- HDFS的块大小设计原则
- HDFS常用shell命令
- HDFS的读写流程
第一章 HDFS概述
1.1 HDFS产生背景和定义
1.1.1 产生背景
大数据时代,需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统,HDFS就是分布式文件管理系统的一种
1.1.2 HDFS定义
- HDFS(Haddop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由多个服务器联合起来实现功能
- 适用场景:适合一次写入,多次读出的场景。
1.2 HDFS优缺点
优点:
- 高容错性
- 适合处理大数据
- 可构建在廉价机器上
缺点: - 不适合低延时数据访问
- 无法高效地对大量小文件进行存储
- 不支持并发写入、文件随机修改:仅支持数据数据append
1.3 HDFS组成架构
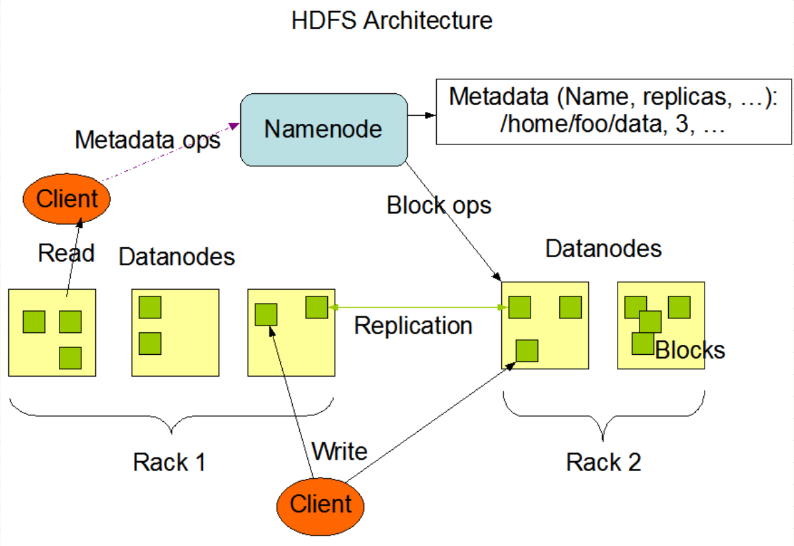
- NameNode(NN): 管理者
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据库(Block)映射信息
- 处理客户端读写请求
- DataNode(DN):执行实际操作
- 存储实际数据库
- 执行数据库的读写操作
- Client:客户端
- SecondaryNameNode(2NN):并非NameNode的热备。当NameNode挂掉的时候,不能马上替换NameNode并提供服务
- 辅助NameNode,分担其工作量,比如:定期合并fsimage和Edits,并推送给NameNode
- 在紧急情况下,可辅助恢复NameNode
1.4 HDFS文件块大小
HDFS文件在物理上是分块存储的,块大小默认为128M,这是如何计算的?
- 寻址时间约为10ms
- 寻址时间约为传输时间1%,传输时间为1000ms = 1s
- 磁盘传输速率约为100m/s
- block大小 = 1 x 100 = 100m左右
第二章 HDFS的Shell操作
2.1 准备工作
- 启动Hadoop集群
atguigu@hadoop102 $ sbin/start-dfs.sh
atguigu@hadoop103 $ sbin/start-yarn.sh - 输出这个命令的参数(查看命令帮助信息)
atguigu@hadoop102 $ hadoop fs -help rm - 创建/sanguo文件夹
atguigu@hadoop102 $ hadoop fs -mkdir /sanguo
2.2 上传
- -moveFromLocal:从本地剪切粘贴到HDFS
hadoop fs -moveFromLocal ./shuguo.txt /sanguo
- -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
hadoop fs -copyFromLocal weiguo.txt /sanguo
- -put:等同与copyFromLocal,生产环境更习惯使用put
hadoop fs -put ./wuguo.txt /sanguo
- -appendToFile:追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
2.3 下载
- -copyToLocal:从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuguo.txt ./
- -get:等同于copyToLocal,生产环境更习惯使用get
hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
2.4 HDFS直接操作
- -ls:显示目录信息
- -cat:显示文件内容
- -tail:显示一个文件末尾1kb的数据
- -chgrp, -chmode, chown:与Linux文件系统中的用法一样,修改文件所属权限
- -mkdir:创建路径
- -cp:从HDFS的一个路径拷贝到HDFS的另一个路径
- -mv:在HDFS目录中移动文件
- -rm:删除文件或文件夹
- -rm -r:递归删除目录及目录里面的内容
- -du:统计文件夹的大小信息
- -setrep:设置HDFS中文件的副本数量
第三章 HDFS的API操作
第四章 HDFS的读写流程
4.1 HDFS的写数据流程
4.1.1 剖析文件写入

4.1.2 网络拓扑-节点距离计算
- 到达共同祖先的距离总和
4.1.3 机架感知(副本存储节点选择)
副本存储节点选择
- 本地节点
- 其他机架一个节点
- 其他机架另一个节点
4.2 HDFS的读数据流程
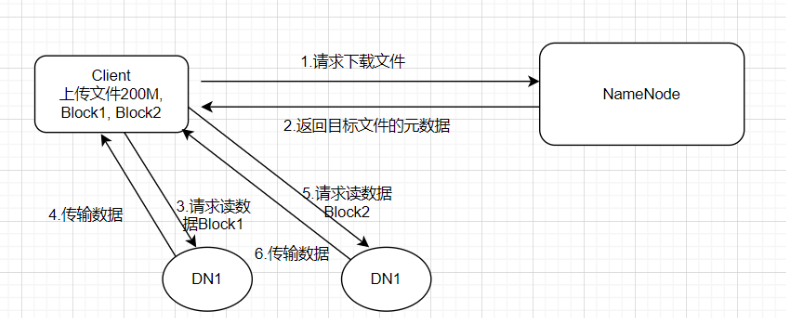
第五章 NameNode和SecondaryNameNode
5.1 FSimage和Edits解析
- Fsimage文件:HDFS文件系统元数据的一个永久性检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息
- Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中
- seen_txid文件:保存一个数字,就是最后一个edits_的数字
- 查看oiv和oev命令
oiv
oev
- 基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径
5.2 CheckPoints时间设置
- 通常情况下,SecondaryNameNode每隔一小时执行一次,见hdfs-default.xml
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
- 一分钟检查一次操作次数,当操作次数达到一百万时,SecondaryNameNode执行一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<descriptiong>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>60s</value>
<description>一分钟检查一次操作次数</description>
</property>
第六章 DataNode
6.1 DataNode工作机制
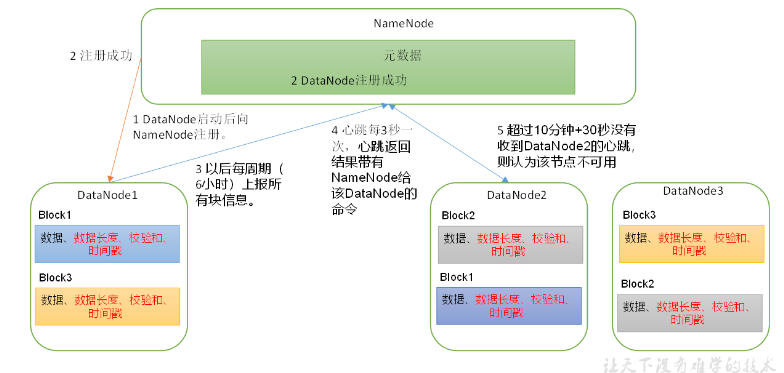
- DN向NN汇报当前解读信息的时间间隔,默认为6小时
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
- DN扫描自己节点块信息列表的时间,默认为6小时
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>21600s</value>
<description>Interval in seconds for Datanode to scan data
directories and reconcile the difference between blocks in memory and on the disk. Support multiple time unit suffix(case insensitive), as described in dfs.heartbeat.interval.
</description>
</property>
6.2 掉线时限参数设置

<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>