稳定性保障,是一切技术工作的出发点和落脚点,也是 IT 工作最核心的价值体现,当然也是技术人员最容易“翻车”的阴沟。8个稳定性保障锦囊,分享给各位技术人员择机使用。
#1 设定可量化的、业务可理解的可用性目标
没有度量就没有改进。Google SRE 曾在其工程实践中,就引入了针对服务可靠性的预算机制,即「Budget」的概念。技术团队和业务团队就服务不可用时长的额度,制定合理的目标,进而指导技术投资、稳定性保障、业务发展三者的全局最优解法。技术方制定稳定性的度量指标,一个关键出发点是“业务方要听的懂”。
我们可以将度量指标进行更进一步的抽象,分别从外部用户视角和从内部系统视角,全面的看待整体的可用性,甚至某种意义来讲,从外部用户视角看到的稳定性统计结果更有说服力,更有价值。暂且把从外部用户视角对系统可用性的度量指标称之为「北极星指标」。通过北极星指标的实时变化趋势,技术和业务团队可以全面的了解系统的运行状态,当发生全局故障的时刻,也可以让所有参与者能够清楚知晓对核心业务的影响面,进而对故障级别、应急处置优先级有统一的认知。北极星本质上,就是在从用户的视角,来整体看待复杂系统的稳定性。
举几个例子:
- 对于类似 zoom 这样的在线会议业务,其北极星指标可以定义为「1分钟内的参与会议的方数」;
- 对于电商业务,其北极星指标可以定义为「1分钟内的交易笔数」;
- 对于游戏业务,其北极星指标可以是 「1分钟内的同时在线游戏人数」;
- 对于类似滴滴这样的出行业务,其北极星指标可以是「1分钟内的呼叫次数」「1分钟内处于行程中的订单数」;
- 对于直播类的业务,其北极星指标可以是「1分钟内的主播在线数」「1分钟内的观众在线数」「1分钟内的打赏总金额」等;
从故障发现和定位的角度,一旦这些北极星指标发生了异常波动,就代表了核心业务受到了影响,该事件应该要第一时间被响应并上升,故障应急小组第一时间就位,相关支撑系统的工程师也要被 involve 进来。这种方法可以确保技术团队在业务受损的第一时间就能感知到,起到了故障发现兜底的作用。
同时,北极星指标经过一段时间的运行,其异常的时间、正常的时间,本身就是一个很客观的度量我们系统是否稳定的依据,作为技术团队和业务方沟通的桥梁,是最合适不过了。一年到头,稳定性好与坏,不是技术团队自说自话,从外部用户的视角,用北极星指标的统计结果更客观。
#2 建立可重复执行的发现 、定位、止损路径
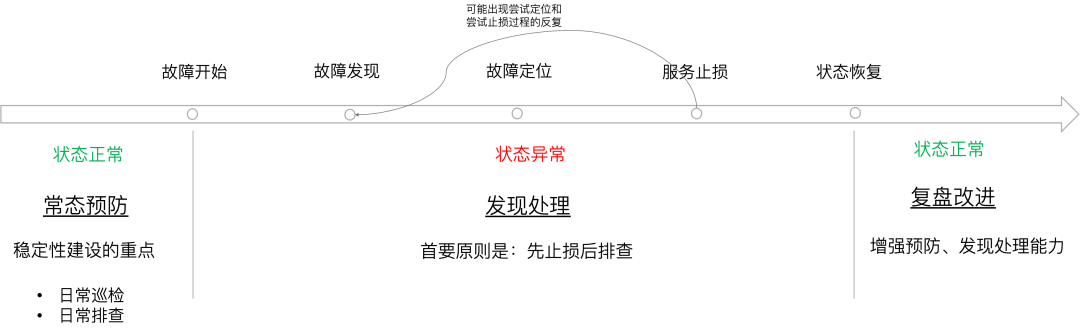
故障发现、定位、止损,是稳定性保障闭环中最紧迫、最关键的环节,通常技术人员会做的事情是从各个维度收集『信息』以辅助决策:
- 看哪些功能和系统受到了影响和受影响的程度
- 看受影响的是哪个单元(如果有多活、多集群或多云架构的话)
- 看是否有相关的变更等重要事件
- 看系统的容量是否过载
- 看有没有基础设施的故障(网络/机房等)
- 从端上向后端trace日志,看异常源自哪个环节
- 看全局日志/指标的统计数据,判断故障的特征
- 看其他多种维度的数据、使用更多的定位工具。。。
在这个环节,推荐重点加强以下三个点:
- 问题的排查路径,是否可以固化在平台上,变成套路,并通过每次的故障复盘逐步的完善
- 在问题的排查过程中,尽量把需要的数据、信息透明化,免去工程师在不同的工具、平台之间跳转的时间
- 把最有经验工程师的专家经验,能否沉淀到平台上,变成所有工程师的经验
故障紧急止损,常见的手段也是相对固定的,不外乎:
- 变更回滚
- 流量调度
- 服务降级
- 接口限流
- 弹性伸缩
- 机器重启
- 服务重启
- 单点切换
所以,能否把故障的排查结论和固定的止损手段,快速关联起来,决定着本次故障处理的速度,也就决定了本次故障最终的级别。
#3 确保核心服务有冗余、可切换
在架构设计过程中,采用“面向失败设计架构”的思想至关重要,任何系统、模块都有失效的概率。所以,我们需要重点关注以下几个方面:
- 梳理和识别业务主流程上的关键节点
- 主流程上的关键节点,需要定期review,避免随着业务的迭代,出现遗漏
- 制定针对关键模块的冗余方案,以及对应的容灾切换方案
- 极端情况下,核心模块有“从零恢复”的预案
#4 确保非核心功能可降级、可熔断
在现代化的软件架构下,系统的模块数量很多,实例数量也很多,实例之间的调用链复杂。往往会由于“非主流程”的模块故障,导致“主流程”被阻塞、甚至“雪崩”。在识别出主流程上的关键节点之外,所有的非核心功能,都必须具备可降级、可熔断的能力。
重点关注以下几点:
- 可以查看核心模块的依赖列表,并清楚的呈现每个依赖的接口的流量、成功率、延迟等黄金指标(推荐增加Tracing的覆盖率)
- 在非核心功能层面,有开关可以一键熔断和降级(推荐使用feature flags技术)
#5 有状态服务,限流是恢复故障的关键抓手
有状态服务,在故障时候,一般很难短时间内进行扩容,这往往涉及到数据的迁移和再平衡,而数据的迁移又会加重系统的负载,降低系统的性能,导致故障会变的更严重,“雪崩”现象往往就是这么引起的。因此,针对有状态服务,在故障的时刻,最有效的恢复手段是“限流”。
在限流的过程中,需要关注以下几点:
- 限流的阈值优先考虑设置“全局限流”阈值,这样在实例数量很多的情况下,限流更准确
- 某个模块的容量上限,平时要摸出来,并按照流量、延迟、成功率进行量化
- 在“雪崩”严重的情况下,为了让相关模块能快速恢复,推荐的限流操作顺序为:先拒绝所有流量,然后逐步提升限流的阈值,给系统逐步恢复的时间和空间
#6 无状态服务,弹性伸缩是恢复故障的关键抓手
- 在系统架构设计上,尽可能设计无状态服务的架构,把有状态的东西更多转移到数据库、对象存储、消息队列等服务中。
- 将计算层微服务化,有助于更好的弹性伸缩。
#7 严格执行灰度发布,把影响面控制在小流量阶段
根据统计规律,只要有变更, 就有很大的概率引发故障。统计数据显示,70%的故障都和变更相关,这些变更包括:
- 线上发布新版本
- 配置变更
- 开关变更(feature flags)
- 数据库变更
- 网络变更
降低变更引发的故障的影响面的方法包括:
- 严格执行灰度发布流程,把问题暴露在小流量阶段
- 尽可能的保持开发、预发布、线上环境相同,尽早暴露问题
#8 善用云服务
用多az胜过用多云
- 多az基本可以保障云基础设施的可用性,多云反而会给业务系统的设计带来更大的复杂度,从而引入更多的稳定性风险点。
用对象存储静态文件
- 成本优化上:按量使用付费,不需要提前预制大量长期浪费的空闲空间,并且有丰富的存储形式,单价也低于块存储;
- 容错能力上:一般都是三副本,可以做版本管理,优于块存储;
- 性能上:是公有云的全托管服务,单用户请求可能逊于块存储设备,但是在多用户特别是海量场景下性能有保证;
- 安全性:是公有云的全托管服务,有丰富的安全策略可以配置,只需要在使用注意选择和配置,日常维护由公有云保证;
- 扩展性:极好,因为空间接近无限制,研发人员无需担心空间不足情况,不需要猜测容量需求;
- 开发优势:因为是基于 API 的公开服务,所以方便多个服务共享使用,是一个很好的解耦渠道;
尽量用云托管服务
- 云托管服务,指的是由公有云完全托管管理,客户不关心具体的服务器细节,只通过接口来使用服务,通过公有云的控制台、API、SDK 来管理服务,扩展、容错能力和可用性通常内置在服务中。
- 鼓励和推荐研发人员选用托管服务
- 给研发人员一定的托管服务权限
- 给研发人员提case的权限以应对托管服务的问题
- 让TAM直接服务研发人员
- 运维管住自己的手:)
- 尽量不自建各种开源服务
- 拒绝任何维护非业务代码服务的要求
- 可以购买商业 SaaS 来替代公有云没有的托管服务
数据不要存在服务器上
- 日志存S3或者打入到ELK等外部服务中;
- 配置文件应该通过外部或者环境获取
- 外部就是类似Parameter Store或者其他配置中心
- 环境就是可以通过ec2启动时的用户数据,或者pod启动时环境变量来注入具体的配置
- https证书应该用acm和相关服务来解耦,或者参照配置文件获取;
- 密钥应该通过外部或者环境获取,类似Parameter Store;
- 业务数据应该进入S3或者数据库;
- 应用之间的中间数据,应该送往消息队列进行解耦处理;
- 所有脚本和配置应该代码库统一管理,部署应该按照CI/CD管理;
- 服务器开机,应用服务自启动;
- 将程序设计成无状态,无共享,可以随时终止;
注:「善用云服务」,节选自「云原生王四条」