为什么阿里巴巴禁止使用 count(列名)或 count(常量)来替代 count(*)-阿里云开发者社区 (aliyun.com)
1.关于数据库中统计行数,无论是MySQL还是Oracle,都有只有一个函数可以使用,就是count
count(*) :统计的结果中,包含值为NULL的行数,
count(1):统计的结果中,包含值为NULL的行数
count(字段):统计的结果中,不包含为NULL的行数
2.除了查询得到的结果集有区别之外,count(*)相比于count(1)和count(字段)来讲,count(*) 是SQL92定义的标准统计行数的语法,因为他是标准语法,所以mysql数据库对它进行过很多优化。
那count(*)进行了哪些优化呢?
针对不同的执行引擎,mysql中比较常用的执行引擎是InnoDB和MyISAM。
MyISAM不支持事务,MyISAM中的锁是表级锁,InnoDB支持事务,并且支持行级锁
因为MyISAM的锁是表级锁,所以同一张表上面的操作就需要串行进行,所以,MyISAM做了一个简单的优化,把表的总行数单独记录下来,如果从一张表使用count(*)进行查询的时候,可以直接返回这个记录下来的数值,但是不能有where条件。MyISAM之所以可以把表中的总行数记录下来供count(*)查询使用,是因为MyISAM数据库是表级锁,不会有并发的数据库行数修改,所以查询到的行数是准确的。
但是对于InnoDB来说,就不能做这种缓存操作了,因为InnDB支持事务,其中大部分操作都是行级锁,所以表的行数可能会被并发修改,那么缓存记录下来的行数就不准确了。
所以InnoDB针对count(*)做的优化是:在InnoDB中使用count(*)查询数据的时候,不可避免的要进行扫表了。从MySQL 8.0.13开始,针对InnoDB中的select count(*) from table_name,在表中做了些优化,前提也是查询语句中不包含where和group by等条件。count(*)在扫表的过程中,选择一个成本较低的索引进行的话,可以大大节省时间。
聚族索引中保存的是整行记录,非聚族索引中的叶子节点中保存的是该行记录的主键的值,所以非聚族索引会比聚族索引小很多,所以mysql会优先选择最小的非聚族索引来扫表,所以建表的时候,除了主键索引之外,创建一个非聚族索引也很有必要。
3.count(*)和count(1) ,mysql的优化是完全一样的,根本不存在谁比谁快,建议使用count(*),
count(字段)的查询比较粗暴,就是要进行全表扫表,然后判断字段是不是为null,不为null则累加,所以多了一个检查null的步骤,所以性能比count(*) 慢。
学完上面的突然想到上次工作中碰到的一个问题。
select count(1) from 360_fzcl_001
GROUP BY PUR_GRP,PO_YEAR,MAT_TYPE,ORDER_TYPE,SEASONS,CHANNEL_TYPE,VENDOR_NAME,SOURCE_P_CODE,MAT_F1_DISPLAY,CY_VENDOR_NAME
select count(distinct m.`PUR_GRP`, m.`PO_YEAR`, m.`MAT_TYPE`, m.`ORDER_TYPE`, m.`SEASONS`, m.`CHANNEL_TYPE`, m.`VENDOR_NAME`, m.`SOURCE_P_CODE`, m.`MAT_F1_DISPLAY`, m.`CY_VENDOR_NAME`) as recordsTotal from `360_fzcl_001` as m
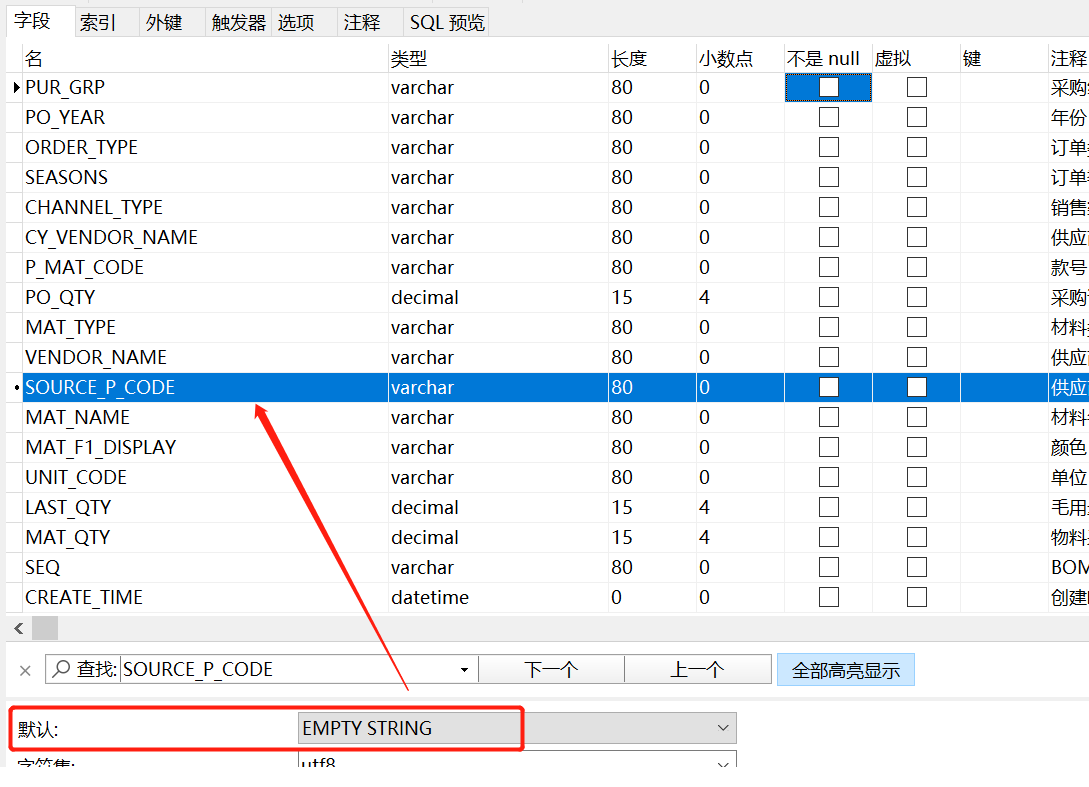
这两段SQL查询的行数不太一样。就是因为count(字段) 不统计包含null的数据,所以会比count(1)少一点,但是由于后台代码写死的限定,实现的方式只能使用count(字段),
所以最后的解决办法是建表的时候,让有些字段的值默认不为NULL,而是为空字符串,最后解决了这个问题。
ps:
