方法——搜索与传入GPU命令序列匹配的以前GPU命令序列的记录,适用于二维,但需要调查三维和计算。