索引优化
有哪些维度可以进行数据库调优?
- 索引失效,没有充分利用到索引 --- 建立索引
- 关联查询join太多(设计缺陷或不得已的需求) --- SQL优化
- 服务器调优及各个参数的设计(缓冲、线程池等) --- 调整my.cnf
- 数据过多,SQL优化也到达了极限 --- 分库分表
SQL查询优化可以分为物理查询优化和逻辑查询优化:
- 物理查询优化:通过
索引和表连接的方式来进行优化 - 逻辑查询优化:通过SQL
等值变换提升查询效率,即换一种执行效率更高的sql写法
1 数据准备
创建表
CREATE TABLE `class` (
`id` INT(11) NOT NULL PRIMARY KEY AUTO_INCREMENT,
`class_name` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL PRIMARY KEY AUTO_INCREMENT,
`stu_no` INT NOT NULL,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`class_id` INT(11) DEFAULT NULL
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
两个随机函数
-- 函数返回随机字符串
DELIMITER //
CREATE FUNCTION `rand_string`(n INT) RETURNS varchar(255) CHARSET utf8mb4
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
-- rand_num
DELIMITER //
CREATE FUNCTION `rand_num`(from_num INT ,to_num INT) RETURNS int
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
创建存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT, max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit=0;
REPEAT
SET i = i + 1;
INSERT INTO student(stu_no, name, age, class_id) VALUES
((START+i), rand_string(6), rand_num(1, 50), rand_num(1, 1000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER;
DELIMITER //
CREATE PROCEDURE `insert_class` (max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class (class_name, address, monitor) VALUES
(rand_string(8), rand_string(10), rand_num(1, 100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER;
执行存储过程
CALL insert_class(10000);
CALL insert_stu(100000, 500000)
2 索引失效案例
索引是否使用最终都是由优化器决定的,优化器则是根据SQL执行开销cost来判断的。另外,SQL语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系。
数据选择度即如Select *需要使用大量聚簇索引进行回表
1 全值匹配
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND class_id = 4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND class_id = 4 AND NAME = 'abcd';
-- 0.147s
-- 0.053s 添加idx_age后
-- 0.037s idx_age_class_id
-- 0.032s idx_age_class_id_name
SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND class_id = 4 AND NAME = 'abcd';
CREATE INDEX idx_age ON student(age);
CREATE INDEX idx_age_class_id ON student(age, class_id);
CREATE INDEX idx_age_class_id_name ON student(age, class_id, name)
优化器会自动选择包含查询条件涉及列值较多的索引,因为这样可以减少回表操作,SQL语句的消耗较少。
2 最左前缀原则
针对联合索引的使用,过滤条件要使用索引,必须按照联合索引建立的顺序,依次满足,一旦跳过某个字段后面的字段都将无法使用,因为底层通过B+树存储,只能按照一个索引列的大小进行排列。
-- key : idx_age
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.name = 'abcd';
-- key : null
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.class_id = 30 AND student.name = 'abcd';
-- key : idx_age_class_id_name
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.name = 'abcd' AND student.class_id=18;
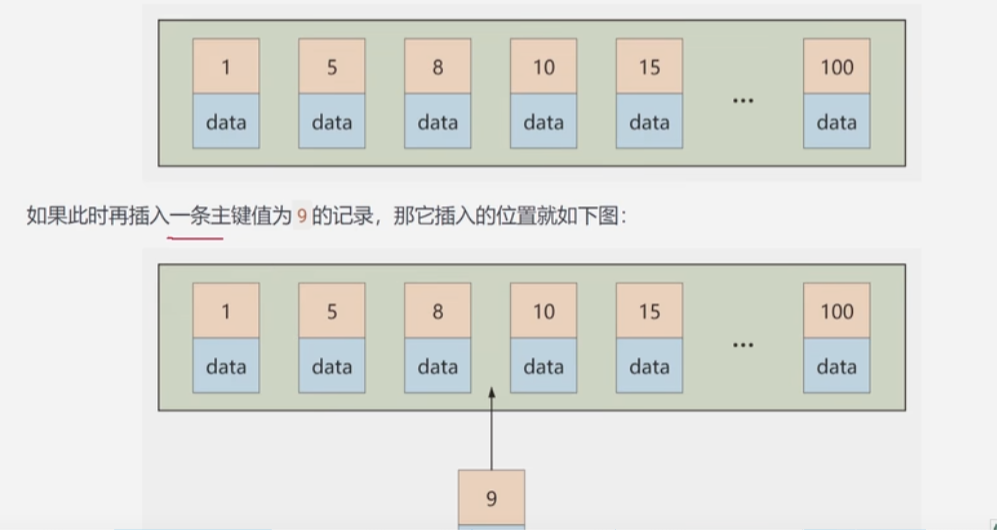
3 主键插入顺序
对于一个使用InnoDB存储引擎的表来说,表中的数据实际上是存储在聚簇索引的叶子节点上的,而记录又是存储在数据页中的,数据页和记录又是按照记录主键值从小到大的顺序进行排序,因此如果主键值是从小到大的顺序插入的话,就能插满一个数据页后继续插后面的数据页,而如果插入的主键值忽大忽小的话,就容易造成页的分裂和合并,浪费性能,如下所示,所以建议让主键具有AUTO_INCREMENT或者让存储引擎自己为表生成主键。
?4 计算、函数、类型转换(自动或者手动)导致索引失效
create index idx_name on student(name);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%'
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name, 3) = 'abc'
结果第一个查询用到了name索引,type为range
第二个查询没有用到,type为all
计算、函数、类型转换导致索引失效的原因是 需要先拿到每个索引列进行这些处理再判断,而不是直接使用索引进行二分查找,(也可以理解为处理后的结果无法使用创建的索引树进行二分查找)从而无法利用到索引。
CREATE INDEX idx_sno ON student(stu_no)
EXPLAIN SELECT * FROM student WHERE stu_no + 1 = 991;
EXPLAIN SELECT * FROM student WHERE stu_no = 990;
5 范围条件右边的列索引失效
首先删除已有的索引
SHOW INDEX FROM student
DROP INDEX idx_name ON student
DROP INDEX idx_sno ON student
然后创建一个新的索引,虽然下面的执行计划中用到了创建的索引,但是使用的索引的长度却有问题。索引长度为10,表示用到了age(int型长度为4null值列表1)+ class_id(int类型4字节null值列表1) = 10,也就是说没有用到name。
CREATE INDEX idx_age_claid_name ON student(age, class_id, name);
EXPLAIN SELECT * FROM student WHERE age = 30 AND class_id > 20 AND name = 'abc';

CREATE TABLE `student` (
`id` INT(11) NOT NULL PRIMARY KEY AUTO_INCREMENT,
`stu_no` INT NOT NULL,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`class_id` INT(11) DEFAULT NULL
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
使用联合索引的时候,查询条件为范围查询的右边的索引列会失效,原因是经过前一个条件范围查询的结果中的后一个列的值已经不是有序的了,因此不能够再继续使用二分查找,进而也就不能使用联合索引
变换查询的条件的顺序起不到作用,因为优化器会根据最左前缀原则自动调整顺序,问题的关键在于创建的联合索引的顺序。
因此创建将范围查询放在最后的索引能够解决问题:
CREATE INDEX idx_age_name_claid ON student(age, name, class_id);
EXPLAIN SELECT * FROM student WHERE age = 30 AND class_id > 20 AND name = 'abc';

编码集为utf8,varchar(20)代表20个字符即60个字节,再加null值列表1和变长长度列表2总共63
创建联合索引的时候,应该尽量将范围查询涉及到的字段写在最后面,如金额查询、日期查询等等
6 不等于(!= 或者 <>)索引失效
CREATE INDEX idx_name ON student(name)
EXPLAIN SELECT * FROM student WHERE name != 'abc'
不等于的条件下无法利用二分查找进而无法利用到索引,因此只能够一个个地看是否满足条件,因此explain的type为all
7 is null可以使用索引,is not null无法使用
EXPLAIN SELECT * FROM student WHERE name is NULL
EXPLAIN SELECT * FROM student WHERE name is NOT NULL
因此最好在设计数据库表的时候直接将字段设置NOT NULL约束,对于有null需求的字段可以设置零值,如int型为0,字符串为''表示null
同理在查询条件中使用not like也无法使用索引,会导致全表扫描
8 like 以%通配符开头索引失效
EXPLAIN SELECT * FROM student WHERE name like '%abc'
EXPLAIN SELECT * FROM student WHERE name like 'abc%'
开头模糊的话,B+树就没有办法进行二分查找也就无法利用索引了
ALIBABA开发手册中强制规定:
页面搜索严禁左模糊或者全模糊,如果有需要使用搜索引擎解决
9 OR前后存在非索引的列导致索引失效
EXPLAIN SELECT * FROM student WHERE name = 'abc' OR age = 10

name字段上存在索引而age字段是没有索引的,因此如果进行一次索引查找和一次全表查找,还不如直接进行一次全表查找的成本低
若再建立一个age的索引,则执行计划结果type为index_merge
CREATE INDEX idx_age ON student(age)
EXPLAIN SELECT * FROM student WHERE name = 'abc' OR age = 10
由于一个select执行使用一个索引,因此对于多个索引条件的情况会先遍历索引树取主键的并集然后进行回表操作
10 数据库和表的字符集统一使用utf8mb4
统一使用utf8mb4兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同字符集进行比较转换的话会造成索引失效。
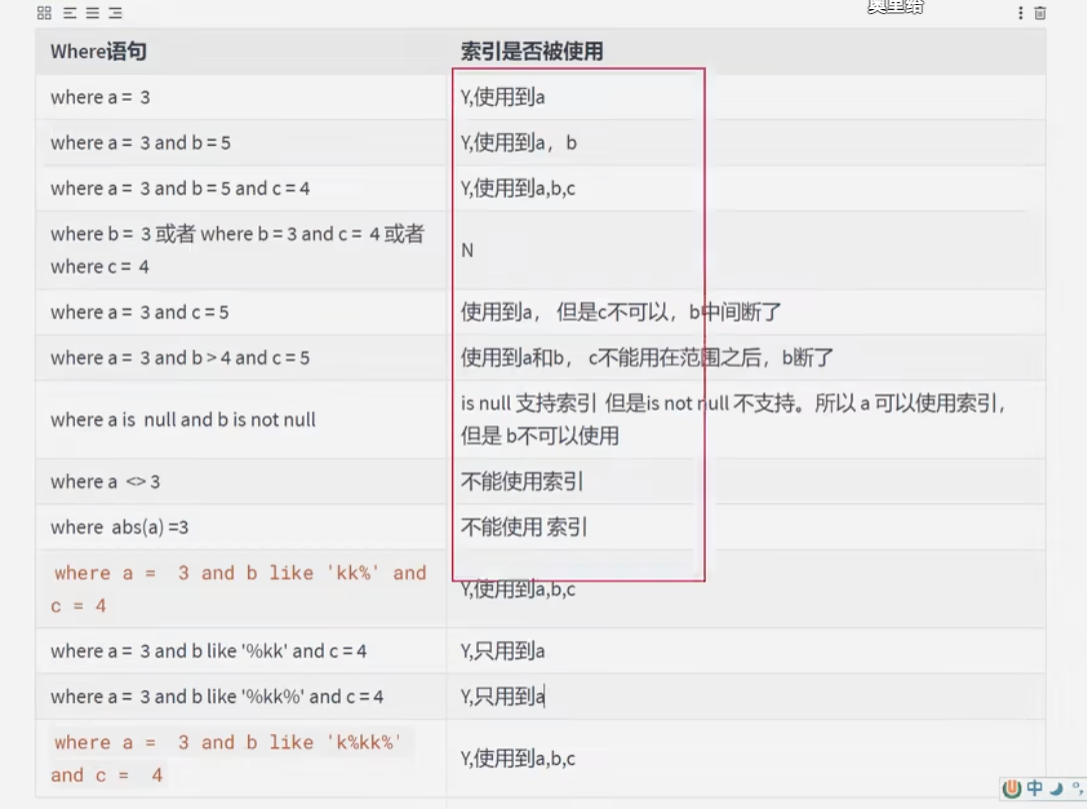
3 练习
index(a, b, c)
4 一般性建议
- 对于单列索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段的顺序中越靠前越好
- 在选择组合索引的时候,尽量选择能够包含当前query中的where字句的where条件更多字段的索引(优化器的工作)
- 在设计组合索引的时候,如果某个字段可能会出现范围查询,尽可能把这个字段放在索引次序的最后面