广播变量broadcast
广播变量允许程序缓存一个只读变量在集群的每台机器上,而不是每个任务保存一个拷贝。借助广播变量,可以用一种更高效的方法来共享一些数据,比如一个全局配置文件。
from pyspark import SparkConf,SparkContext
conf = SparkConf().setAppName("broadcast").setMaster("local[4]")
sc = SparkContext(conf=conf)
conf = {"ip": "192.168.10.108", "key": "spark"}
# 广播变量
broadVar = sc.broadcast(conf)
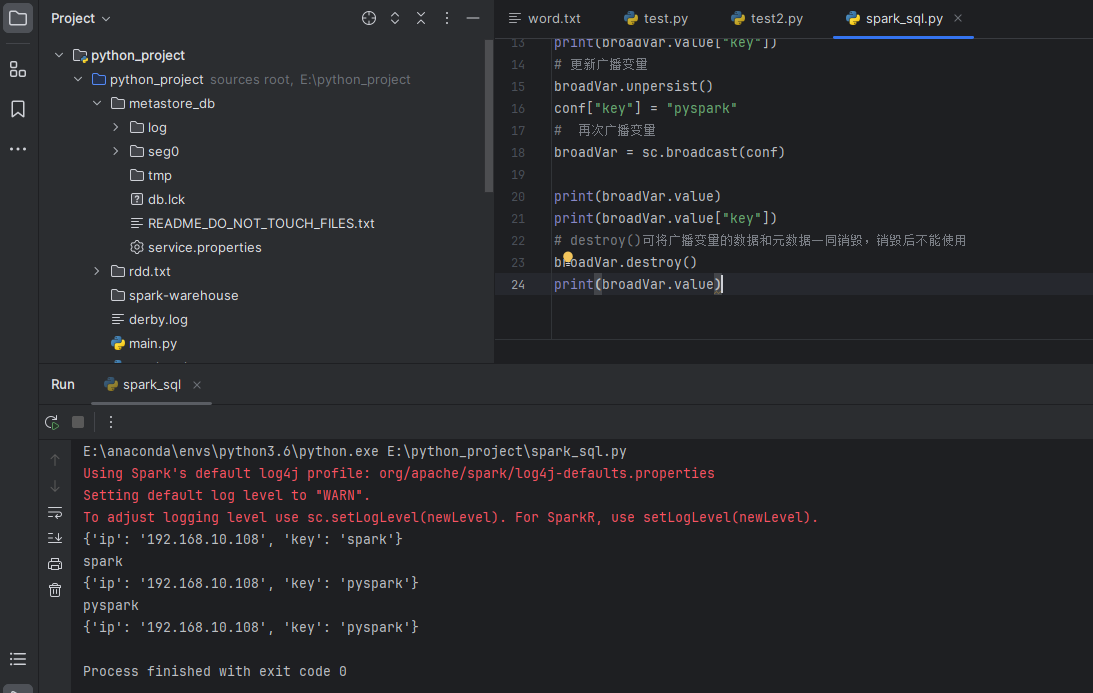
print(broadVar.value)
print(broadVar.value["key"])
# 更新广播变量
broadVar.unpersist()
conf["key"] = "pyspark"
# 再次广播变量
broadVar = sc.broadcast(conf)
print(broadVar.value)
print(broadVar.value["key"])
# destroy()可将广播变量的数据和元数据一同销毁,销毁后不能使用
broadVar.destroy()
print(broadVar.value)
累加器accumulator
实现在Driver端和Executor端共享变量 写的功能,Driver端定义的变量,在Executor端的每个Task都会得到这个变量的副本;
在每个Task对自己内部的变量副本值更新完成后,传回给Driver端,然后将每个变量副本的值进行累计操作;
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[3]").setAppName("Test")
sc = SparkContext(conf=conf)
rdd = sc.range(1, 101)
# 创建累加器,初始值0
acc = sc.accumulator(0)
def fcounter(x):
global acc
if x % 2 == 0:
acc += 1
# unsupported operand type(s) for -=
# acc -= 1
rdd_counter = rdd.map(fcounter)
print(acc.value) # 0 fcounter函数的逻辑还未执行
# 保证多次正确获取累加器值
rdd_counter.persist()
print(rdd_counter.count()) # 100
print(acc.value) # 50