https://www.hello-algo.com/
算法
- 算法在日常生活中无处不在,并不是遥不可及的高深知识。实际上,我们已经在不知不觉中学会了许多算法,用以解决生活中的大小问题。
- 查阅字典的原理与二分查找算法相一致。二分查找算法体现了分而治之的重要算法思想。
- 整理扑克的过程与插入排序算法非常类似。插入排序算法适合排序小型数据集。
- 货币找零的步骤本质上是贪心算法,每一步都采取当前看来的最好的选择。
- 算法是在有限时间内解决特定问题的一组指令或操作步骤,而数据结构是计算机中组织和存储数据的方式。
- 数据结构与算法紧密相连。数据结构是算法的基石,而算法则是发挥数据结构作用的舞台。
- 我们可以将数据结构与算法类比为拼装积木,积木代表数据,积木的形状和连接方式代表数据结构,拼装积木的步骤则对应算法
复杂度分析
时间 空间
时间效率:算法运行速度的快慢。
空间效率:算法占用内存空间的大小。
for循环
适合预先知道迭代次数时使用 python中的range是左闭右开
while循环
比for循环更自由
for循环更加紧凑,while循环更加自由
「递归 recursion」是一种算法策略,通过函数调用自身来解决问题。它主要包含两个阶段。
- 递:程序不断深入地调用自身,通常传入更小或更简化的参数,直到达到“终止条件”。
- 归:触发“终止条件”后,程序从最深层的递归函数开始逐层返回,汇聚每一层的结果。
而从实现的角度看,递归代码主要包含三个要素。
- 终止条件:用于决定什么时候由“递”转“归”。
- 递归调用:对应“递”,函数调用自身,通常输入更小或更简化的参数。
- 返回结果:对应“归”,将当前递归层级的结果返回至上一层。
递归通常比迭代更加耗费内存空间 因此递归通常比循环的时间效率更低
- 普通递归:当函数返回到上一层级的函数后,需要继续执行代码,因此系统需要保存上一层调用的上下文。
- 尾递归:递归调用是函数返回前的最后一个操作,这意味着函数返回到上一层级后,无需继续执行其他操作,因此系统无需保存上一层函数的上下文。
- 普通递归:求和操作是在“归”的过程中执行的,每层返回后都要再执行一次求和操作。
- 尾递归:求和操作是在“递”的过程中执行的,“归”的过程只需层层返回。
时间复杂度
- 确定运行平台,包括硬件配置、编程语言、系统环境等,这些因素都会影响代码的运行效率。
- 评估各种计算操作所需的运行时间,例如加法操作
+需要 1 ns,乘法操作*需要 10 ns,打印操作print()需要 5 ns 等。 - 统计代码中所有的计算操作,并将所有操作的执行时间求和,从而得到运行时间。
时间复杂度分析统计的不是算法运行时间,而是算法运行时间随着数据量变大时的增长趋势。
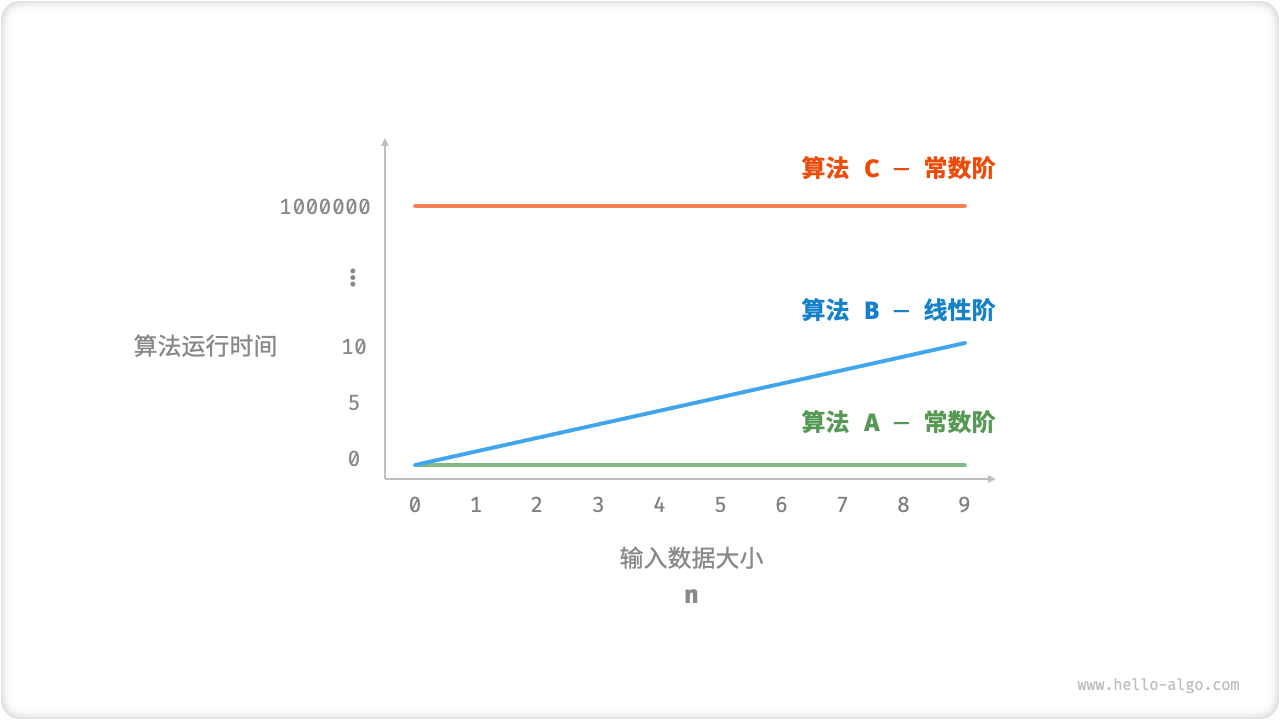
- 时间复杂度能够有效评估算法效率。例如,算法
B的运行时间呈线性增长,在 n>1 时比算法A更慢,在 n>1000000 时比算法C更慢。事实上,只要输入数据大小 n足够大,复杂度为“常数阶”的算法一定优于“线性阶”的算法,这正是时间增长趋势所表达的含义。 - 时间复杂度的推算方法更简便。显然,运行平台和计算操作类型都与算法运行时间的增长趋势无关。因此在时间复杂度分析中,我们可以简单地将所有计算操作的执行时间视为相同的“单位时间”,从而将“计算操作的运行时间的统计”简化为“计算操作的数量的统计”,这样以来估算难度就大大降低了。
- 时间复杂度也存在一定的局限性。例如,尽管算法
A和C的时间复杂度相同,但实际运行时间差别很大。同样,尽管算法B的时间复杂度比C高,但在输入数据大小 n 较小时,算法B明显优于算法C。在这些情况下,我们很难仅凭时间复杂度判断算法效率的高低。当然,尽管存在上述问题,复杂度分析仍然是评判算法效率最有效且常用的方法。


常数阶
数阶的操作数量与输入数据大小 n无关,即不随着 n 的变化而变化。
def constant(n: int) -> int:
"""常数阶"""
count = 0
size = 100000
for _ in range(size):
count += 1
return count
线性阶
线性阶的操作数量相对于输入数据大小 N以线性级别增长。线性阶通常出现在单层循环中
输入数据大小 n 需根据输入数据的类型来具体确定。比如在第一个示例中,变量 n 为输入数据大小;在第二个示例中,数组长度 n 为数据大小。
def linear(n: int) -> int:
"""线性阶"""
count = 0
for _ in range(n):
count += 1
return count
def array_traversal(nums: list[int]) -> int:
"""线性阶(遍历数组)"""
count = 0
# 循环次数与数组长度成正比
for num in nums:
count += 1
return count
平方阶
平方阶通常出现在嵌套循环中
def quadratic(n: int) -> int:
"""平方阶"""
count = 0
# 循环次数与数组长度成平方关系
for i in range(n):
for j in range(n):
count += 1
return count

def bubble_sort(nums: list[int]) -> int:
"""平方阶(冒泡排序)"""
count = 0 # 计数器
# 外循环:未排序区间为 [0, i]
for i in range(len(nums) - 1, 0, -1):
# 内循环:将未排序区间 [0, i] 中的最大元素交换至该区间的最右端
for j in range(i):
if nums[j] > nums[j + 1]:
# 交换 nums[j] 与 nums[j + 1]
tmp: int = nums[j]
nums[j] = nums[j + 1]
nums[j + 1] = tmp
count += 3 # 元素交换包含 3 个单元操作
return count
指数阶
def exponential(n: int) -> int:
"""指数阶(循环实现)"""
count = 0
base = 1
# 细胞每轮一分为二,形成数列 1, 2, 4, 8, ..., 2^(n-1)
for _ in range(n):
for _ in range(base):
count += 1
base *= 2
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count
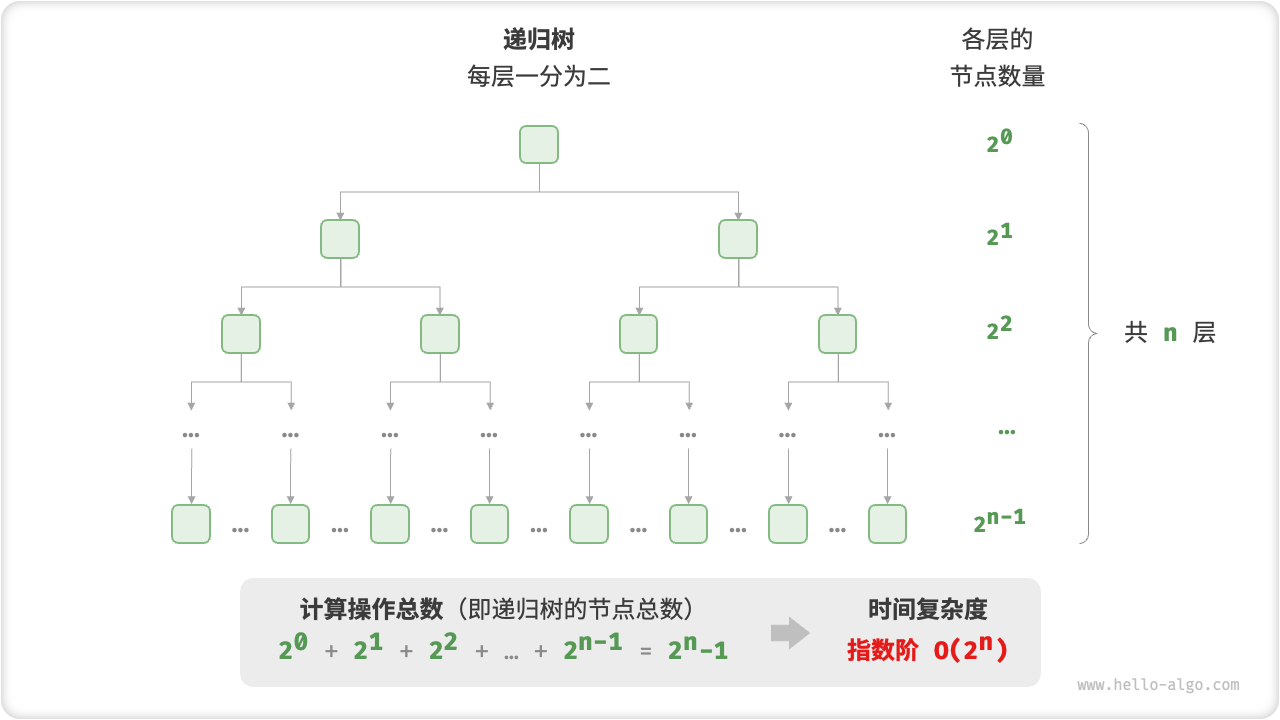
在实际算法中,指数阶常出现于递归函数中
对数阶


def linear_log_recur(n: float) -> int:
"""线性对数阶"""
if n <= 1:
return 1
count: int = linear_log_recur(n // 2) + linear_log_recur(n // 2)
for _ in range(n):
count += 1
return count
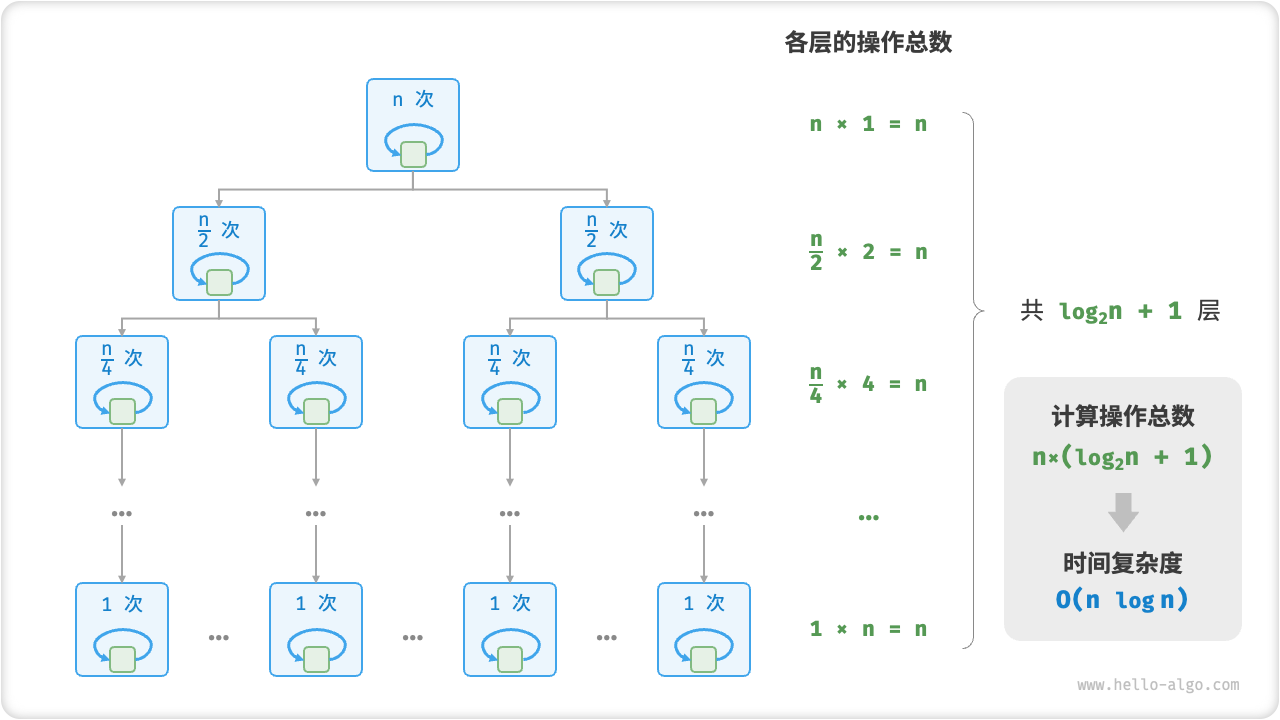
主流排序算法的时间复杂度通常为 O(nlogn) ,例如快速排序、归并排序、堆排序等。

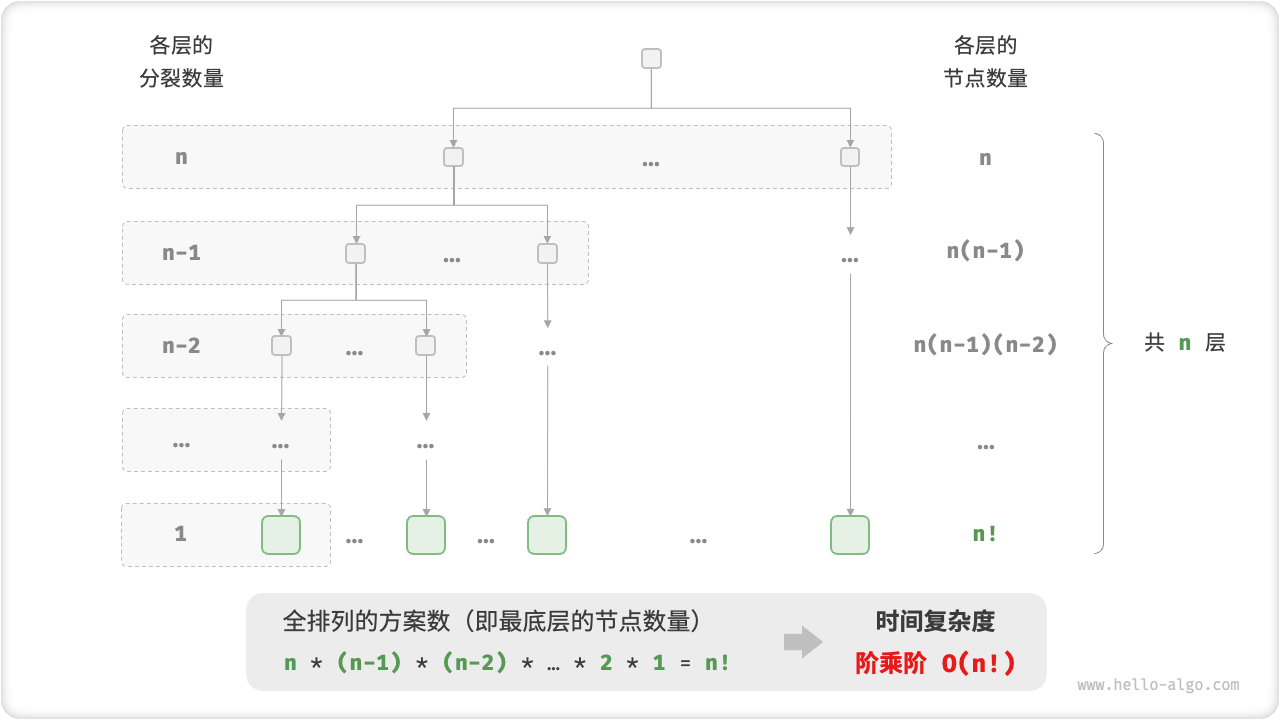
def factorial_recur(n: int) -> int:
"""阶乘阶(递归实现)"""
if n == 0:
return 1
count = 0
# 从 1 个分裂出 n 个
for _ in range(n):
count += factorial_recur(n - 1)
return count

def random_numbers(n: int) -> list[int]:
"""生成一个数组,元素为: 1, 2, ..., n ,顺序被打乱"""
# 生成数组 nums =: 1, 2, 3, ..., n
nums = [i for i in range(1, n + 1)]
# 随机打乱数组元素
random.shuffle(nums)
return nums
def find_one(nums: list[int]) -> int:
"""查找数组 nums 中数字 1 所在索引"""
for i in range(len(nums)):
# 当元素 1 在数组头部时,达到最佳时间复杂度 O(1)
# 当元素 1 在数组尾部时,达到最差时间复杂度 O(n)
if nums[i] == 1:
return i
return -1

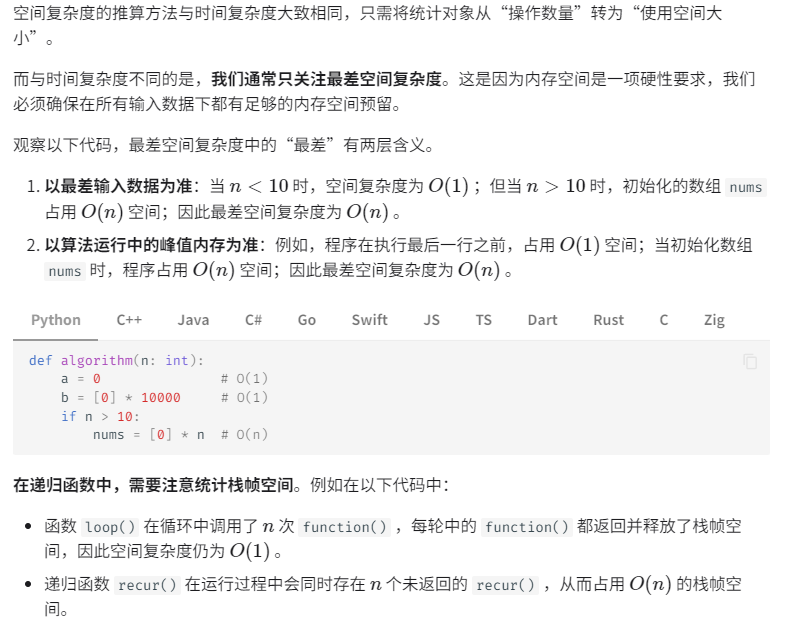
空间复杂度
算法在运行过程中使用的内存空间主要包括以下几种。
- 输入空间:用于存储算法的输入数据。
- 暂存空间:用于存储算法在运行过程中的变量、对象、函数上下文等数据。
- 输出空间:用于存储算法的输出数据。
一般情况下,空间复杂度的统计范围是“暂存空间”加上“输出空间”。
暂存空间可以进一步划分为三个部分。
- 暂存数据:用于保存算法运行过程中的各种常量、变量、对象等。
- 栈帧空间:用于保存调用函数的上下文数据。系统在每次调用函数时都会在栈顶部创建一个栈帧,函数返回后,栈帧空间会被释放。
- 指令空间:用于保存编译后的程序指令,在实际统计中通常忽略不计。
在分析一段程序的空间复杂度时,我们通常统计暂存数据、栈帧空间和输出数据三部分。


降低时间复杂度通常需要以提升空间复杂度为代价,反之亦然。我们将牺牲内存空间来提升算法运行速度的思路称为“以空间换时间”;反之,则称为“以时间换空间”。
