在各类网站采用了各种各样的反爬虫措施后,其中还有一种就是验证码反爬虫。那么如何将各种各样的验证码进行识别,自动化模拟人类操作验证码点击呢,那么今天我们就来聊一下。
在验证码反爬的类型中,主要有图形验证码(图形和数字随机组成)、点触验证码(词语或四字成语组成)和滑块验证码等。在如今,验证码类型逐渐复杂,难度高的同时也带来的许多相应对的技术。如OCR技术、OpenCV缺口验证码识别和打码平台识别验证码,在这里主要讲一下OCR中pytesseract识别文字的简单案例和打码平台识别验证码的方式解决点触验证码。
一、OCR识别文字
- OCR的文字识别,首先需要配置环境。
- 进入以下网址:http://digi.bib.uni-mannheim.de/tesseract/
- 下载最新版本tesseract v5.3.0.20221214
两个注意点:
1、在安装过程中可以勾选上 Additional language data 选项,安装 OCR 识别支持的语言包,这样 OCR 便可以识别多国语言。
2、配置环境变量,这里我安装到了E:如下:
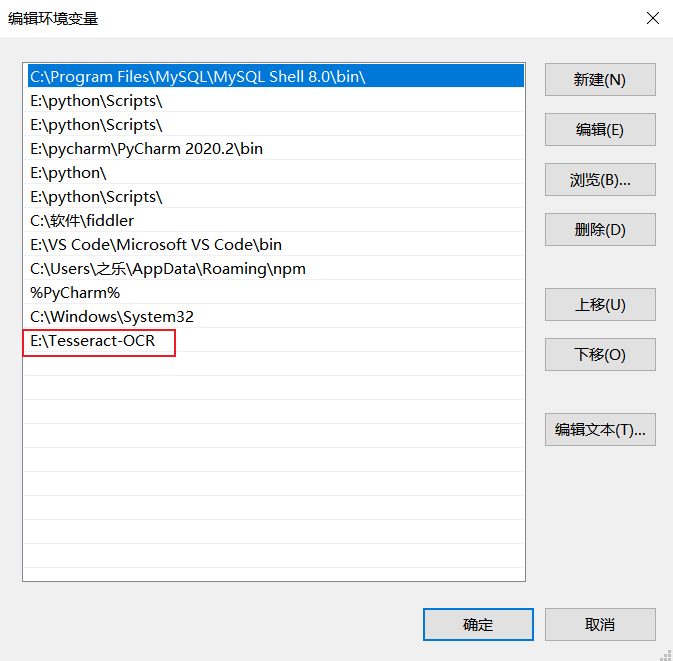
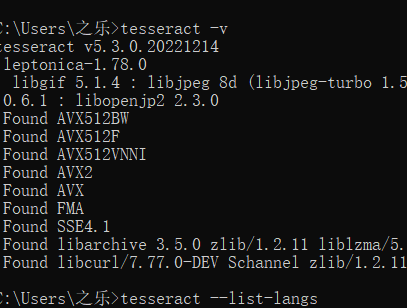
打开cmd输入tesseract -v查看版本号,出现版本号即安装成功。
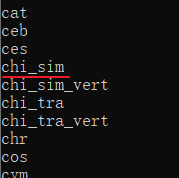
紧接着输入tesseract --list-langs,查看所包含的语言包。出现中文语言包chi_sim表示支持中文识别。
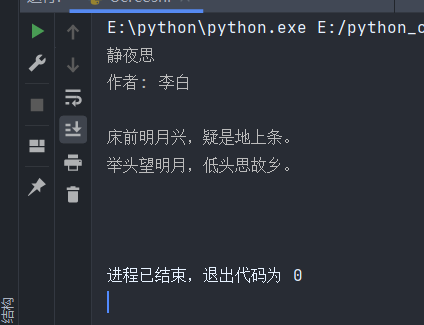
示例:
- 首先导入pytesseract包。
- 这里以此图为示例图。

- 这里没有进行灰度处理,想要精度识别可自行查阅。
import pytesseract
from PIL import Image
file=r"C:\Users\之乐\Desktop\诗词.webp"
image=Image.open(file)
# 如果识别数字,可以加上参数config="--psm 6 --oem 3 -c tessedit_char_whitelist=0123456789"
# 这里解析图片使用lang="chi_sim"表示识别简体中文,其默认为English
content=pytesseract.image_to_string(image,lang='chi_sim')
print(content)效果:
- 对于后续OCR点触验证吗的识别及环境安装可以阅读该篇文章:https://cuiqingcai.com/31102.html
二、点触验证码
今天解决的是点触类验证码的类型,以bilbili登录为例,所需要运用的库:selenium、requests、PIL。
首先我们来看一下验证码的样式:

废话不多说,我们来看一下主要的解决步骤:
1、打开网站、识别元素进行点击输入、登录至验证码验证。
- 定义一个登录类,打开登录网站,设置浏览器窗口大小,输入内容点击登录触发验证码。
class Login_Bibili(object):
def __init__(self):
self.driver = webdriver.Chrome()
self.wait = WebDriverWait(self.driver, 10)
self.url = "http://tulingtech.xyz/"
def chrome_settings(self):
self.driver.get("https://passport.bilibili.com/login")
# 设置浏览器打开的大小
self.driver.set_window_size(1100, 950)
time.sleep(1)
def login_search(self):
# 账号
self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="login-username"]'))
).send_keys("123456")
# 密码
self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="login-passwd"]'))
).send_keys("asdf")
# 登录
self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="geetest-wrap"]/div/div[5]/a[1]'))
).click()
time.sleep(1)2、截图,打开截图按照比例分别截取大图和小图。
- 所需要的图形下图所示:

那么首先,定义一个类,截图整体图片获取图片比例
def save_img(self):
# 根据时间戳命名截图的名字
image_name = str(int(time.time() * 1000)) + ".png"
# 判断该路径内是否有“Image_Small”和"Image_Big"两个文件夹
# 若没有这两个文件夹,则创建。
if not os.path.exists("Image_Small"):
os.mkdir("Image_Small")
if not os.path.exists("Image_Big"):
os.mkdir("Image_Big")
time.sleep(2)
# 当前打开的页面截图
# 根据浏览器的大小进行截图,截图后,命名yzm.png为图片名
self.driver.save_screenshot("yzm.png")
# 打开yzm.png的图片,取其值
# 打开yzm.png图片,获取其元组值,如:(1359, 939)
width = Image.open("yzm.png").size[0]
# 取该图片的宽度值,进行比例缩放,缩放比为1100
strech_rate = width / 1100其次,打开yzm.png图片,通过win10自带的画图工具获取大概的图片位置。
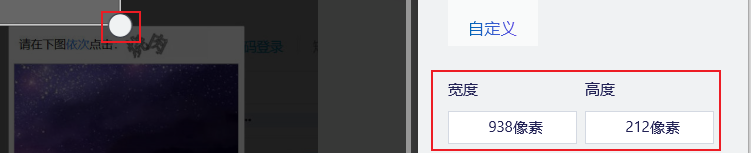
选择裁剪工具分别获取图片大概位置的两个点。
注意:图片的截取只需要获取两个对称点即可(图片左上和右下两个点)。
左上
右下
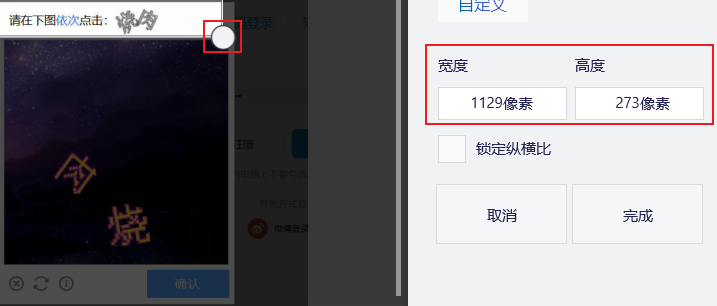
然后,按照截图的参差进行调整截取。
img = Image.open("yzm.png")
# 在yzm.png图片中截图,需要分别截取大图和小图
# 根据坐标截图,保存小图在Image_Small文件夹
cropped = img.crop((795 * strech_rate, 242 * strech_rate, 920 * strech_rate, 285 * strech_rate))
cropped.save("Image_Small/" + image_name)
# 根据坐标截图,保存大图在Image_Big文件夹
# 具体移动图片位置,可以想象成图片在坐标轴的第四象限(不带正负号)
cropped = img.crop((665 * strech_rate, 286 * strech_rate, 920 * strech_rate, 540 * strech_rate))
cropped.save("Image_Big/" + image_name)
time.sleep(1.5)3、通过打码平台获取每个字的坐标,根据坐标依次点击对应汉字样式。
- 这里就以图灵打码平台为例。
- 选取对应验证码的样式,调用打码平台的API进行获取图中字体的坐标值。
# 复制以下代码,只需填入自己的账号密码、待识别的图片路径即可。
# 关于ID:选做识别的模型ID。
# 通过大码平台进行验证码识别,然后返回获取的值
def b64_api(username, password, img_path, ID):
with open(img_path, 'rb') as f:
b64_data = base64.b64encode(f.read())
b64 = b64_data.decode()
data = {"username": username, "password": password, "ID": ID, "b64": b64, "version": "3.1.1"}
data_json = json.dumps(data)
result = json.loads(requests.post("http://www.tulingtech.xyz/tuling/predict", data=data_json).text)
return result
# 小图
# 打开小图图片,识别内容,
img_path = "Image_Small/" + image_name
result_small = b64_api(username=username, password=password, img_path=img_path, ID='02156188')
print(image_name)
print(img_path)
print(result_small)
print(result_small["message"])
# 取值,获取文字内容
result_small1 = result_small['data']['result']
print("result_small:", result_small1)
# 大图
# 打开大图图片,识别内容。
img_path = "Image_Big/" + image_name
result_big = b64_api(username=username, password=password, img_path=img_path, ID='05156485')- 最后,根据结果循环点击即可。
# 找到验证码中“请在下图依次点击”字体,点击元素,找到class值,根据class值进行目标定位。
class_name = "geetest_tip_content"
elment = self.driver.find_element(By.CLASS_NAME, class_name)
# 根据小图的字数,确定循环的次数
for i in range(0, len(result_small1)):
# 在大图中找到跟小图相对应到的字体。
result = result_big["data"][result_small1[i]]
# 动作链:根据大图中相应字体的坐标值,进行点击
ActionChains(self.driver).move_to_element(elment).move_by_offset(
-60 + int(result["X坐标值"] / strech_rate),
20 + int(result["Y坐标值"] / strech_rate)).click().perform()
# 点一次睡眠一秒
time.sleep(1)
print(result_small["message"])4、完整代码
- 这里我用ConfigParser进行获取账号密码,大家可以直接在调用函数上传入即可。
- 完整代码示例如下:
import base64
import json
import requests
import time
from PIL import Image
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
from configparser import ConfigParser
from selenium.webdriver import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
cfg = ConfigParser()
cfg.read("data_user_pwd.ini")
username = cfg.get("username", "username")
password = cfg.get("password", "password")
print(type(username), type(password))
class Login_Bibili(object):
def __init__(self):
self.driver = webdriver.Chrome()
self.wait = WebDriverWait(self.driver, 10)
self.url = "http://tulingtech.xyz/"
def chrome_settings(self):
self.driver.get("https://passport.bilibili.com/login")
# 设置浏览器打开的大小
self.driver.set_window_size(1100, 950)
time.sleep(1)
def login_search(self):
# 账号
self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="login-username"]'))
).send_keys("123456")
# 密码
self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="login-passwd"]'))
).send_keys("asdf")
# 登录
self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="geetest-wrap"]/div/div[5]/a[1]'))
).click()
time.sleep(1)
# 保存图片
def save_img(self):
# 根据时间戳命名截图的名字
image_name = str(int(time.time() * 1000)) + ".png"
# 判断该路径内是否有“Image_Small”和"Image_Big"两个文件夹
# 若没有这两个文件夹,则创建。
if not os.path.exists("Image_Small"):
os.mkdir("Image_Small")
if not os.path.exists("Image_Big"):
os.mkdir("Image_Big")
time.sleep(2)
# 当前打开的页面截图
# 根据浏览器的大小进行截图,截图后,命名yzm.png为图片名
self.driver.save_screenshot("yzm.png")
# 打开yzm.png的图片,取其值
# 打开yzm.png图片,获取其元组值,如:(1359, 939)
width = Image.open("yzm.png").size[0]
# 取该图片的宽度值,进行比例缩放,缩放比为1100
strech_rate = width / 1100
img = Image.open("yzm.png")
# 在yzm.png图片中截图,需要分别截取大图和小图
# 根据坐标截图,保存小图在Image_Small文件夹
cropped = img.crop((795 * strech_rate, 242 * strech_rate, 920 * strech_rate, 285 * strech_rate))
cropped.save("Image_Small/" + image_name)
# 根据坐标截图,保存大图在Image_Big文件夹
# 具体移动图片位置,可以想象成图片在坐标轴的第四象限(不带正负号)
cropped = img.crop((665 * strech_rate, 286 * strech_rate, 920 * strech_rate, 540 * strech_rate))
cropped.save("Image_Big/" + image_name)
time.sleep(1.5)
# 复制以下代码,只需填入自己的账号密码、待识别的图片路径即可。
# 关于ID:选做识别的模型ID。
# 通过大码平台进行验证码识别,然后返回获取的值
def b64_api(username, password, img_path, ID):
with open(img_path, 'rb') as f:
b64_data = base64.b64encode(f.read())
b64 = b64_data.decode()
data = {"username": username, "password": password, "ID": ID, "b64": b64, "version": "3.1.1"}
data_json = json.dumps(data)
result = json.loads(requests.post("http://www.tulingtech.xyz/tuling/predict", data=data_json).text)
return result
# 小图
# 打开小图图片,识别内容,
img_path = "Image_Small/" + image_name
result_small = b64_api(username=username, password=password, img_path=img_path, ID='02156188')
print(image_name)
print(img_path)
print(result_small)
print(result_small["message"])
# 取值,获取文字内容
result_small1 = result_small['data']['result']
print("result_small:", result_small1)
# 大图
# 打开大图图片,识别内容。
img_path = "Image_Big/" + image_name
result_big = b64_api(username=username, password=password, img_path=img_path, ID='05156485')
print("result_big:", result_big)
# 找到验证码中“请在下图依次点击”字体,点击元素,找到class值,根据class值进行目标定位。
class_name = "geetest_tip_content"
elment = self.driver.find_element(By.CLASS_NAME, class_name)
# 根据小图的字数,确定循环的次数
for i in range(0, len(result_small1)):
# 在大图中找到跟小图相对应到的字体。
result = result_big["data"][result_small1[i]]
# 动作链:根据大图中相应字体的坐标值,进行点击
ActionChains(self.driver).move_to_element(elment).move_by_offset(
-60 + int(result["X坐标值"] / strech_rate),
20 + int(result["Y坐标值"] / strech_rate)).click().perform()
# 点一次睡眠一秒
time.sleep(1)
print(result_small["message"])
# 处理验证码
# 点击确认
self.wait.until(
EC.presence_of_element_located((By.CLASS_NAME, 'geetest_commit_tip'))
).click()
time.sleep(15)
if __name__ == '__main__':
login = Login_Bibili()
login.chrome_settings()
login.login_search()
login.save_img()
time.sleep(20)PS:图灵打码平台的识别率在80%左右,较为繁杂的字体可能会有识别误差。
注:后续更新滑块验证码...