其中: RL 分为基于价值的学习和基于策略的学习 和 AC 架构的
价值学习
DQN
DQN = Q_learing+网络
使用了价值网络 q(..w)
DQN 训练的过程
基础的DQN 就是 训练Q网络 更新w 参数
代码中梯度下降用的是下面这一张
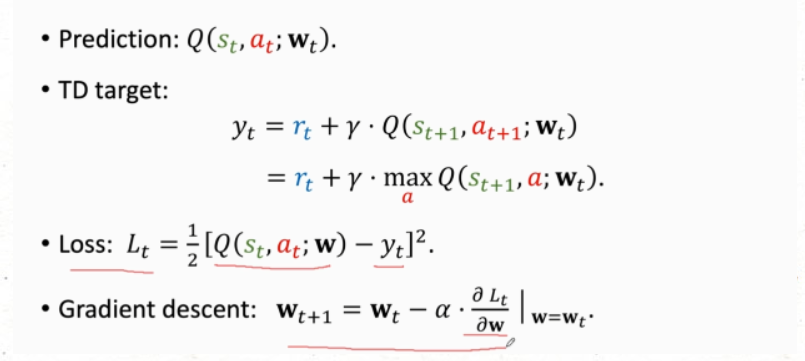
这里有个问题 下面这张图片 中有不一样的地方 即 Gradient descent
下面的dt 是反向传播得到的

DQN的改进之经验回放


DQN的改进之神经网络
使用到了优势函数A* = Q(s,a) - V(s)

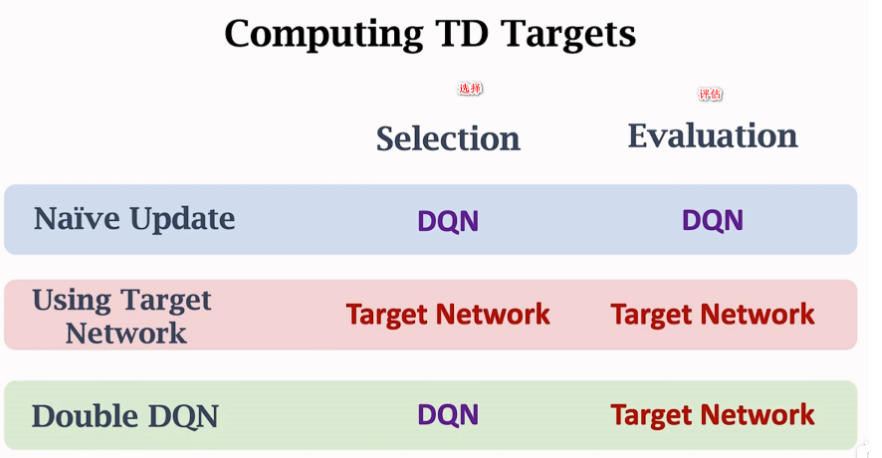
DQN 改进Bootstrapping Double DQN
出现 高估价值问题 V 为啥会产生?
解决方法:
可以采用两种网络 一种 targetnetwork 二种:double DQN (allevate 观测值)
这里 只更新target network


两种网络中的参数更新

比较两种网格中的TD Target yt

double DQN 的优势原因 莫凡中那个使用了两个网络
根据bootstraping 新目标值 = 原目标值 + (原目标值-新评估值)
如果新的评估值和目标值 是在同一个网络下取的。就可以能会出现高估问题
所以:可以通过评估值和目标值锁定在不同的网络中 ,已减缓这个问题
策略学习
使用了策略网络 Π(..theata) = V(..theata)
一个蒙地卡罗+神经网络
PG = 一个蒙地卡罗+神经网络
策略网络图
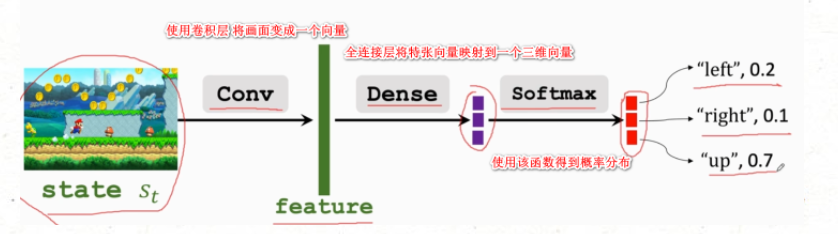
策略网络中可以用于连续和离散的动作


基于policy 学习的 BaseLine 这里unknown
收敛的更快
AC 架构
基本的AC
网格+SARAS
使用了actor 和critic 这两个网络 = 策略网络 Π(..theata)和 价值网络 q(..w)
-
AC 的训练总流程


-
Q网格的训练流程

-
Π网格的训练流程
