Making your Hardware Accelerator TVM-ready with UMA
本文介绍 Universal Modular Accelerator Interface(UMA),UMA提供了易用的API将新的硬件加速器整合进TVM。
展示如何使用UMA将硬件加速器整合进TVM,不过目前还没有一个最优的方案来解决这个问题,UMA目标在于提供一个稳定的Python API来整合多种硬件加速器类别到TVM。
经过学习,将认识到UMA API在3个例子中的使用,将Vanilla,Strawberry和Chocolate整合进TVM。
Vanilla
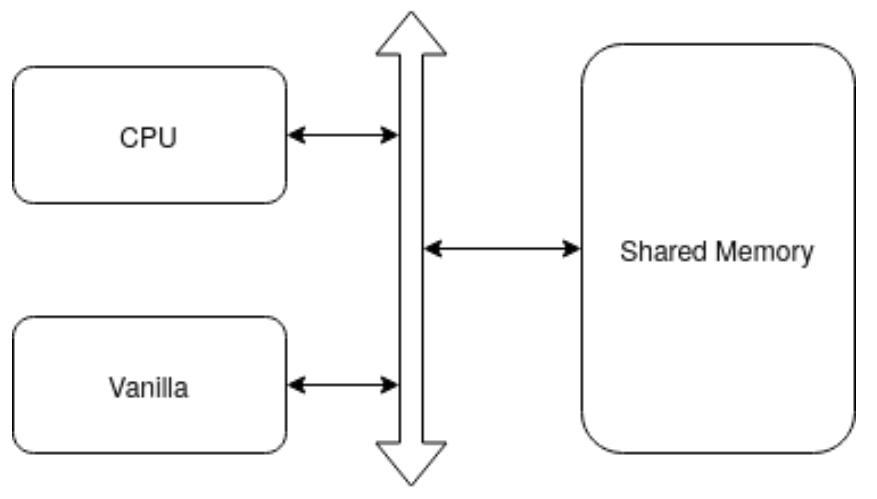
Vanilla是一个简单的加速器,由一个MAC数组组成,没有内存,只能处理Conv2D层,其他所有层都在CPU上执行,CPU和Vanilla使用一个共享内存。
Vanilla有C的接口vanilla_conv2dnchw(...)来执行Conv2D算子,接受指针传入参数和输出,以及Conv2D的维度:oc,iw,ih,ic,kh,kw
int vanilla_conv2dnchw(float* ifmap, float* weights, float* result, int oc, int iw, int ih, int ic, int kh, int kw);
脚本uma_cli创建了节点的框架,将API-calls转换为新加速器的UMA-API
对于Vanilla,使用--tutorial vanilla加入所有需要的文件
pip install inflection
cd $TVM_HOME/apps/uma
python uma_cli.py --add_hardware vanilla_accelerator --tutorial vanilla
uma_cli.py在vanilla_accelerator目录下创建了这些文件
backend.py
codegen.py
conv2dnchw.cc
passes.py
patterns.py
run.py
strategies.py
Vanilla后端
为Vanilla创建后端可以在vanilla_accelerator/backend.py中找到
class VanillaAcceleratorBackend(UMABackend):
"""UMA backend for VanillaAccelerator."""
def __init__(self):
super().__init__()
self._register_pattern("conv2d", conv2d_pattern())
self._register_tir_pass(PassPhase.TIR_PHASE_0, VanillaAcceleratorConv2DPass())
self._register_codegen(fmt="c", includes=gen_includes)
@property
def target_name(self):
return "vanilla_accelerator"
定义卸载模式
指定Conv2D卸载到Vanilla,通过Relay数据流模式定义(DFPattern),在vanilla_accelerator/patterns.py中
def conv2d_pattern():
pattern = is_op("nn.conv2d")(wildcard(), wildcard())
pattern = pattern.has_attr({"strides": [1, 1]})
return pattern
将Conv2D算子从输入图映射到Vanilla的低级函数调用vanilla_con2dchw(...),TIR passes VanillaAcceleratorConv2DPass 将注册到 VanillaAcceleratorBackend。
代码生成
文件vanilla_accelerator/codegen.py定义了静态的C代码,将加入TVM的C-Codegen生成的代码中,位于gen_includes目录下,这里C代码将被加入Vanilla的低级库vanilla_conv2dnchw()
def gen_includes() -> str:
topdir = pathlib.Path(__file__).parent.absolute()
includes = ""
includes += f'#include "{topdir}/conv2dnchw.cc"'
return includes
如上面展示的,VanillaAcceleratorBackend 通过self._register_codegen注册到UMA
self._register_codegen(fmt="c", includes=gen_includes)
创建神经网络,并在Vanilla上面运行
为了展示UMA的功能,将为Conv2D层创建C代码,然后在Vanilla加速器上运行,文件vanilla_accelerator提供了一个样例来运行Conv2D层,使用Vanilla的C API
def main():
mod, inputs, output_list, runner = create_conv2d()
uma_backend = VanillaAcceleratorBackend()
uma_backend.register()
mod = uma_backend.partition(mod)
target = tvm.target.Target("vanilla_accelerator", host=tvm.target.Target("c"))
export_directory = tvm.contrib.utils.tempdir(keep_for_debug=True).path
print(f"Generated files are in {export_directory}")
compile_and_run(
AOTModel(module=mod, inputs=inputs, outputs=output_list),
runner,
interface_api="c",
use_unpacked_api=True,
target=target,
test_dir=str(export_directory),
)
main()
通过运行vanilla_accelerator/run.py这个输出文件,创建为模型库格式(MLF)
输出
Generated files are in /tmp/tvm-debug-mode-tempdirs/2022-07-13T13-26-22___x5u76h0p/00000
检查创建的文件
输出
cd /tmp/tvm-debug-mode-tempdirs/2022-07-13T13-26-22___x5u76h0p/00000
cd build/
ls -1
codegen
lib.tar
metadata.json
parameters
runtime
src
评估创建的C代码,找codegen/host/src/default_lib2.c文件
cd codegen/host/src/
ls -1
default_lib0.c
default_lib1.c
default_lib2.c
在default_lib2.c中可以看见创建代码调用了Vanilla的C API,然后执行Conv2D层
TVM_DLL int32_t tvmgen_default_vanilla_accelerator_main_0(float* placeholder, float* placeholder1, float* conv2d_nchw, uint8_t* global_workspace_1_var) {
vanilla_accelerator_conv2dnchw(placeholder, placeholder1, conv2d_nchw, 32, 14, 14, 32, 3, 3);
return 0;
}
Strawberry
将要完成
Chocolate
将要完成