
grep 行过滤
grep 匹配内容 源输入
grep and Andfile.txt//这条命令将会匹配Andfile.txt中文本的全部包含and的行
grep -i and Andfile.txt//-i会忽略大小写
grep -n and Andfile.txt//-n会显示出匹配出来的行的行号
grep -v and Andfile.txt//-v是反向,即这里表示不包含and的行
grep -c and Andfile.txt//-c是计数
cut 列过滤
cut 参数 源输入
cut -cn Fromfile.txt//-c表示指定要截取的列号,n表示列号
cut -d' ' -f2,5 Andfile.txt//-d指定分隔符,这里以' '为分隔符,其将每一行以' '进行分隔成各个元素;-f是指定要取的元素位置,(2,5)表示要取2和5列的元素
tr 字符转换
tr只能从标准输入中获取源输入,所以不能打开文件来获取数据,所以要用重定向或管道来获取数据

tr 源匹配模式 需要转化成模式
需要注意的是 源匹配模式 需要转化成模式 这两者能够一一配对上,比如上述命令是a与A对应,b与B对应....
我们可以用tr来进行加密和解密操作
tr -d '0-9' <fromfile.txt//-d表示要删除fromfile.txt中0-9的内容
tr -c -d '0-9\n' <fromfile.txt//-c表示正好相反,即删除除0-9与\n以外的全部内容
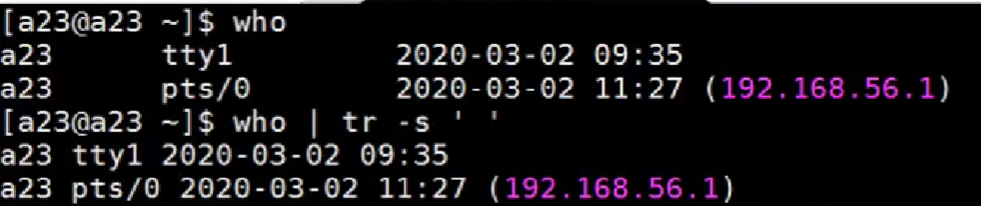
tr -s ' ' <fromfile.txt//-s表示可以将连续的重复的内容给去重
如上,最初每行中单词之间有较多连续的空格,可以用上述命令将其去重


sort 排序
sort -t^ -k3 filename//-t表示指定分隔符,分隔符会将每一行中有分隔符处的地方分解为一个一个元素,-k3表示指定每行按照第3个元素进行比较排序
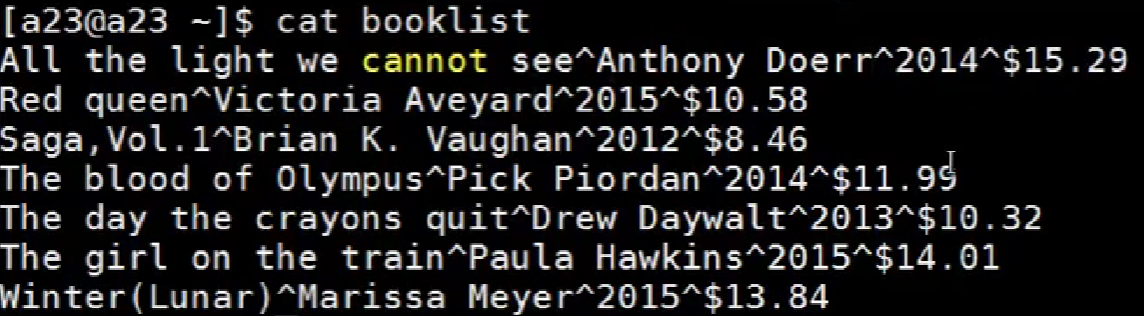
如上是初始booklist中的信息,每一行中以^为分隔符

执行上述命令后按照时间信息来排序
sort -t^ -k4.2nr filename//-k4.2n中的.2表示从第4个元素的第2个字符开始取,n表示然后按照数值排序(初始默认的排序方式是按照字典序排序),r表示逆序排序(默认从低到高排序)