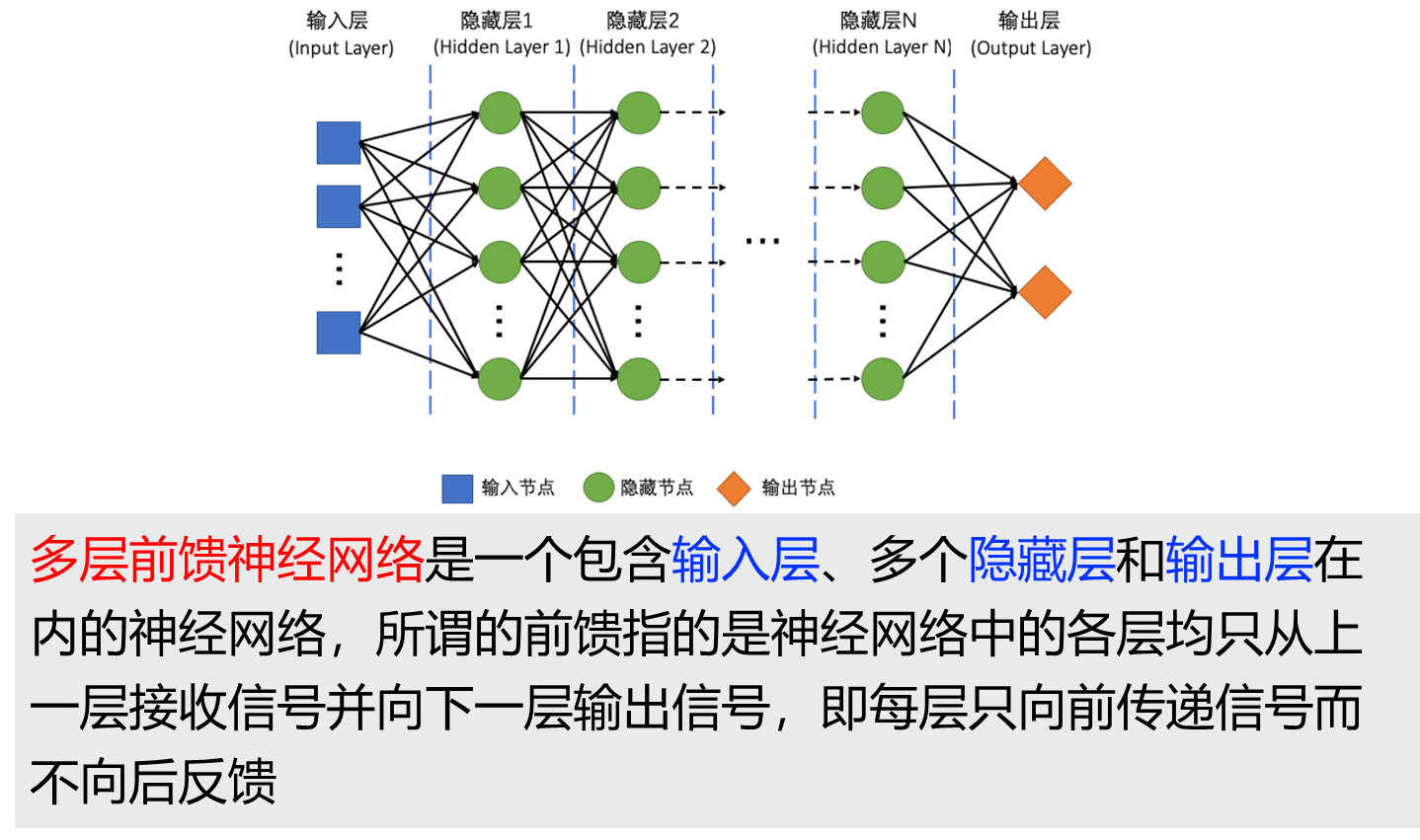
Multi-Layer Perceptron 多层感知机
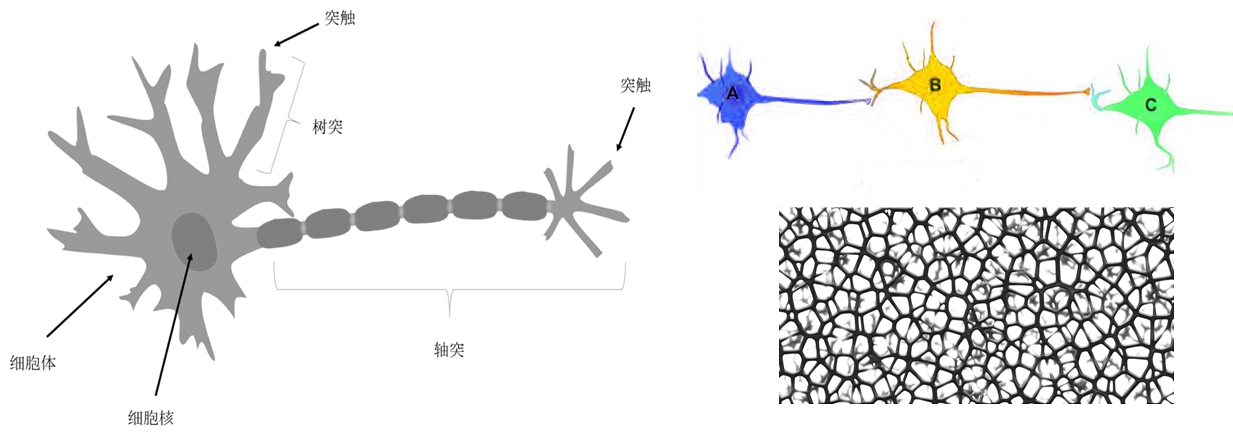
生物神经网络
圣地亚哥·拉蒙-卡哈尔(西班牙语:Santiago Ramón y Cajal,1852年5月1日-1934年10月17日),西班牙病理学家、组织学家,神经学家,1906年诺贝尔生理学医学奖得主。

人类对大脑的研究由来已久,在十九世纪末到二十世纪初,在大脑神经系统的研究方面获得了突破性的进展。1906年,西班牙神经组织学家、被誉为现代神经科学之父的圣地亚哥·拉蒙-卡哈尔(Santiago Ramón y Cajal)因对人脑神经系统的突出贡献获得当年的诺贝尔生理学或医学奖。他明确阐述了神经元(也叫做神经细胞)的独立性和神经元之间通过树枝状触角相互连接的关系,奠定了生物神经网络(Biological Neural Networks)的基础,也为人工神经网络(Artificial Neural Network,也常简称为神经网络)提供了可参考的重要依据。
他对于大脑的微观结构研究是开创性的,被许多人认为是现代神经科学之父。他绘图技能出众,他的关于脑细胞的几百个插图至今用于教学。
生平
编辑
拉蒙-卡哈尔是医师和解剖学讲师斯托·拉蒙(Justo Ramón)和安东尼·卡哈尔(Antonia Cajal)的儿子。孩提时期由于他不良行为和反专制的态度,被调到许多不同的学校。他的早熟和叛逆的一个极端的例子是在他11岁的时候,用自制的大炮摧毁邻居家大门,他也因此受到监禁。他是一个狂热的画家、艺术家和体操运动员。他曾作为鞋匠和理发师,他好斗的态度颇为知名。
1906年,瑞典卡罗琳斯卡医学院将诺贝尔医学和生理学奖授予在神经组织学领域做出重要贡献的高尔基和卡哈尔。不过,两人学术上的分歧并未因此弥合。在颁奖典礼现场,获奖者要发表演说以阐述自己在该领域所做的工作。高尔基首先发言,他以脑部受损后功能的恢复以及脑组织强大一致的信息整合能力为依据再次申明了自己对网状理论的支持。而卡哈尔则说:“的确,如果神经中枢是由运动神经……和感觉神经相互融合并连续组成的网络,那么事情会变得非常方便、经济和易于分析。不幸的是,大自然似乎无视了我们智力上对方便和一致的需求,而往往乐于表现出复杂性和多样性。”
人工神经网络
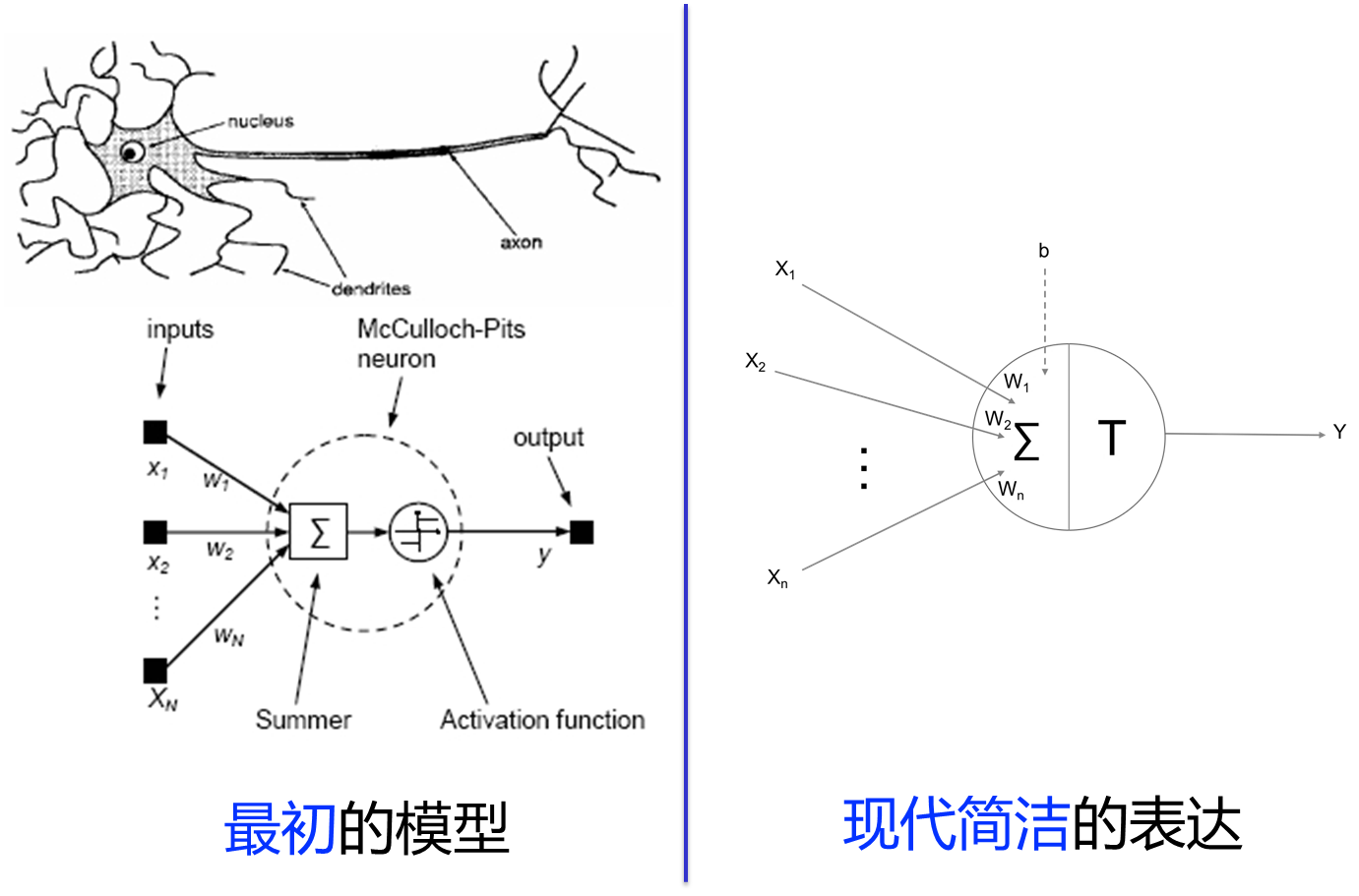
1943年,神经学家沃伦•麦卡洛克(Warren McCulloch)和年轻的数学家沃尔特·皮茨(Walter Pitts)提出了一个人工神经元的模型
——麦卡洛克-皮茨神经元模型(McCulloch-Pitts Neuron Model)
简称MP模型



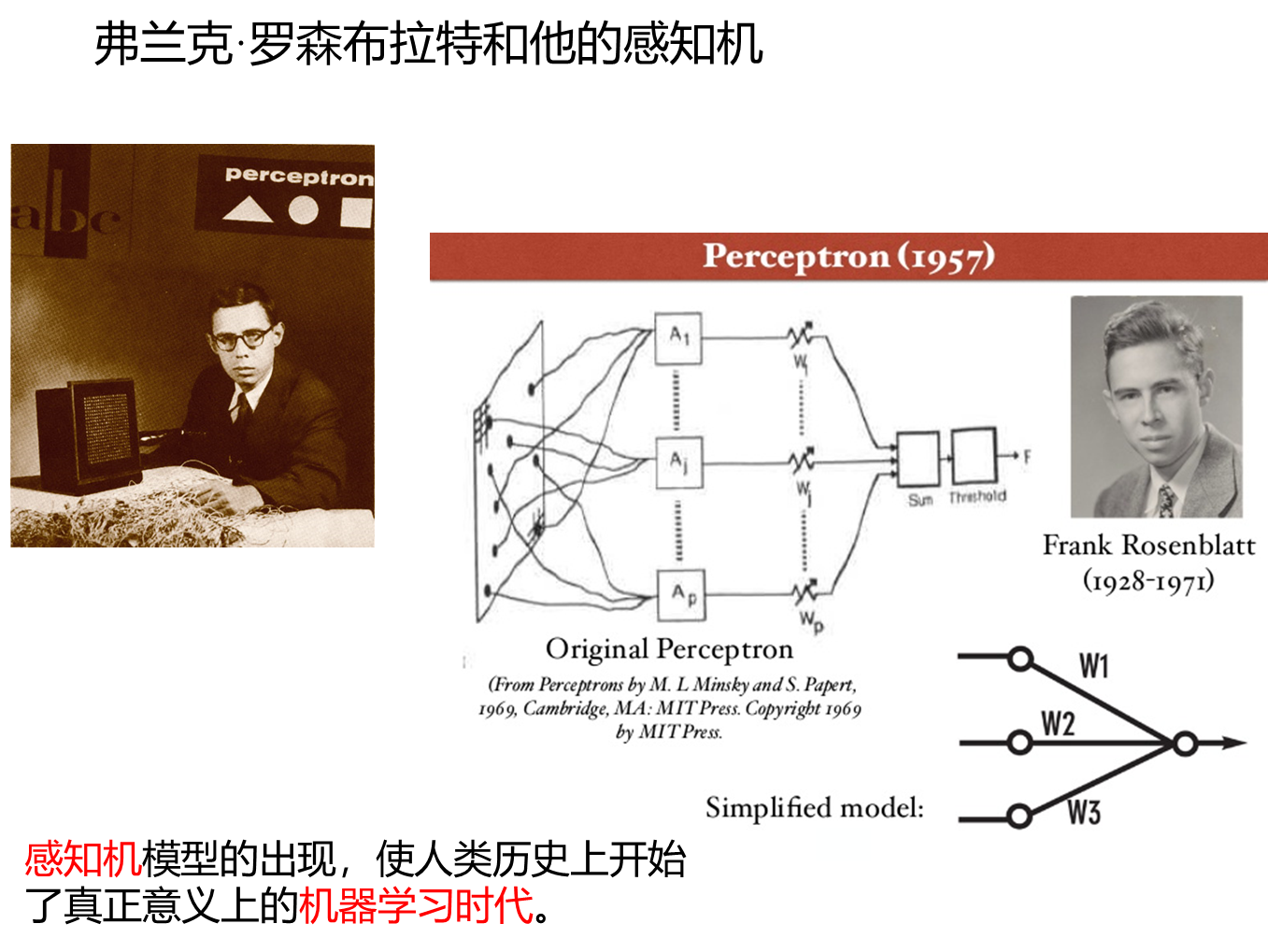

1986年,大卫·鲁姆哈特(David Rumelhart)和詹姆斯·麦克莱兰(James McClelland)在(Parallel Distributed Processing: Explorations in the Microstructure of Cognition)一文中,重新提出了反向传播学习算法并给出了完整的数学推导过程。同一时期,辛顿、罗纳德·威廉姆斯、大卫·帕克和杨立昆等人也分别做出了关于BP算法的独立研究和贡献。
BP算法正式出现的意义在于,对于如何更高效地训练神经网络,让神经网络更有序地进行学习,提供了有效的、可遵循的理论和方法,这在以后神经网络尤其是深度学习领域是一个里程碑式的事件,至今BP方法仍然是训练多层神经网络的最主要、最有效的方法。


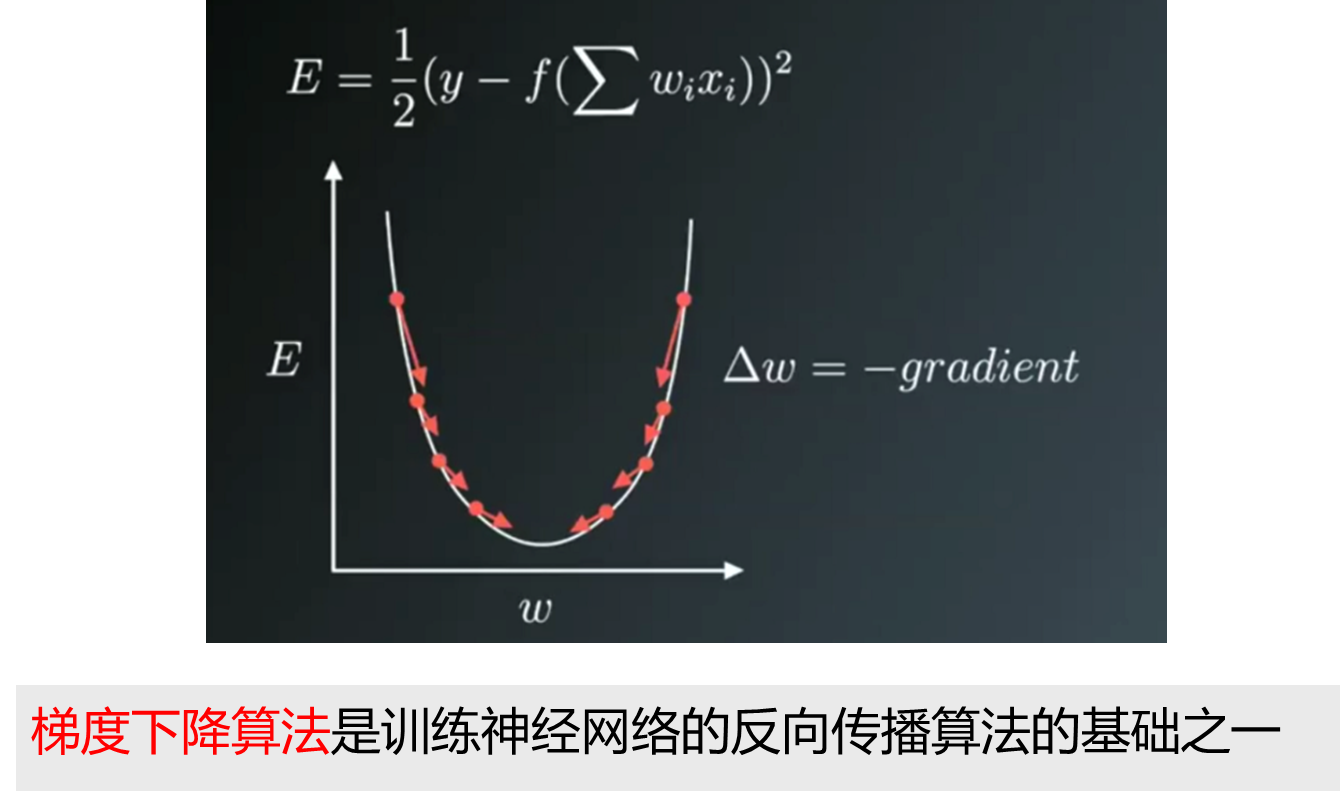
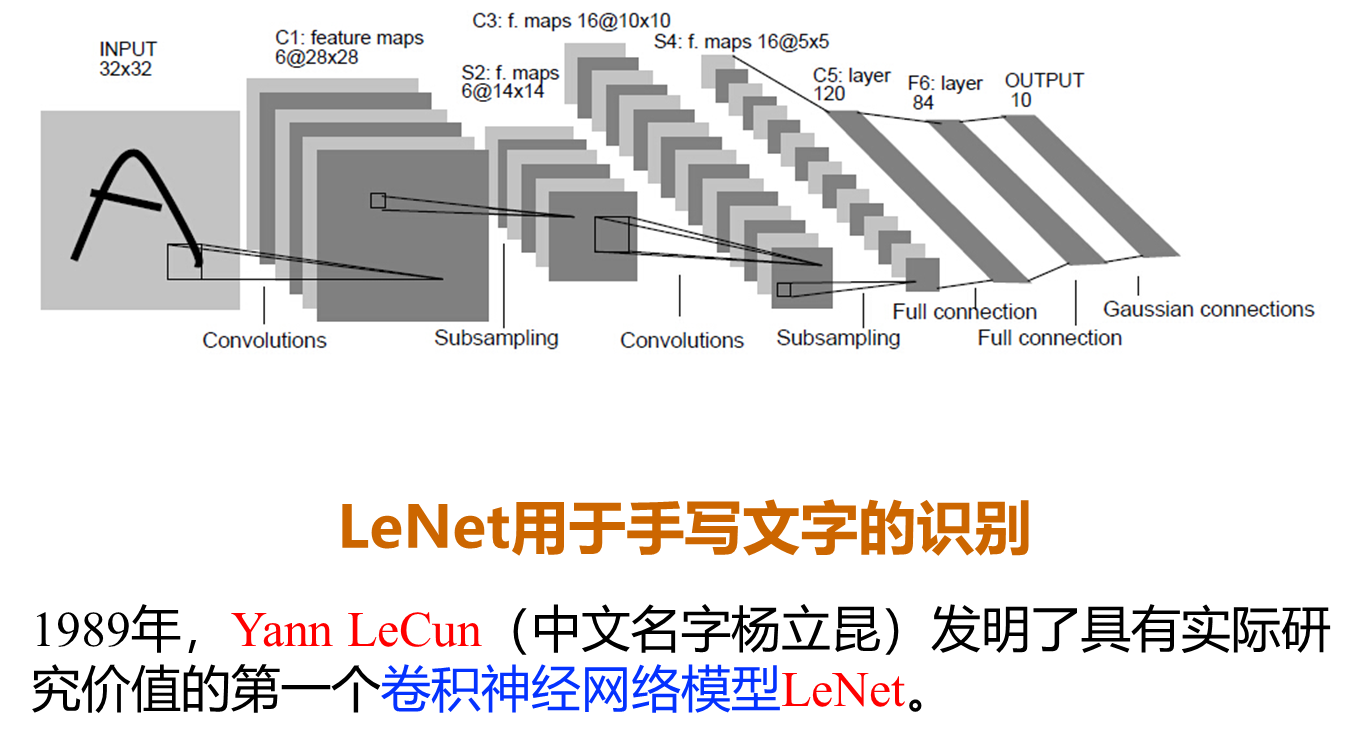

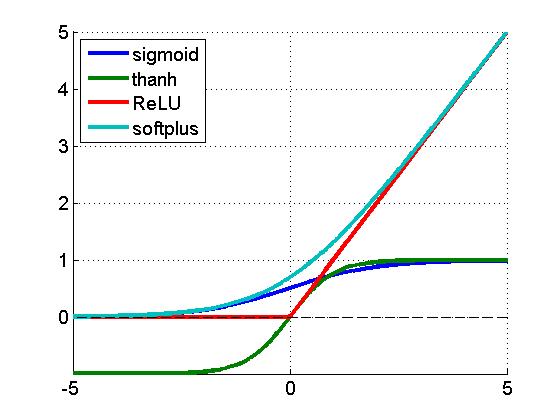
激活函数
MLP代码实现
# 代码汇总
# 1.读取数据
import pandas as pd
df = pd.read_excel('stock_customer_churn.xlsx')
# 2.划分特征变量和目标变量
X = df.drop(columns='是否流失')
y = df['是否流失']
# 3.划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1 )
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform( X_train )
X_test = scaler.transform( X_test )
# 4.模型搭建
from sklearn.neural_network import MLPClassifier
## hidden_layer_sizes的值为[100],这意味着模型中只有一个隐藏层,而隐藏层的节点数为100.
## 如果我们给hidden_layer_sizes定义为[10,10],就意味着模型中有两个隐藏层,每层有10个节点。
model = MLPClassifier( activation = 'relu', hidden_layer_sizes=(500,500) )
model.fit( X_train , y_train )
# 5.模型使用1 - 预测数据结果
y_pred = model.predict(X_test)
# print(y_pred[0:100]) # 打印预测内容的前100个看看
# 查看全部的预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score) # 打印整体的预测准确度
# 6.模型使用2 - 预测概率
y_pred_proba = model.predict_proba(X_test)
# print(y_pred_proba[0:5]) # 打印前5个客户的分类概率
from sklearn.metrics import classification_report
report = classification_report( y_pred, y_test )
print(report)
0.8102224325603408
precision recall f1-score support
0 0.92 0.84 0.88 1726
1 0.49 0.66 0.56 387
accuracy 0.81 2113
macro avg 0.70 0.75 0.72 2113
weighted avg 0.84 0.81 0.82 2113
model.score(X_test, y_test)
0.8102224325603408
逻辑回归和神经网络的比较
逻辑回归的准确率0.7983
# 代码汇总
# 1.读取数据
import pandas as pd
df = pd.read_excel('stock_customer_churn.xlsx')
# 2.划分特征变量和目标变量
X = df.drop(columns='是否流失')
y = df['是否流失']
# 3.划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# 4.模型搭建
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
# 5.模型使用1 - 预测数据结果
y_pred = model.predict(X_test)
# print(y_pred[0:100]) # 打印预测内容的前100个看看
# 查看全部的预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score) # 打印整体的预测准确度
# 6.模型使用2 - 预测概率
y_pred_proba = model.predict_proba(X_test)
# print(y_pred_proba[0:5]) # 打印前5个客户的分类概率
from sklearn.metrics import classification_report
report = classification_report( y_pred, y_test )
print(report)
0.7983909133932797
precision recall f1-score support
0 0.91 0.83 0.87 1733
1 0.46 0.63 0.53 380
accuracy 0.80 2113
macro avg 0.68 0.73 0.70 2113
weighted avg 0.83 0.80 0.81 2113