1. 用户信息错乱-ThreadLocal
- 问题:有时获取到的用户信息是别人的。
- 因为Tomcat 的工作线程是基于线程池的, 所以使用类似 ThreadLocal 工具来存放一些数据时,需要特别注意在代码运行完后,显式地去清空设置的数据,不然就有可能因为线程池复用工作线程,ThreadLocal 中存放的还是上一次的用户信息。
2. 使用了线程安全的并发工具,并不代表解决了所有线程安全问题-ConcurrentHashMap
ConcurrentHashMap只能保证提供的原子性读写操作是线程安全的。在 putAll 的过程中size、isEmpty 和 containsValue 等聚合方法对于线程之间来说并不能同步。
//线程个数
private static int THREAD_COUNT = 10;
//总元素数量
private static int ITEM_COUNT = 1000;
//帮助方法,用来获得一个指定元素数量模拟数据的ConcurrentHashMap
private ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(Collectors.toConcurrentMap(i -> UUID.randomUUID().toString
(o1, o2) -> o1, ConcurrentHashMap::new));
}
@GetMapping("wrong")
public String wrong() throws InterruptedException {
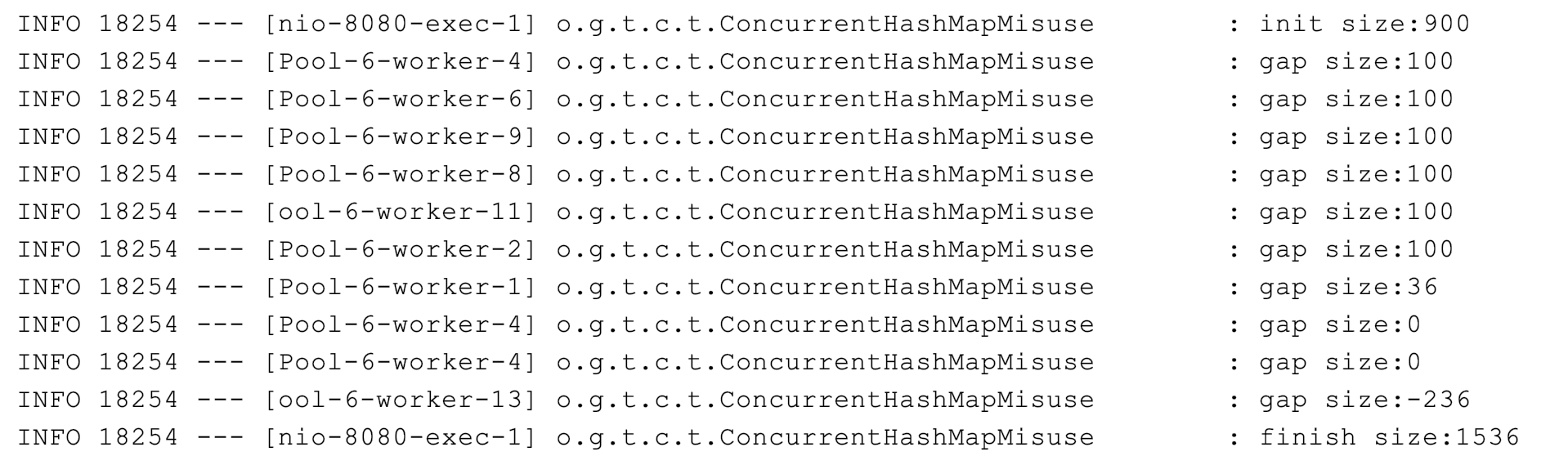
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 10
//初始900个元素
log.info("init size:{}", concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
//使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach
//查询还需要补充多少个元素
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("gap size:{}", gap);
//补充元素
concurrentHashMap.putAll(getData(gap));
}));
//等待所有任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//最后元素个数会是1000吗?
log.info("finish size:{}", concurrentHashMap.size());
return "OK";
}
结果如下:
我们来看一个使用 Map 来统计 Key 出现次数的场景吧:
- 使用 ConcurrentHashMap 来统计,Key 的范围是 10。
- 使用最多 10 个并发,循环操作 1000 万次,每次操作累加随机的 Key。
- 如果 Key 不存在的话,首次设置值为 1。
优化前:

使用 ConcurrentHashMap 的原子性方法 computeIfAbsent 来做复合逻辑操作,判断Key 是否存在 Value,如果不存在则把 Lambda 表达式运行后的结果放入 Map 作为 Value,也就是新创建一个LongAdder 对象,最后返回 Value。优化后的代码,相比使用锁来操作 ConcurrentHashMap 的方式,性能提升了 10 倍。
//todo CAS
computeIfAbsent 为什么如此高效呢,也就是 Java 自带的Unsafe 实现的 CAS。
3. 没有认清并发工具的使用场景,因而导致性能问题 - CopyOnWriteArrayList
比较下使用 CopyOnWriteArrayList 和普通加锁方式 ArrayList的读写性能吧:
- 大量写的场景(10 万次 add 操作):CopyOnWriteArray 几乎比同步的 ArrayList 慢一百倍。
- 而在大量读的场景下(100 万次 get 操作),CopyOnWriteArray 又比同步的 ArrayList。
4. 加锁前要清楚锁和被保护的对象是不是一个层面的 - synchronized
静态字段属于类,类级别的锁才能保护;而非静态字段属于类实例,实例级别的锁就可以保护。
5. 加锁要考虑锁的粒度和场景问题 - ReentrantReadWriteLock
- 仅对必要的代码块甚至是需要保护的资源本身加锁。
- 区分读写场景以及资源的访问冲突,考虑使用悲观方式的锁还是乐观方式的锁。
6. 线程池的声明需要手动进行 - Executors
不建议使用 Executors 提供的两种快捷的线程池,原因如下:
- newFixedThreadPool 的等待队列的长度是Integer.MAX_VALUE的,可以认为是无界的,可能会导致OOM。
- newCachedThreadPool 这种线程池的最大线程数是 Integer.MAX_VALUE,可以认为是没有上限的,而其工作队列 SynchronousQueue 是一个没有存储空间的阻塞队列。
- 我们需要根据自己的场景、并发情况来评估线程池的几个核心参数,包括核心线程数、最大线程数、线程回收策略、工作队列的类型,以及拒绝策略,确保线程池的工作行为符合需求,一般都需要设置有界的工作队列和可控的线程数。
- 任何时候,都应该为自定义线程池指定有意义的名称,以方便排查问题。当出现线程数量暴增、线程死锁、线程占用大量 CPU、线程执行出现异常等问题时,我们往往会抓取线程栈。此时,有意义的线程名称,就可以方便我们定位问题。
7. 别让连接池帮了倒忙 - 连接池
7.1 客户端 SDK 实现连接池的方法
- 池和连接分离。如Jedis和JedisPool。
- 内部带线程池。如Apache HttpClient是内置线程池。
- 非连接池。
7.2 确保连接池的复用
原因如下:
- 创建池的时候很可能初始化最小链接,用来直接使用,那么很有可能你只用到了一个连接,但是创建了N个连接。
- 连接池一般有一些管理模块,比如用来检测连接的限制时间,定期回收闲置的连接,为此限制连接由独立线程管理,因此启动一个线程池想当与启动了N个线程。
7.3 配置连接池参数
针对数据库连接池、HTTP 连接池、Redis 连接池等重要连接池,务必建立完善的监控和报警机制,根据容量规划及时调整参数配置。对类似数据库连接池的重要资源进行持续检测,并设置一半的使用量作为报警阈值,出现预警后及时扩容。
8. HTTP调用:你考虑到超时、重试、并发了吗?
8.1 配置连接超时和读取超时参数
- 连接超时参数 ConnectTimeout,让用户配置建连阶段的最长等待时间。一些误区如下。
- 配置超时时长是需要注意的是网络状况,如果在内网调用的网可以设置得更段。而且特别长的连接超时没有意义,因为TCP三词握手的时间通常在毫秒级,设置1~5就行。
- 进行排错时,也需要连接的是哪里。如我们在使用Nginx的反向代理来负载均衡时,客户端连接的其实是Nginx,而不是服务器。
- 读取超时参数 ReadTimeout,用来控制从 Socket 上读取数据的最长等待时间。一些误区如下:
- 读取超时,服务端的执行就会中断。类似 Tomcat 的 Web 服务器都是把服务端请求提交到线程池处理的,只要服务端收到了请求,网络层面的超时和断开便不会影响服务端的执行。因此,出现读取超时不能随意假设服务端的处理情况,需要根据业务状态考虑如何进行后续处理。
- 认为超时时间越长任务接口成功率就越高,将读取超时参数配置得太长。对定时任务或异步任务来说,读取超时配置得长些问题不大。但面向用户响应的请求或是微服务短平快的同步接口调用,并发量一般较大,我们应该设置一个较短的读取超时时间,以防止被下游服务拖慢,通常不会设置超过 30 秒的读取超时。
//todo Feign 和 Ribbon
8.2 Feign 和 Ribbon 配合使用,你知道怎么配置超时吗 - Feign 和 Ribbon
8.3 并发限制了爬虫的抓取能力 - HttpClient的最大并发数
- defaultMaxPerRoute=2,也就是同一个主机 / 域名的最大并发请求数为 2。。
- maxTotal=20,也就是所有主机整体最大并发为 20,这也是 HttpClient 整体的并发
度。举一个例子,使用同一个 HttpClient 访问 10 个域名,defaultMaxPerRoute 设置为 10,为确保每一个域名都能达到 10 并发,需要把 maxTotal 设置为 100。
HttpClient设置这么小的原因:很多早期的浏览器也限制了同一个域名两个并发请求。
9. 20%的业务代码的Spring声明式事务,可能都没处理正确 - @Transactional
9.1 @Transactional 生效原则
- 除非特殊配置(比如使用 AspectJ 静态织入实现AOP),否则只有定义在 public 方法上的 @Transactional 才能生效。Spring默认通过动态代理的方式实现 AOP,对目标方法进行增强,private 方法无法代理到,Spring 自然也无法动态增强事务处理逻辑。
- 必须通过代理类调用目标方法才能生效。如createUserWrong1方法把异常捕获了,也是捕获发生回滚的。
- 只有异常传播出了标记了 @Transactional 注解的方法,事务才能回滚。也就是
- 出现 RuntimeException(非受检异常)或 Error 的时候,Spring才会回滚事务。如createUserWrong2方法并不会回滚,因为IOException是受检异常。解决办法设置
@Transactional(rollbackFor = Exception.class)所有异常都捕获。

受检异常:需要对抛出的异常进行处理,捕获或者抛出去。
9.2 请确认事务传播配置是否符合自己的业务逻辑
- TransactionDefinition.PROPAGATION_REQUIRED:默认值,如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- TransactionDefinition.PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- TransactionDefinition.PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
10. 数值计算:注意精度、舍入和溢出问题
10.1 “危险”的 Double - BigDecimal
使用 BigDecimal 表示和计算浮点数,且务必使用字符串的构造方法来初始化
BigDecimal。因为使用数字初始化化,还是会有精度问题。
System.out.println(new BigDecimal(0.1).add(new BigDecimal(0.2)));
System.out.println(new BigDecimal(1.0).subtract(new BigDecimal(0.8)));
System.out.println(new BigDecimal(4.015).multiply(new BigDecimal(100)));
System.out.println(new BigDecimal(123.3).divide(new BigDecimal(100)));
System.out.println(new BigDecimal("0.1").add(new BigDecimal("0.2")));
System.out.println(new BigDecimal("1.0").subtract(new BigDecimal("0.8")));
System.out.println(new BigDecimal("4.015").multiply(new BigDecimal("100")));
System.out.println(new BigDecimal("123.3").divide(new BigDecimal("100")));
输出:
0.3000000000000000166533453693773481063544750213623046875
0.1999999999999999555910790149937383830547332763671875
401.49999999999996802557689079549163579940795898437500
1.232999999999999971578290569595992565155029296875
0.3
0.2
401.500
1.233
Set<BigDecimal> hashSet1 = new HashSet<>();
hashSet1.add(new BigDecimal("1.0"));
System.out.println(hashSet1.contains(new BigDecimal("1")));//返回false
方法一:
使用集合存储BigDecimal时使用TreeSet,因为TreeSet 不使用 hashCode 方法,也不使用 equals 比较元素,而是使用 compareTo 方法,所以不会有问题。
Set<BigDecimal> treeSet = new TreeSet<>();
treeSet.add(new BigDecimal("1.0"));
System.out.println(treeSet.contains(new BigDecimal("1")));//返回true
方法二:第二个方法是,把 BigDecimal 存入 HashSet 或 HashMap 前,先使用
stripTrailingZeros 方法去掉尾部的零,比较的时候也去掉尾部的 0,确保 value 相同的BigDecimal,scale 也是一致的,因为equals 比较的是 BigDecimal 的 value 和 scale:
Set<BigDecimal> hashSet2 = new HashSet<>();
hashSet2.add(new BigDecimal("1.0").stripTrailingZeros());
System.out.println(hashSet2.contains(new BigDecimal("1.000").stripTrailingZero
10.2 考虑浮点数舍入和格式化的方式 - format
String.format 采用四舍五入的方式进行舍入,取 1 位小数,double 的 3.350 四舍五入为3.4,而 float 的 3.349 四舍五入为 3.3。
double num1 = 3.35;
float num2 = 3.35f;
System.out.println(String.format("%.1f", num1));//四舍五入
System.out.println(String.format("%.1f", num2));
输出
3.4
3.3
11. 集合类:坑满地的List列表操作
11.1 使用 Arrays.asList 把数据转换为 List 的三个坑 - Arrays.asList
以下代码输出的是1:
int[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
System.out.println(list.size());
因为 asList 使用的是一个泛型 T 类型可变参数,他把 int[] 当成了一个数组对象,只能是把 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。而使用Integer[] 时得到结果就为3。
- 第一坑:不能直接使用 Arrays.asList 来转换基本类型数组。
- 第二坑:Arrays.asList 返回的 List 不支持增删操作。Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。ArrayList 内部类继承自AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出UnsupportedOperationException。
- 第三坑:对原始数组的修改会影响到我们获得的那个 List。
11.2 使用 List.subList 进行切片操作居然会导致 OOM?- List.subList
List.subList 返回的子List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响。以下代码就有可能产生OOM:
private static List<List<Integer>> data = new ArrayList<>();
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
List<Integer> rawList = IntStream.rangeClosed(1, 100000).boxed().collect(Collectors.toList());
data.add(rawList.subList(0, 1));
}
}
出现 OOM 的原因是,循环中的 1000 个具有 10 万个元素的 List 始终得不到回收,因为它始终被 subList 方法返回的 List 强引用。
-
解决方法一:一种是,不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList。
-
解决方法二:使用 stream 流
rawList.stream().skip(1).limit(3).collect(Collectors.toList())。
11.3 一定要让合适的数据结构做合适的事情 - LinkedList 和 ArrayList
- 对于数组,随机元素访问的时间复杂度是 O(1),元素插入操作是 O(n)。
- 对于链表,随机元素访问的时间复杂度是 O(n),元素插入操作是 O(1)。
因此对于随机插入操作,LinkedList 的时间复杂度其实也是 O(n),因为需要先找到节点,需要时间 O(n),而对于尾部插入,两者的时间也是一样的,LinkedList除了头部插入比ArrayList快,其他大部分场景都是 ArrayList 更有优势。
12. 异常处理:别让自己在出问题的时候变为瞎子 - Exception
12.1 异常覆盖 - finally
虽然 try 中的逻辑出现了异常,但却被 finally 中的异常覆盖了。
public void wrong() {
try {
log.info("try");
//异常丢失
throw new RuntimeException("try");
} finally {
log.info("finally");
throw new RuntimeException("finally");
}
}
输出:
java.lang.RuntimeException: finally
12.2 线程池异常 - Executors
- 如果任务通过 execute 提交,那么出现异常会导致线程退出,大量的异常可能会导致线程重复创建引起性能问题。我们应该尽可能确保任务不出异常,同时设置默认的未捕获异常处理程序来兜底。
- 如果任务通过 submit 提交意味着我们关心任务的执行结果,应该通过拿到的Future 调用其 get 方法来获得任务运行结果和可能出现的异常,否则异常可能就被生吞了。
13. 文件IO:实现高效正确的文件读写并非易事 - File
13.1 缓冲
比较下使用下面三种方式读写一个字节的性能:
- 直接使用 BufferedInputStream 和 BufferedOutputStream;
- 额外使用一个 8KB 缓冲,使用 BufferedInputStream 和 BufferedOutputStream;
- 直接使用 FileInputStream 和 FileOutputStream,再使用一个 8KB 的缓冲。
private static void largerBufferOperation() throws IOException {
Files.deleteIfExists(Paths.get("dest.txt"));
try (FileInputStream fileInputStream = new FileInputStream("src.txt");
FileOutputStream fileOutputStream = new FileOutputStream("dest.txt")) {
byte[] buffer = new byte[8192];
int len = 0;
while ((len = fileInputStream.read(buffer)) != -1) {
fileOutputStream.write(buffer, 0, len);
}
}
}
private static void bufferedStreamBufferOperation() throws IOException {
Files.deleteIfExists(Paths.get("dest.txt"));
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("src.txt"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("dest.txt"))) {
byte[] buffer = new byte[8192];
int len = 0;
while ((len = bufferedInputStream.read(buffer)) != -1) {
bufferedOutputStream.write(buffer, 0, len);
}
}
}
private static void bufferedStreamByteOperation() throws IOException {
Files.deleteIfExists(Paths.get("dest.txt"));
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("src.txt"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("dest.txt"))) {
int i;
while ((i = bufferedInputStream.read()) != -1) {
bufferedOutputStream.write(i);
}
}
}
运行结果:
---------------------------------------------
ns % Task name
---------------------------------------------
1424649223 086% bufferedStreamByteOperation
117807808 007% bufferedStreamBufferOperation
112153174 007% largerBufferOperation
第一种方式虽然使用了缓冲流,但逐字节的操作因为方法调用次数实在太多还是
慢,耗时 1.4 秒;后面两种方式的性能差不多,耗时 110 毫秒左右。
//todo 零拷贝
13.2 FileChannel - 零拷贝
补充说明的是,对于类似的文件复制操作,如果希望有更高性能,可以使用
FileChannel 的 transfreTo 方法进行流的复制。在一些操作系统(比如高版本的 Linux 和UNIX)上可以实现 DMA(直接内存访问),也就是数据从磁盘经过总线直接发送到目标文件,无需经过内存和 CPU 进行数据中转:
private static void fileChannelOperation() throws IOException {
FileChannel in = FileChannel.open(Paths.get("src.txt"), StandardOpenOption
FileChannel out = FileChannel.open(Paths.get("dest.txt"), CREATE, WRITE);
in.transferTo(0, in.size(), out);
}
14. 当反射、注解和泛型遇到OOP时,会有哪些坑? - 泛型擦除
14.1 泛型经过类型擦除多出桥接方法的坑 - 泛型擦除
代码:
public static void wrong3() {
Child2 child2 = new Child2();
Arrays.stream(child2.getClass().getDeclaredMethods())
.filter(method -> method.getName().equals("setValue"))
.forEach(method -> {
try {
method.invoke(child2, "test");
} catch (Exception e) {
e.printStackTrace();
}
});
System.out.println(child2.toString());
}
class Parent<T> {
AtomicInteger updateCount = new AtomicInteger();
private T value;
@Override
public String toString() {
return String.format("value: %s updateCount: %d", value, updateCount.get());
}
public void setValue(T value) {
System.out.println("Parent.setValue called");
this.value = value;
updateCount.incrementAndGet();
}
}
class Child2 extends Parent<String> {
@Override
public void setValue(String value) {
System.out.println("Child2.setValue called");
super.setValue(value);
}
}
输出:
Child2.setValue called
Parent.setValue called
Child2.setValue called
Parent.setValue called
value: test updateCount: 2
为什么Child2的setValue调用了两次?
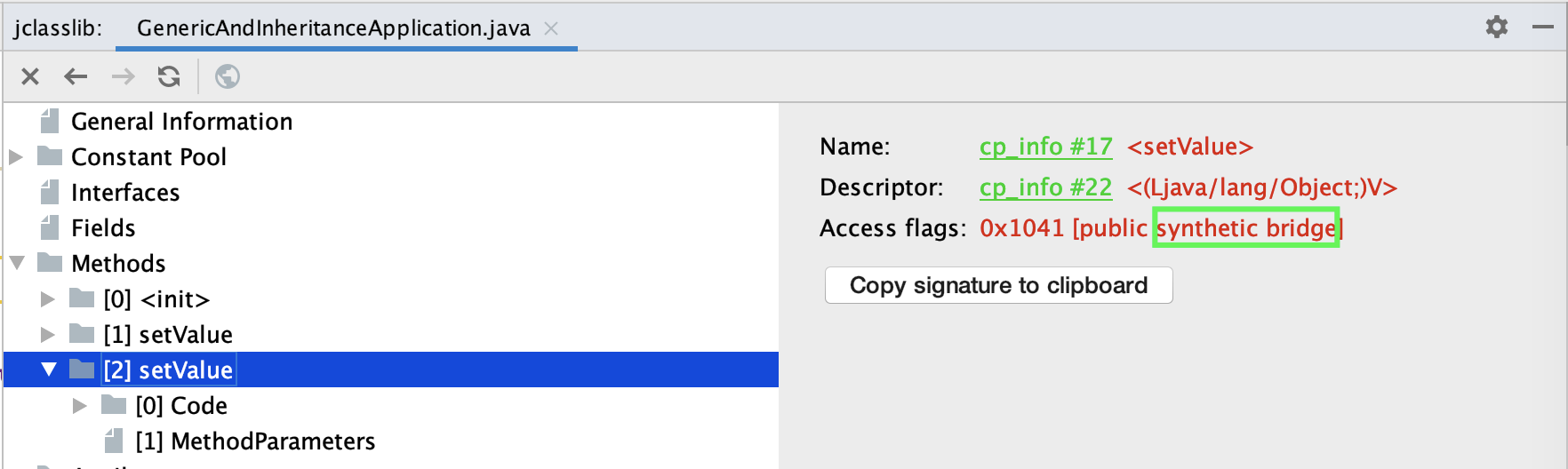
Java 的泛型类型在编译后擦除为 Object。虽然子类指定了父类泛型 T 类型是String,但编译后 T 会被擦除成为 Object,所以父类 setValue 方法的入参是 Object,value 也是 Object。如果子类 Child2 的 setValue 方法要覆盖父类的 setValue 方法,那入参也必须是 Object。所以,同样可以看到入参为 Object 的桥接方法上标记了public + synthetic + bridge 三个属性。synthetic 代表由编译器生成的不可见代码,bridge 代表这是泛型类型擦除后生成的桥接代码:
修正代码:
public static void right() {
Child2 child2 = new Child2();
Arrays.stream(child2.getClass().getDeclaredMethods())
.filter(method -> method.getName().equals("setValue") && !method.isBridge())
.findFirst().ifPresent(method -> {
try {
method.invoke(child2, "test");
} catch (Exception e) {
e.printStackTrace();
}
});
System.out.println(child2.toString());
}
15. 如何正确保存和传输敏感数据?
15.1 应该怎么保存姓名和身份证? - 非对称加密和对称加密
- 对称加密算法,是使用相同的密钥进行加密和解密。使用对称加密算法来加密双方的通信的话,双方需要先约定一个密钥,加密方才能加密,接收方才能解密。如果密钥在发送的时候被窃取,那么加密就是白忙一场。因此,这种加密方式的特点是,加密速度比较快,但是密钥传输分发有泄露风险。
- 非对称加密算法,或者叫公钥密码算法。公钥密码是由一对密钥对构成的,使用公钥加密和私钥解密,公钥可以任意公开,私钥不能公开。使用非对称加密的话,通信双方可以仅分享公钥用于加密,加密后的数据没有私钥无法解密。因此,这种加密方式的特点是,加密速度比较慢,但是解决了密钥的配送分发安全问题。
15.2 用一张图说清楚 HTTPS - HTTPS
- 机密性:使用非对称加密来加密密钥,然后使用密钥来加密数据,既安全又解决了非对称加密大量数据慢的问题。你可以做一个实验来测试两者的差距。
- 完整性:使用散列算法对信息进行摘要,确保信息完整无法被中间人篡改。
- 权威性:使用数字证书,来确保我们是在和合法的服务端通信。