PostgreSQL存储大量base64
背景
-
现场反馈数据库pg_wal日志有2.3TB,占满了磁盘空间,数据库处于宕机状态。并且数据库没有做备份。日志堆积的主要原因是配置的归档失败了。
-
排查过程中发现主要以下几点问题:
-
1、数据库配置了归档,但是归档失败
-
2、数据库开启了逻辑复制,复制处于宕机状态
-
3、数据库未做备份
重新配置归档后发现归档太慢了于是关闭归档,清理掉所有的归档日志!先将数据库启动,然后针对全库先做一个基础备份。
pg_dump
并行压缩备份,使用pg_dump做一次全库的基础备份耗时6小时,整个库的大小不过500GB,备份耗时6小时,不太正常
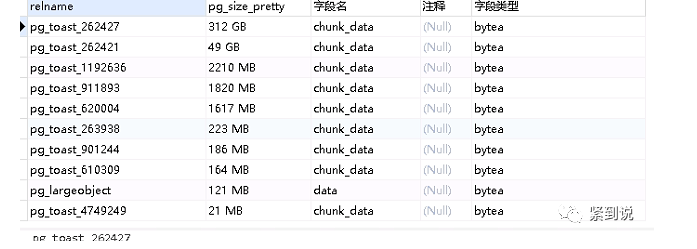
查看大表发现表中存储的是json数据,json中包含base64数据,总共1400w数据占用323GB,平均每行数据大约24KB
另外数据库中t_writ_history有323GB,t_writ有54GB,其中toast表分别占用312GB,49GB。
从数据库角度来看库中最大的表就是pg_toast_262427和pg_toast_262421,这两表就是t_wirt_history和t_writ表的toast表
在使用pg_dump备份较慢后,尝试使用pg_basebackup进行备份,且保留最近三天的备份
pg_basebackup
使用pg_basebackup备份耗时8小时,这个结果肯定不行,随着数据增长可能一晚上备份不完整个库

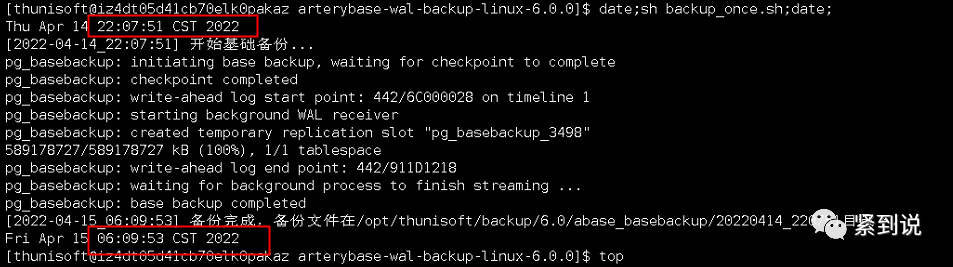
使用pigz压缩pg_basebackup备份
使用pigz压缩就不使用basebackup的-z压缩了。我们使用-p 16cpu并行压缩,数据从500GB+压缩到300GB+,耗时2小时。(还能接受)
pg_basebackup -U sa -p6543 -F t -P -v -Xf -D - | pigz -6 -p 16 > /data/pg_basebackup/test.tar.gz
但是新的问题来了:
运维反馈压缩备份文件四月到五月一个月从300G增长了600GB,导致空间不足,也就是说使用并行压缩不下去了!
四月:原库大小为540GB,备份完的数据文件大小为325GB
五月:数据库大小735GB,备份后的大小是683GB
备份时间从2小时增长为4个小时,一个月的时间数据库增长了200GB,而且可以看出备份文件压缩后没什么效果。
备份数据为什么压缩后效果不明显,以及为什么增长这么快呢?查看增长最快的就是前面提到的t_wirt_history的toast表数据
TOAST理论
在 Postgres 中,页 block 是数据在文件存储中的基本单位,其大小是固定的且只能在编译期指定,之后无法修改,默认的大小为8KB。同时,Postgres 不允许一行数据跨页存储,那么对于超长的行数据 tuple,Postgres 就会启动 TOAST,具体就是采用压 compress 目前主要有两种压缩方式pglz和lz4(pg14新增)和切片 toast 的方式。如果启用了切片,实际数据存储在与该表关联的 toast 表中,这种存储方式叫行外存储 OUT-OF-LINE。Postgres 要求物理存储数据时单页内最少要能够存放4条记录tuple,block=8k,即单条数据行 tuple(注意不是指单个字段)约超过2k(TOAST_TUPLE_THRESHOLD )就会触发相应的存储机制(压缩、toast)。
前面我们看到库中pg_toast_262427表有312GB,这说明存储的json数据触发了toast机制,将数据存储到taost。
每个表字段有四种TOAST策略:
TOAST表,这种存储方式叫行外存储。一般当一条记录压缩后的大小大于TOAST_TUPLE_THRESHOLD(通常是page_size/4即2kB)这个值时,会存储到TOAST表。
PLAIN:避免压缩和行外存储。只有那些不需要TOAST策略就能存放的数据类型允许选择(例如int类型),而对于text这类要求存储长度超过页大小的类型,是不允许采用此策略的
EXTENDED:允许压缩和行外存储。一般会先压缩,如果还是太大,就会行外存储(默认)
EXTERNAL:允许行外存储,但不许压缩。类似字符串这种会对数据的一部分进行操作的字段,采用此策略可能获得更高的性能,因为不需要读取出整行数据再解压。
MAIN:允许压缩,但不许行外存储。不过实际上,为了保证过大数据的存储,行外存储在其它方式(例如压缩)都无法满足需求的情况下,作为最后手段还是会被启动。因此理解为:尽量不使用行外存储更贴切。一般只有在变长的字段上且存储模式不是PLAIN时才能启用TOAST。
这里我们来验证下:
--1.1建表
abase=> create table test_jsonb(c_bh char(32),j_jsonb jsonb);
CREATE TABLE
--插入数据
insert into test_jsonb(c_bh,j_jsonb) select replace(uuid_generate_v4()::text,'-',''),'{"c_xm":"张三","c_mx":{"c_ssdw":"一大队","c_dwbm":"11"}}' from generate_series(1,1000000);
update test_jsonb set j_jsonb = j_jsonb ||E'{"c_text":"5ZWK5pKS5pem5rOV5pKS5pem5rO......"}'::jsonb
--查看表的大小
db_sqlfx=# select * from pg_size_pretty(pg_total_relation_size('test_jsonb'));
pg_size_pretty
----------------
1492 MB
(1 row)
--查看Storage为extended ^
db_sqlfx=# \d+ test_jsonb
Table "public.test_jsonb"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
---------+---------------+-----------+----------+---------+----------+--------------+-------------
c_bh | character(32) | | | | extended | |
j_jsonb | jsonb | | | | extended | |
Access method: heap
--test_jsonb对应的toast表
db_sqlfx=# select relname from pg_class where oid=(select reltoastrelid from pg_class where relname='test_jsonb');
relname
------------------
pg_toast_8420564
(1 row)
--toast中并没有数据
db_sqlfx=# select chunk_id,chunk_seq,length(chunk_data) from pg_toast.pg_toast_8420564;
chunk_id | chunk_seq | length
----------+-----------+--------
(0 rows)
--可以看到列大小为645bytes,但是实际的列大小是28kb,所以启用了toast,但是在pg_toast_8420564表中没有查询到数据这是为什么呢?
db_sqlfx=# SELECT pg_size_pretty(pg_column_size("j_jsonb")::bigint) columnSize,pg_size_pretty(octet_length("j_jsonb"::text)::bigint) octSize,c_bh
FROM test_jsonb limit 100;
columnsize | octsize | c_bh
------------+---------+----------------------------------
645 bytes | 28 kB | d412ed33d96e4dfb87b9201b9e04bd4d
645 bytes | 28 kB | 1da59df8bcf647488fe081433cc81318
645 bytes | 28 kB | ea8bee5213b042a5a8ed507aac4dd13b
645 bytes | 28 kB | 24c36992db4449cf93aa39394b8d1ac1
645 bytes | 28 kB | c11ab1cbad7741daa2ad17ce065356cb
645 bytes | 28 kB | 3a4f431e7923406f93e3fb76ff33ecdf
645 bytes | 28 kB | 3a0986c173014b46991929f31816f283
645 bytes | 28 kB | b1009863a8c7432ba34052942055e615
645 bytes | 28 kB | 7fd1e7deacd24215be2df72941a3576c
645 bytes | 28 kB | 218496393df845399f1bbf2b648ca9e8
645 bytes | 28 kB | b11f29a7495c4330a8d445c24d7b7bd1
645 bytes | 28 kB | 1090fbf3ba7149da8e18be527ee526cf
645 bytes | 28 kB | 0c193c48235b4e5eb5aa60f75bc2f22b
我们看下备份的实际大小:
[05-24 17:20:25] thunisoft@gauss01:/opt/thunisoft
$ date;pg_dump -Usa db_sqlfx -t public.test_jsonb -f /opt/thunisoft/test_jsonb.dump;date;
Tue May 24 17:27:55 CST 2022
Tue May 24 17:34:56 CST 2022
[05-24 17:34:56] thunisoft@gauss01:/opt/thunisoft
$ ll -ls test_jsonb.dump
27G -rw-rw-r-- 1 thunisoft 27G May 24 17:34 test_jsonb.dump
--备份后27GB数据
--查看表大小不过1.5GB,但是备份出来却有27GB,原因就是toast启用了压缩功能
db_sqlfx=# select * from pg_size_pretty(pg_total_relation_size('test_jsonb'));
pg_size_pretty
----------------
1492 MB
(1 row)
--查看toast表
db_sqlfx=# SELECT relname FROM pg_class WHERE oid = (SELECT reltoastrelid FROM pg_class WHERE relname = 'test_jsonb');
relname
------------------
pg_toast_8420564
(1 row)
--我们查看toast表却并没有数据,这是为什么呢?
db_sqlfx=# select * from pg_toast.pg_toast_8420564;
chunk_id | chunk_seq | chunk_data
----------+-----------+------------
(0 rows)
--postgre中text、json、jsonb等类型的字段会在toast表里存储,故通过pg_column_size表查询出来的列数据是经过toast表序列化、
--压缩之后的大小,这个大小和它们的字符串表示(包括dump文件)会有较大出入,故建议查询大字段的字符串表示时大小,
--使用octet_length(col):
--这样查看整个json列的大小总和确实为27GB,这和上面备份出来的数据大小一样
db_sqlfx=# select pg_size_pretty(sum(octet_length("j_jsonb"::text)::bigint)) octSize
db_sqlfx-# FROM test_jsonb;
octsize
---------
27 GB
(1 row)
--使用pg_column_size(j_jsonb)可以看到列大小才809没有达到2k
db_sqlfx=# select length(j_jsonb::varchar),pg_column_size(j_jsonb::varchar),pg_column_size(j_jsonb) from test_jsonb limit 1;
length | pg_column_size | pg_column_size
--------+----------------+----------------
65544 | 65548 | 809
(1 row)
有一个问题,为什么现场的toast表有值,而复现出来的toast中没有值,但是复现的表中的jsonb列长度又超过了2k,但是没有触发toast机制?
猜测做了压缩,但是还没有达到触发行外存储的级别:length的长度是超过了2k的,但是pg_column_size(j_jsonb)还没到2k
验证
db_sqlfx=# create table t1 (id int,name varchar);
CREATE TABLE
--extended是先压缩,后行外存储
db_sqlfx=# \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-------------------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
name | character varying | | | | extended | |
Access method: heap
db_sqlfx=# insert into t1 select 1,repeat('abcdef',200);
INSERT 0 1
--单字段存储1200个字符(6*200),字段size是1204,小于2k,不会触发压缩和toast
db_sqlfx=# select length(name),pg_column_size(id),pg_column_size(name) from t1;
length | pg_column_size | pg_column_size
--------+----------------+----------------
1200 | 4 | 1204
(1 row)
--重复2000次,2000*6=12000
db_sqlfx=# insert into t1 select 2,repeat('abcdef',2000);
INSERT 0 1
db_sqlfx=# select length(name),pg_column_size(id),pg_column_size(name) from t1;
length | pg_column_size | pg_column_size
--------+----------------+----------------
1200 | 4 | 1204
12000 | 4 | 153
(2 rows)
--此时我们看size是153,说明发生了压缩
db_sqlfx=# SELECT relname FROM pg_class WHERE oid = (SELECT reltoastrelid FROM pg_class WHERE relname = 't1');
relname
------------------
pg_toast_8981708
(1 row)
--但是toast中还没有值
db_sqlfx=# select * from pg_toast.pg_toast_8981708;
chunk_id | chunk_seq | chunk_data
----------+-----------+------------
(0 rows)
--我们使用md5(random()::text)复制2000次插入
db_sqlfx=# insert into t1 select 3,repeat(md5(random()::text),2000);
INSERT 0 1
--此时我们看奥也触发了压缩
db_sqlfx=# select length(name),pg_column_size(id),pg_column_size(name) from t1;
length | pg_column_size | pg_column_size
--------+----------------+----------------
1200 | 4 | 1204
12000 | 4 | 153
64000 | 4 | 779
(3 rows)
--但toast中还是没有值
db_sqlfx=# select * from pg_toast.pg_toast_8981708;
chunk_id | chunk_seq | chunk_data
----------+-----------+------------
(0 rows)
--我们设置为6000,此时(6000*32=192000)
db_sqlfx=# insert into t1 select 4,repeat(md5(random()::text),6000);
INSERT 0 1
db_sqlfx=# select * from pg_toast.pg_toast_8981708;
db_sqlfx=# select length(name),pg_column_size(id),pg_column_size(name) from t1;
length | pg_column_size | pg_column_size
--------+----------------+----------------
1200 | 4 | 1204
12000 | 4 | 153
64000 | 4 | 779
192000 | 4 | 2240
(4 rows)
--此时我们看toast中已经有值了
db_sqlfx=# select chunk_id,chunk_seq from pg_toast.pg_toast_8981708;
chunk_id | chunk_seq
----------+-----------
8985117 | 0
8985117 | 1
(2 rows)
EXTENDED模式是:允许压缩和行外存储。一般会先压缩,如果还是太大,就会行外存储。这也是为什么我看到一开始toast表中没有数据的原因
结论
1、不要将大量的base64存储到数据库中,这会导致数据库异常笨重,查询会变得很慢
2、表中存储大量的base64会导致备份变得非常慢,大量的toast会让数据库变得更难维护,让数据库变得不安全
3、当表中有大量base64数据时,数据库会触发toast机制,也就是行压缩,所以我们就会遇到查看库大小不大,但是备份出的数据非常大,备份非常慢的情况。上例中查看表只有1.5GB,但是备份出来却有27GB!
4、回到开始的问题备份数据为什么压缩后效果不明显,以及为什么增长这么快呢?
Postgres的toast在存储的时候会做压缩,所以我们看到的表大小实际上是压缩后的,如果不做压缩,直接使用pg_dump备份出来,整个备份文件会变大。所以当使用pigz压缩方式做压缩备份后,备份文件大小也是和pg_relation_size查看到的表大小差不多。