numpy读取不了字符串,pandas比较方便
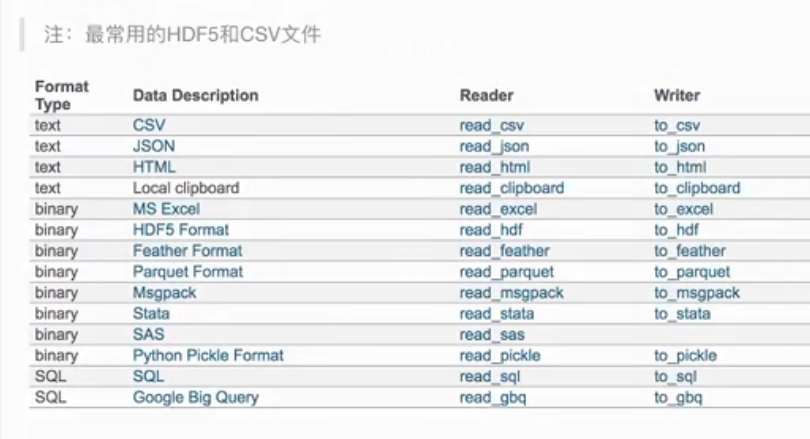
常用
csv 通常读取文本文件
hdf5 通常读取二进制
Json
1.读取CSV
read_csv()
1.读取CSV文件-read_csv()
pandas.read_csv(filepath_or_buffer, sep =',' ,usecols=[], delimiter = None)
filepath_or_buffer:文件路径
usecols:指定读取的列名,列表形式,就是只读取我们需要的字段
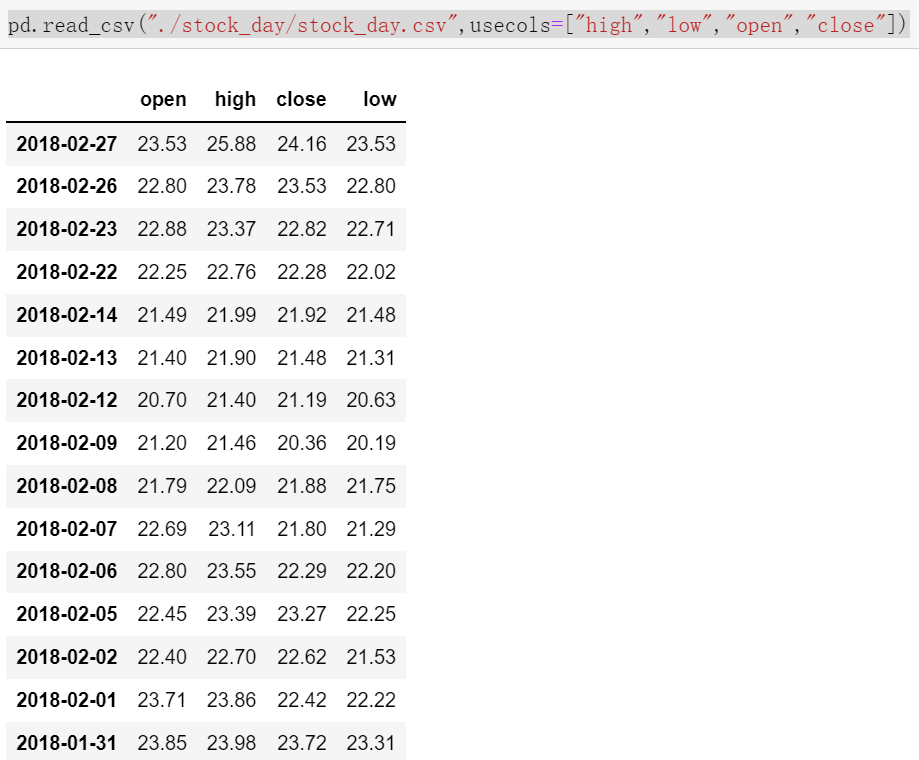
pd.read_csv("./stock_day/stock_day.csv",usecols=["high","low","open","close"])
如果读取的文件没有字段的话,就是没有open,high.....直接是数据,这样需要names字段
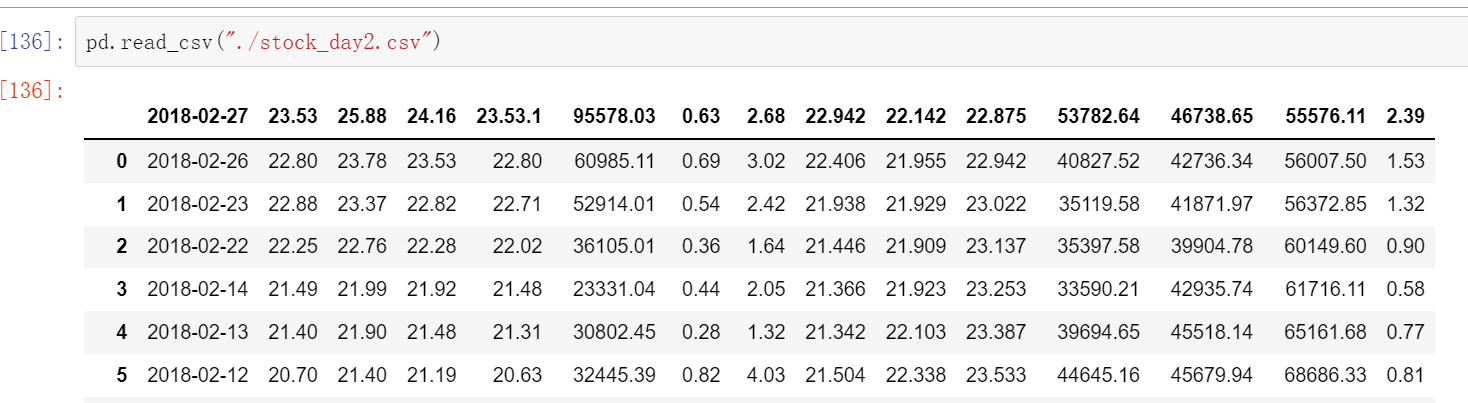
pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])

2.写入CSV文件:datafram.tocsv()
DataFrame.to_csv(path_or_buf=None,sep=',',columns=None,header=True,index=True,index_label=None,mode='w',encoding=None)
o path_or_buf:string or file handle, default None
o sep:character,default','
o columns :sequence, optionalo mode:'w':重o, 'a'追加
o index:是否保存行索引
o header:boolean or list of string, default True,是否写进列索引值
Series.to_csv(path=None,index=True,sep=',',na_rep=",float_format=None,header=False,index_label=None,mode='w',encoding=None,compression=None,date_format=None, decimal='.')
Write Series to a comma-separated values (csv) file
案例保存'open'列的数据
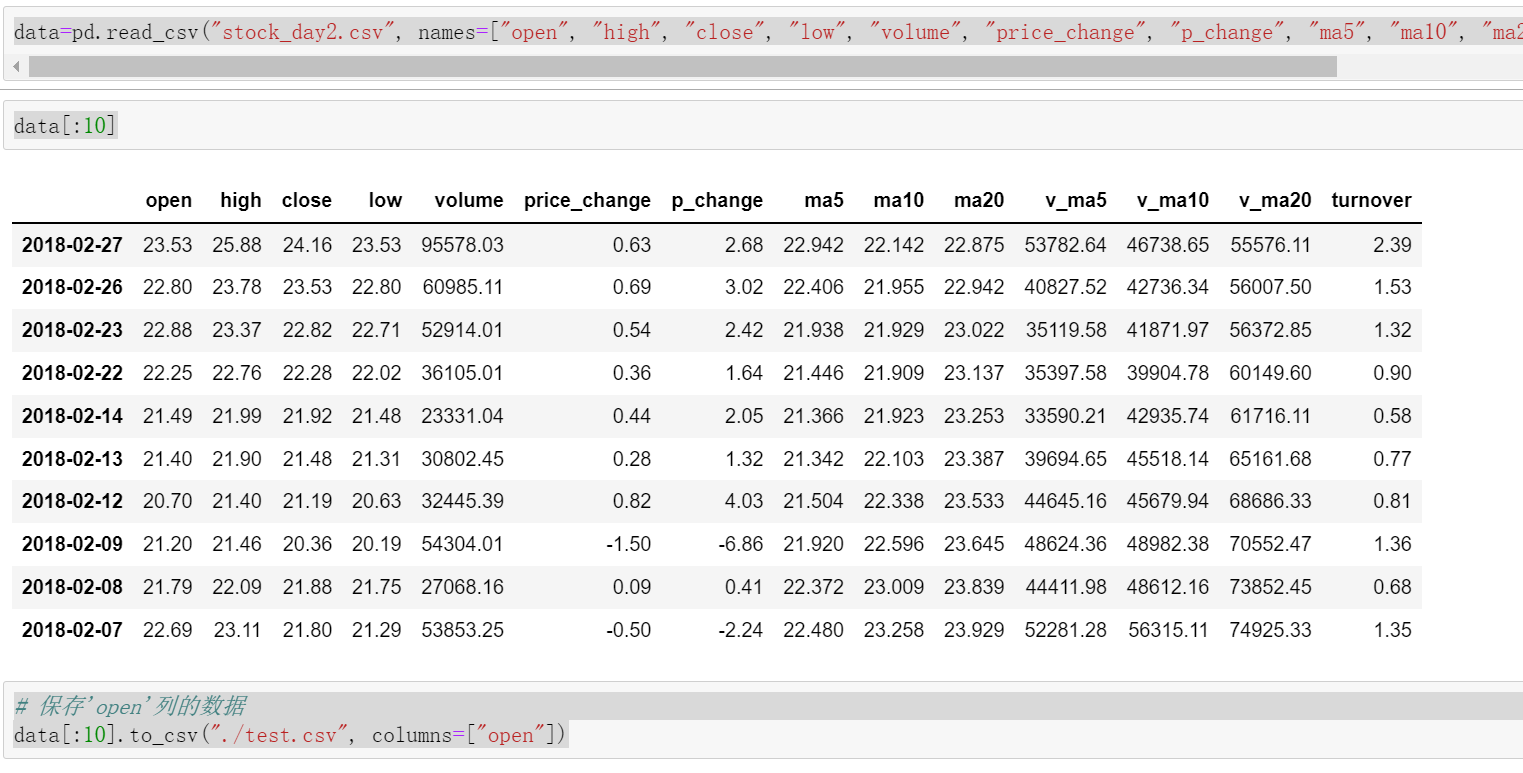
data=pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])
# 保存'open'列的数据
data[:10].to_csv("./test.csv", columns=["open"])
2.读取HDF5
read_hdf()
hdf5 存储 3维数据的文件
key1 dataframe1二维文件
key2 dataframe2二维文件
2.1 read_hdf()
read_hdf()与 to_hdf()
HDF5 文件的读取和存储需要指定一个键,值为要存储的 DataFrame
pandas.read_hdf(path_or_buf, key=None, **kwargs)
从 h5 文件当中读取数据
path_or_buffer: 文件路径
key: 读取的键
mode: 打开文件的模式
reurn: The Selected object
DataFrame.to_hdf(path_or_buf, key, **kwargs)
读入
day_close = pd.read_hdf("./stock_data/day/day_close.h5")
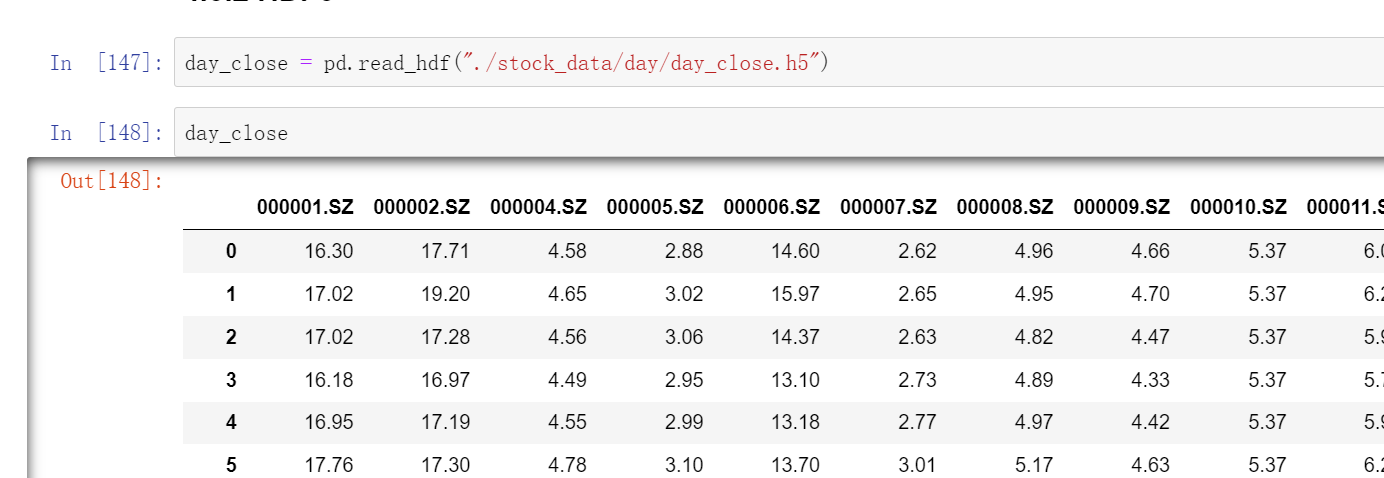
如果读取完再写入的话(多个key时)
day_close.to_hdf("test.h5", key="close")
#这个时候key只设置了一个,所以再读的时候可以不用加key,加上也可以
pd.read_hdf("test.h5", key="close").head()
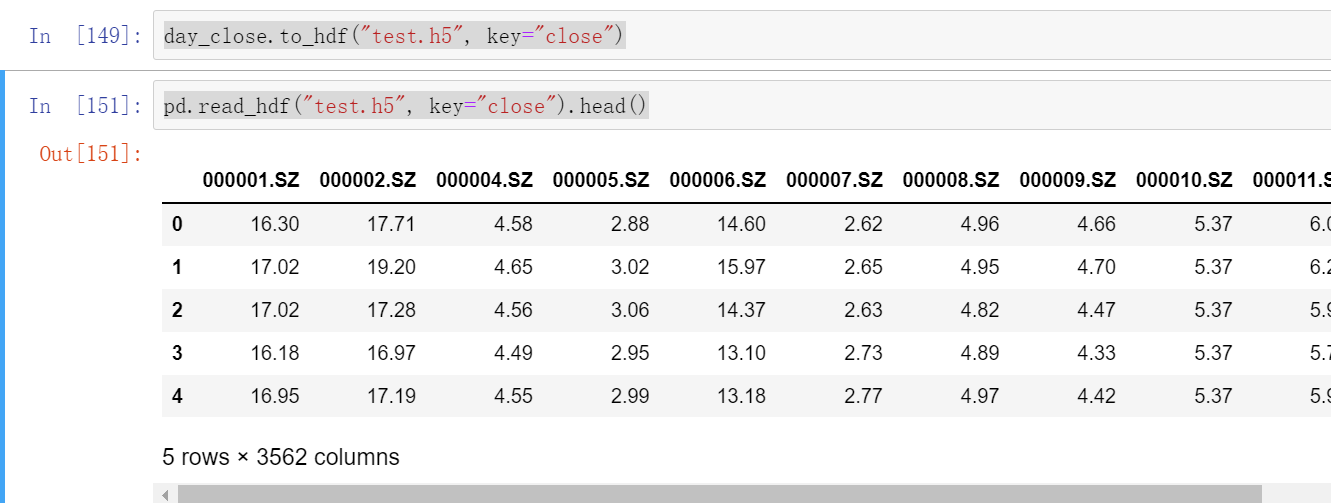
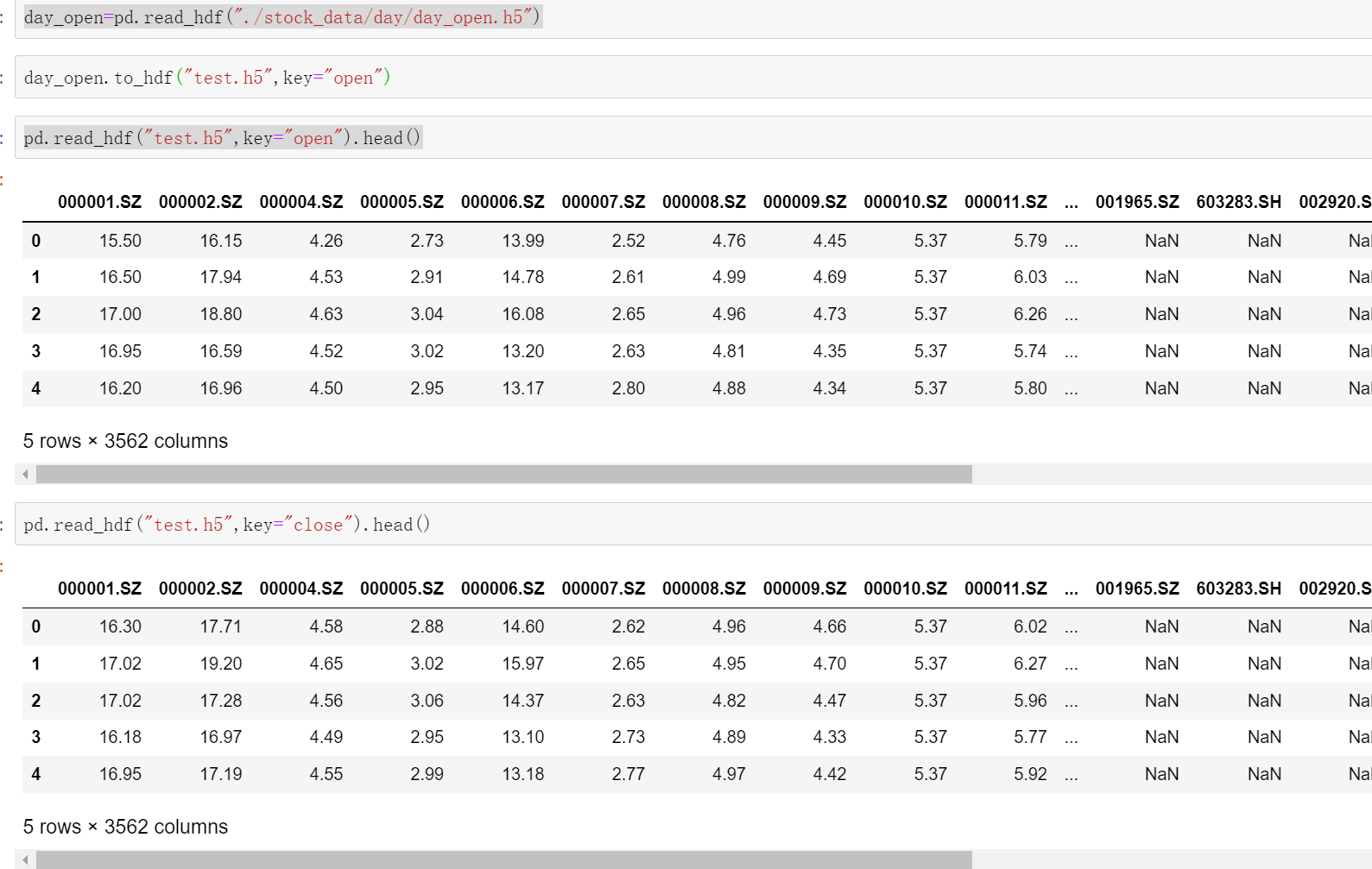
#我们再读取一个然后再保存到test.h5中,这是换一个key
day_open=pd.read_hdf("./stock_data/day/day_open.h5")
day_open.to_hdf("test.h5",key="open")
#然后test.h5中就有了"close"和"open"这两个key,如果我们再次读这个test.h5时不加key会报错
pd.read_hdf("test.h5",key="open").head()
pd.read_hdf("test.h5",key="close").head()
3.读取Json
read_json()
pandas.read_json(path_or_buf=None,orient="records",typ="frame",lines=True)
将 JSON 格式转换成默认的Pandas DataFrame格式
orient: string,Indication of expected JSON string format.写="records"
'split': dict like {index -> [index], columns -> [columns], data -> [values]}
'records': list like [{column -> value}, ..., {column -> value}]
'index': dict like {index -> {column -> value}}
'columns': dict like {column -> {index -> value}}, 默认该格式
'values': just the values array
lines: boolean, default False,一般写True
按照每行读取 json 对象
typ: default 'frame',指定转换成的对象类型 series 或者 dataframe
读出
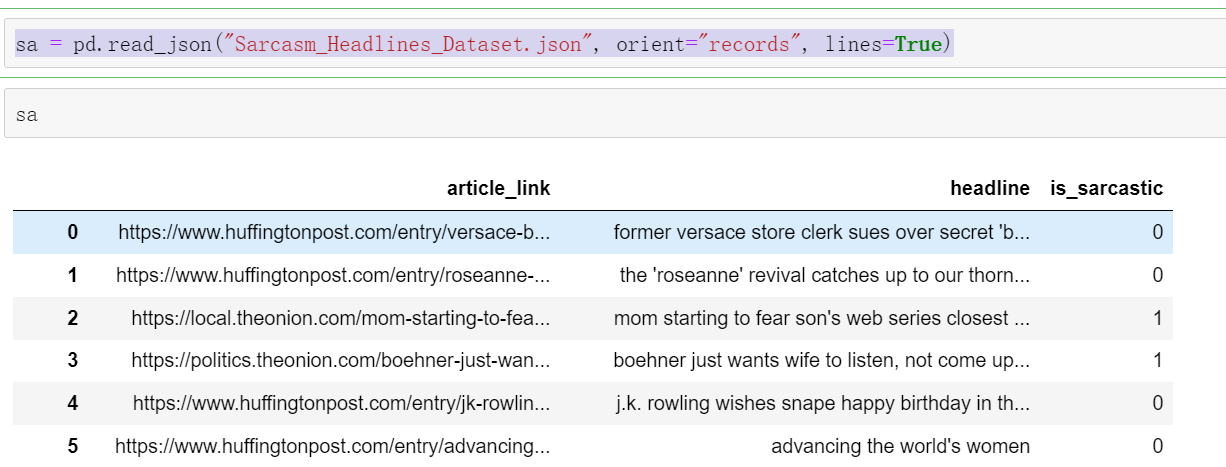
sa = pd.read_json("Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
sa
#读取完之后是一个Datafram类型的文件
写入
sa.to_json("test.json",orient="records",lines=True)
补充:
这个文件./是当前路径