产品官网:https://www.huaweicloud.com/product/hecs-light.html
今天我们采用可靠更安全、智能不卡顿、价优随心用、上手更简单、管理特省心的华为云耀云服务器L实例为例,本篇中,我们将在华为云耀云服务器L实例上配置TensorFlow进行手写数字识别,作为使用云服务器进行深度学习环境配置的入门基础
TensorFlow是一个开源的深度学习框架,用于构建和训练各种机器学习模型,包括神经网络。手写数字识别是一个经典的机器学习问题,TensorFlow提供了强大的工具来解决这类问题。
在Ubuntu服务器上配置使用TensorFlow进行手写数字识别的步骤可以分为以下几个主要步骤:
### 步骤 1: 安装系统依赖
确保系统已安装一些基本依赖,包括Python和pip。【上一篇中已完成】
```bash
sudo apt-get update
sudo apt-get install python3-dev python3-pip
```
### 步骤 2: 在虚拟环境中,安装 TensorFlow
使用pip安装TensorFlow。你可以根据你的需求选择安装CPU版本或GPU版本。
```bash
pip3 install tensorflow
```
### 步骤 3: 编写手写数字识别代码
创建一个Python脚本`digit_recognition.py`,并使用TensorFlow编写手写数字识别的代码。
首先,让我们在myenv环境下创建项目结构目录:
project_root/
│
├── src/
│ ├── digit_recognition/
│ │ ├── digit_recognition.py
│ │ └── 其他源代码文件(如果有)
│
├── 其他项目文件和目录

使用vim创建一个Python脚本`digit_recognition.py`,并使用TensorFlow编写手写数字识别的代码。
vim digit_recognition.py
```python
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 数据预处理
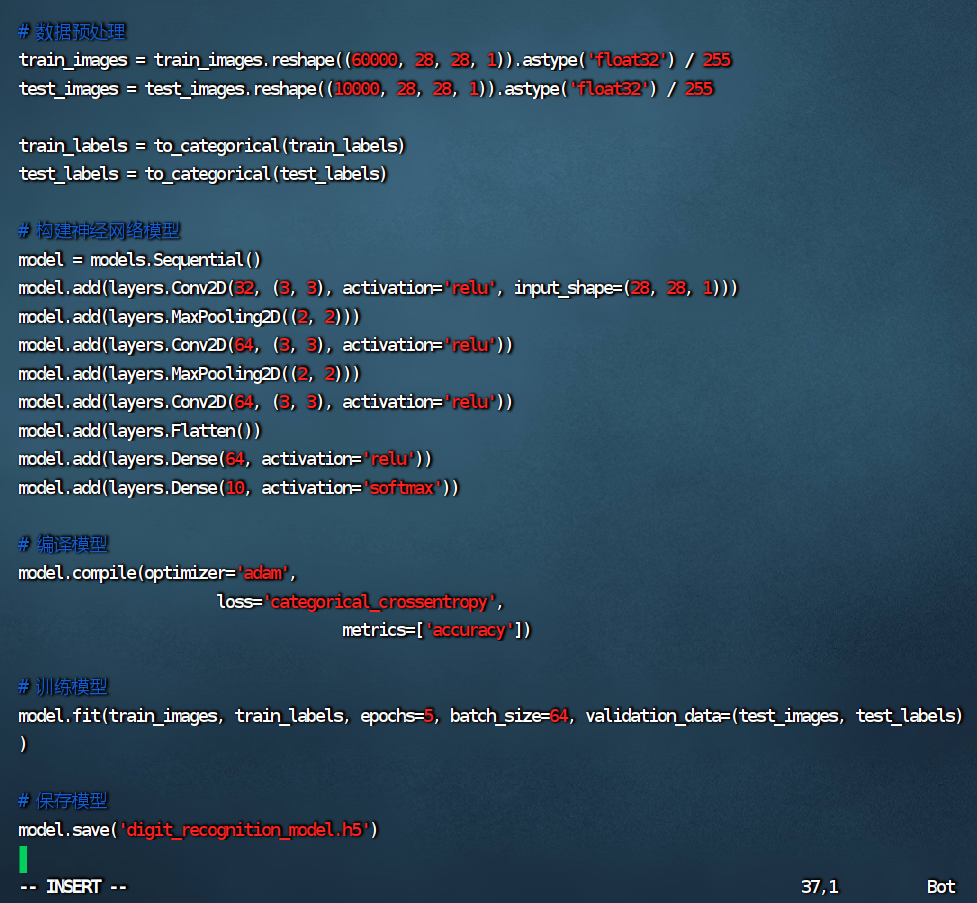
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 构建神经网络模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_data=(test_images, test_labels))
# 保存模型
model.save('digit_recognition_model.h5')
```
### 步骤 4: 运行代码
运行你的手写数字识别代码:
```bash
python3 digit_recognition.py
```
### 步骤 5: 部署模型(可选)
如果你希望在生产环境中使用模型进行预测,你可以将模型部署为一个Web服务、使用TensorFlow Serving或将其集成到你的应用程序中,具体取决于你的需求。
部署模型通常涉及将训练好的模型应用到实际场景中,其中有多种方法可以实现。下面是一种简单的示例,演示如何使用Flask创建一个简单的Web服务,将TensorFlow模型集成到其中。
### 步骤 1: 安装 Flask
首先,确保您的虚拟环境中安装了Flask:
```bash
pip3 install flask
```
### 步骤 2: 创建 Flask 应用
在项目的`src/digit_recognition/`目录下创建一个名为`app.py`的文件,用于创建Flask应用:
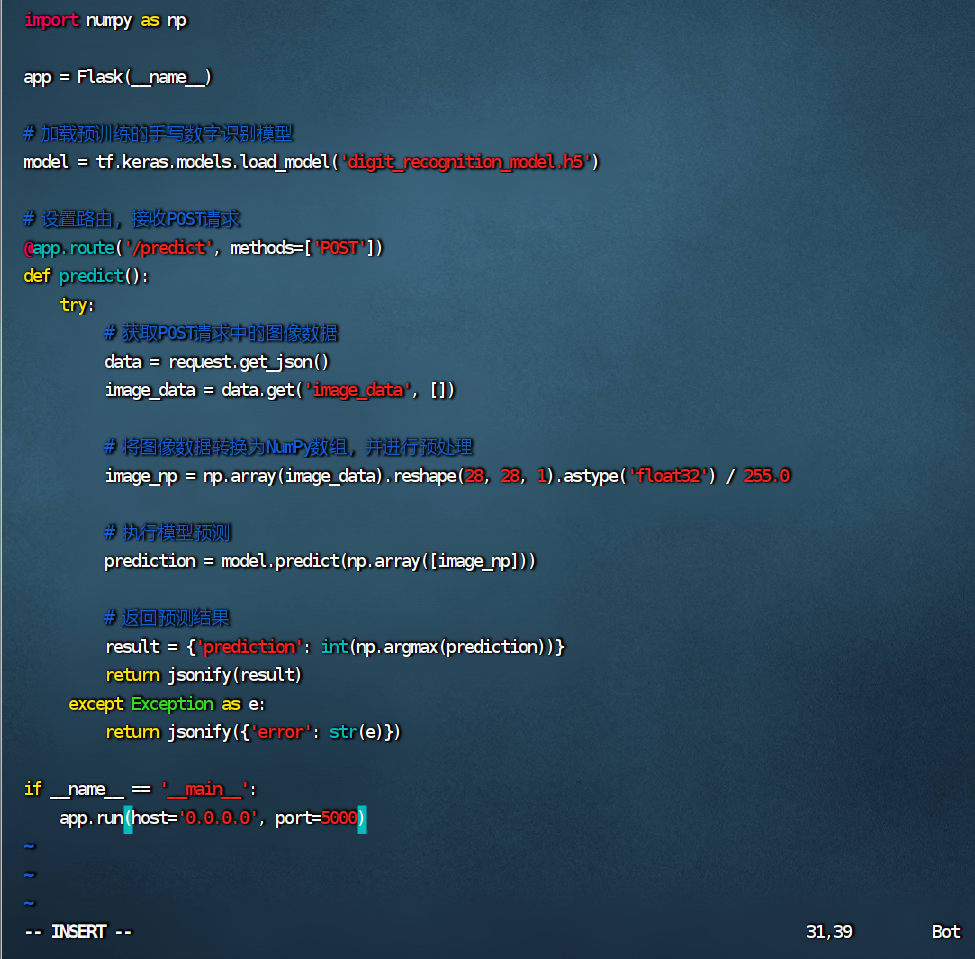
```python
from flask import Flask, request, jsonify
import tensorflow as tf
import numpy as np
app = Flask(__name__)
# 加载预训练的手写数字识别模型
model = tf.keras.models.load_model('digit_recognition_model.h5')
# 设置路由,接收POST请求
@app.route('/predict', methods=['POST'])
def predict():
try:
# 获取POST请求中的图像数据
data = request.get_json()
image_data = data.get('image_data', [])
# 将图像数据转换为NumPy数组,并进行预处理
image_np = np.array(image_data).reshape(28, 28, 1).astype('float32') / 255.0
# 执行模型预测
prediction = model.predict(np.array([image_np]))
# 返回预测结果
result = {'prediction': int(np.argmax(prediction))}
return jsonify(result)
except Exception as e:
return jsonify({'error': str(e)})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
```
### 步骤 3: 启动 Flask 应用
在`src/digit_recognition/`目录下,运行以下命令启动Flask应用:
```bash
python3 app.py
```
Flask应用将在`http://你的ip地址:5000/`上运行。
通过这些步骤,我们成功在 华为云耀云服务器L实例上成功配置并运行TensorFlow进行手写数字识别。