数据采集与融合技术实践作业四
第三次作业
-
作业1:
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
代码如下所示
import mysql.connector
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 数据库配置
conn = mysql.connector.connect(
host='localhost',
user='root',
password='123456',
database='stock_db'
)
cursor = conn.cursor()
# 创建表
cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(255),
stock_name VARCHAR(255),
latest_price VARCHAR(255),
change_rate VARCHAR(255),
change_amount VARCHAR(255),
transaction_volume VARCHAR(255),
transaction_amount VARCHAR(255),
amplitude VARCHAR(255),
highest VARCHAR(255),
lowest VARCHAR(255),
today VARCHAR(255),
yesterday VARCHAR(255)
)
""")
browser = webdriver.Edge()
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
browser.get(url)
count=1
for i in range(3):
button=browser.find_elements(By.XPATH,'//*[@id="tab"]/ul/li')[i].find_element(By.XPATH,'./a')
button.click()
time.sleep(5) # 等待页面加载完成
browser.refresh()
# 定位到tbody
tbody = browser.find_element(By.XPATH, '//*[@id="table_wrapper-table"]/tbody')
# 迭代每一行
rows = tbody.find_elements(By.XPATH, './/tr')
for row in rows:
# 使用XPath获取每个单元格的数据,并且进行清理和格式化
stock_code = row.find_element(By.XPATH, './td[2]').text
stock_name = row.find_element(By.XPATH, './td[3]').text
latest_price = row.find_element(By.XPATH, './td[5]/span').text
change_rate = row.find_element(By.XPATH, './td[6]/span').text
change_amount = row.find_element(By.XPATH, './td[7]/span').text
transaction_volume = row.find_element(By.XPATH, './td[8]').text
transaction_amount = row.find_element(By.XPATH, './td[9]').text
amplitude = row.find_element(By.XPATH, './td[10]').text
highest = row.find_element(By.XPATH, './td[11]/span').text
lowest = row.find_element(By.XPATH, './td[12]/span').text
today = row.find_element(By.XPATH, './td[13]/span').text
yesterday = row.find_element(By.XPATH, './td[14]').text
cursor.execute("""
INSERT INTO stocks (stock_code, stock_name, latest_price, change_rate, change_amount, transaction_volume, transaction_amount, amplitude, highest, lowest, today, yesterday)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (
stock_code, stock_name, latest_price, change_rate, change_amount, transaction_volume, transaction_amount, amplitude,
highest, lowest, today, yesterday))
conn.commit() # 提交事务
browser.quit()
# 关闭数据库连接
cursor.close()
conn.close()
- 用Navicat可视化爬取到的数据,三个模块的数据存放在一起
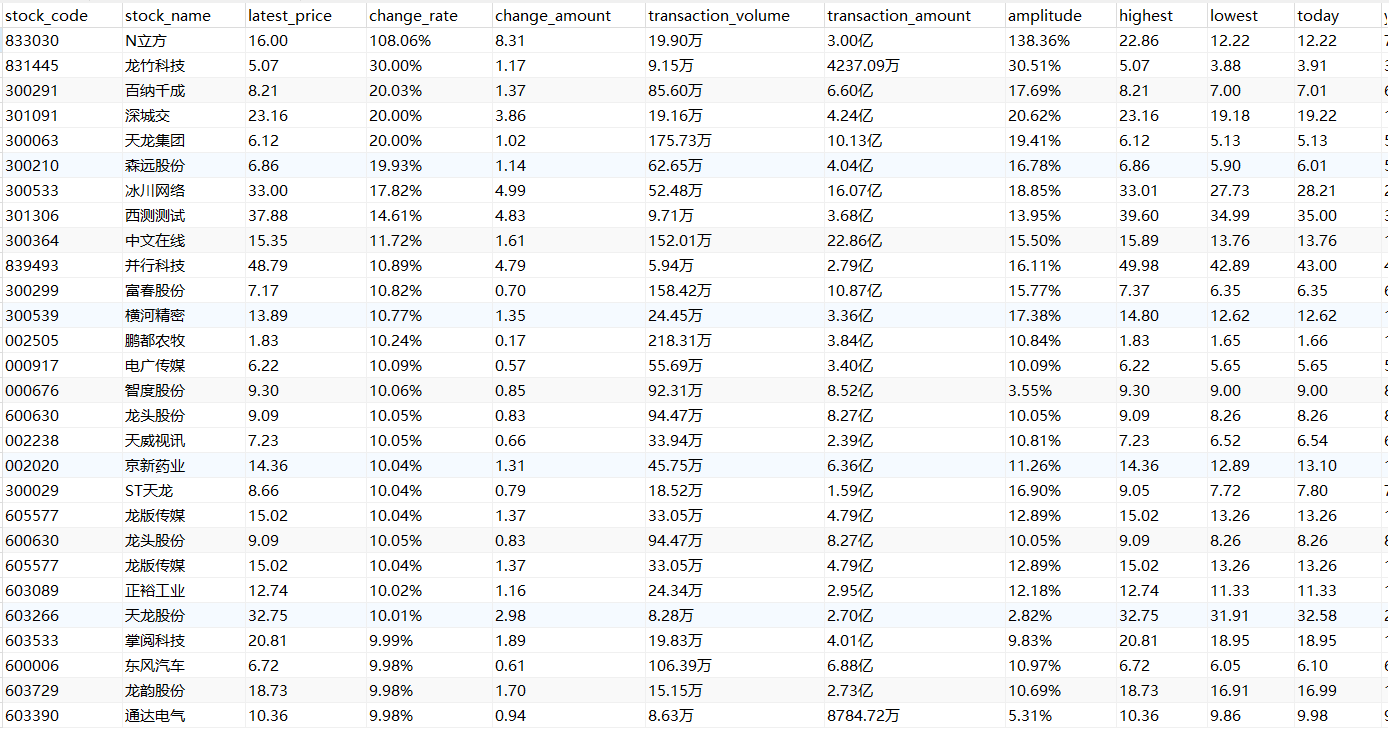
-
心得体会:
与之前的任务类似,这次使用selenium较为容易的可以爬取到数据,模块之间的转换只需要模拟人工操作浏览器,找到对应的xpath,click相关的滑块即可。
-
作业二:
-
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
-
候选网站:中国mooc网
-
下面是文件代码
import mysql.connector
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 数据库配置
conn = mysql.connector.connect(
host='localhost',
user='root',
password='123456',
database='mysql'
)
cursor = conn.cursor()
# 创建表
cursor.execute("""
CREATE TABLE IF NOT EXISTS curriculums_1 (
id INT AUTO_INCREMENT PRIMARY KEY,
course VARCHAR(255),
college VARCHAR(255),
teacher VARCHAR(255),
team VARCHAR(255),
brief VARCHAR(255),
Ccount VARCHAR(255),
process VARCHAR(255)
)
""")
url='https://www.icourse163.org/'
browser=webdriver.Edge()
browser.get(url)
button=browser.find_element(By.XPATH,'//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
button.click()
time.sleep(3)
browser.switch_to.default_content()
browser.switch_to.frame(browser.find_elements(By.TAG_NAME,'iframe')[0])
time.sleep(2)
name_input=browser.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')
time.sleep(2)
pass_input=browser.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
username = "18959805256" # 这里换成自己的账号
password = "She20031219" ##这里换成自己的密码
name_input.clear()
name_input.send_keys(username) # 填写账号
time.sleep(0.2) # 休眠一下,模拟人工登录,不然可能被拦截
pass_input.clear()
pass_input.send_keys(password) # 填写密码
time.sleep(0.2)
login_button=browser.find_element(By.XPATH,'//*[@id="submitBtn"]')
login_button.click() # 点击登录
time.sleep(8)
browser.switch_to.default_content()
input_curriculum=browser.find_element(By.XPATH,'/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')
time.sleep(5)
input_curriculum.send_keys('python')
browser.switch_to.default_content()
dianji=browser.find_element(By.XPATH,'/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[2]/span')
dianji.click()
for i in range(3):
contents = browser.find_elements(By.XPATH,'/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div')
for content in contents:
try:
course=content.find_element(By.XPATH,'./div[2]/div/div/div[1]/a/span').text
college=content.find_element(By.XPATH,'./div[2]/div/div/div[2]/a[1]').text
teacher = content.find_element(By.XPATH, './div[2]/div/div/div[2]/a[2]').text
team=content.find_element(By.XPATH, './div[2]/div/div/div[2]/span/span').text
brief=content.find_element(By.XPATH,'./div[2]/div/div/a/span').text
Ccount=content.find_element(By.XPATH,'./div[2]/div/div/div[3]/span[2]').text
process=content.find_element(By.XPATH,'./div[2]/div/div/div[3]/div/span[2]').text
cursor.execute("""
INSERT INTO curriculums_1(course, college, teacher, team, brief, Ccount,process)
VALUES( %s, %s, %s, %s, %s, %s, %s)
""", (
course, college, teacher, team, brief, Ccount, process))
conn.commit() # 提交事务
print(course,college,teacher,team,brief,Ccount,process)
except:
continue
next_button=browser.find_element(By.XPATH,'/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[2]/ul/li[10]/a')
next_button.click()
time.sleep(2)
browser.quit()
# 关闭数据库连接
cursor.close()
conn.close()
- Navicat可视化查看爬取到的数据

-
心得体会:
需要switch_to.frame()转换窗口,否则无法模拟登录,登录后我搜索python相关的课程,爬取出数页python课程的数据。
-
作业三:
-
要求:掌握大数据相关服务,熟悉Xshell的使用完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
-
环境搭建:
-
任务一:开通MapReduce服务
-
实时分析开发实战:
-
任务一:Python脚本生成测试数据
-
任务二:配置Kafka
-
任务三: 安装Flume客户端
-
任务四:配置Flume采集数据
• 环境搭建:
·任务一:开通 MapReduce 服务
• 实时分析开发实战:
·任务一:Python 脚本生成测试数据

·任务二:配置 Kafka

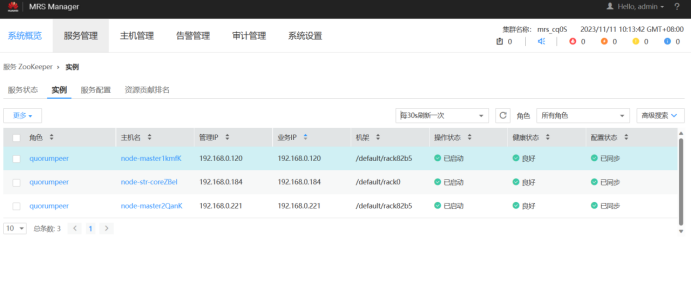

·任务三: 安装 Flume 客户端
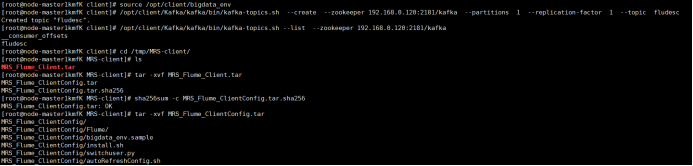



·任务四:配置 Flume 采集数据
输出:实验关键步骤或结果截图。

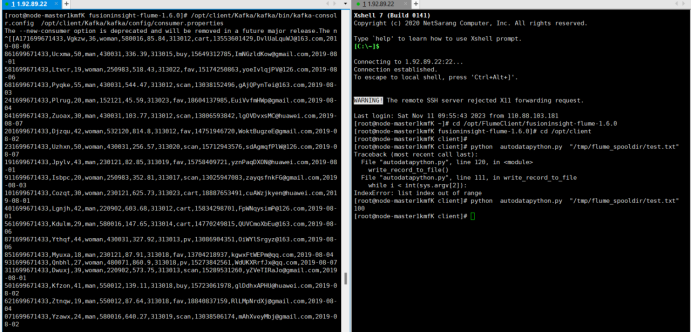
-
心得体会