1. 简介
本项目使用Python编程语言进行开始,并基于TensorFlow搭建算法网络模型,对五种常见的垃圾种类进行训练最后达到一个识别精度较高的模型。然后使用Django作为WEB后端框架,开发一个网页端的可视化操作平台,实现用户上传一张垃圾图片识别其名称。
2. 效果图片
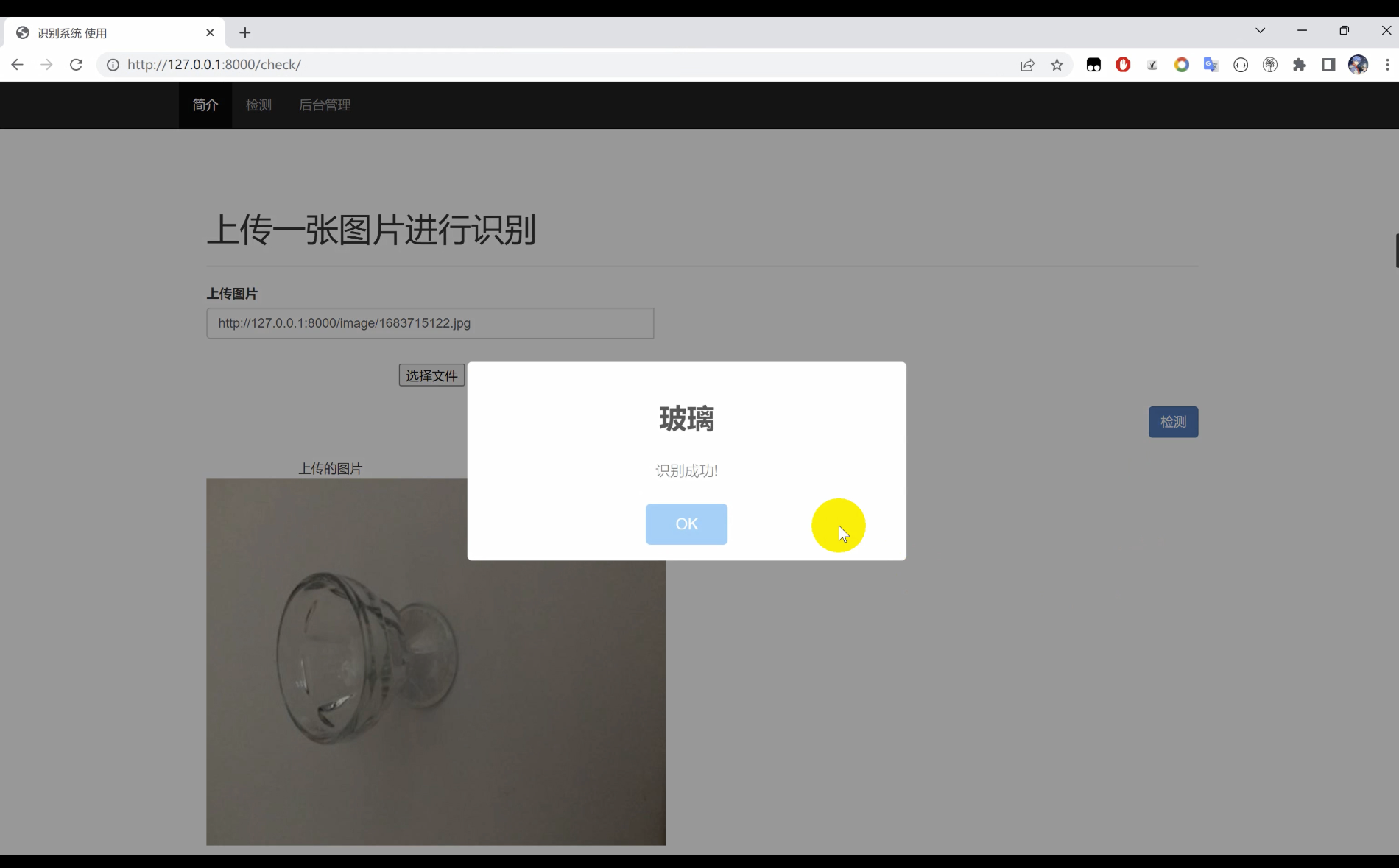
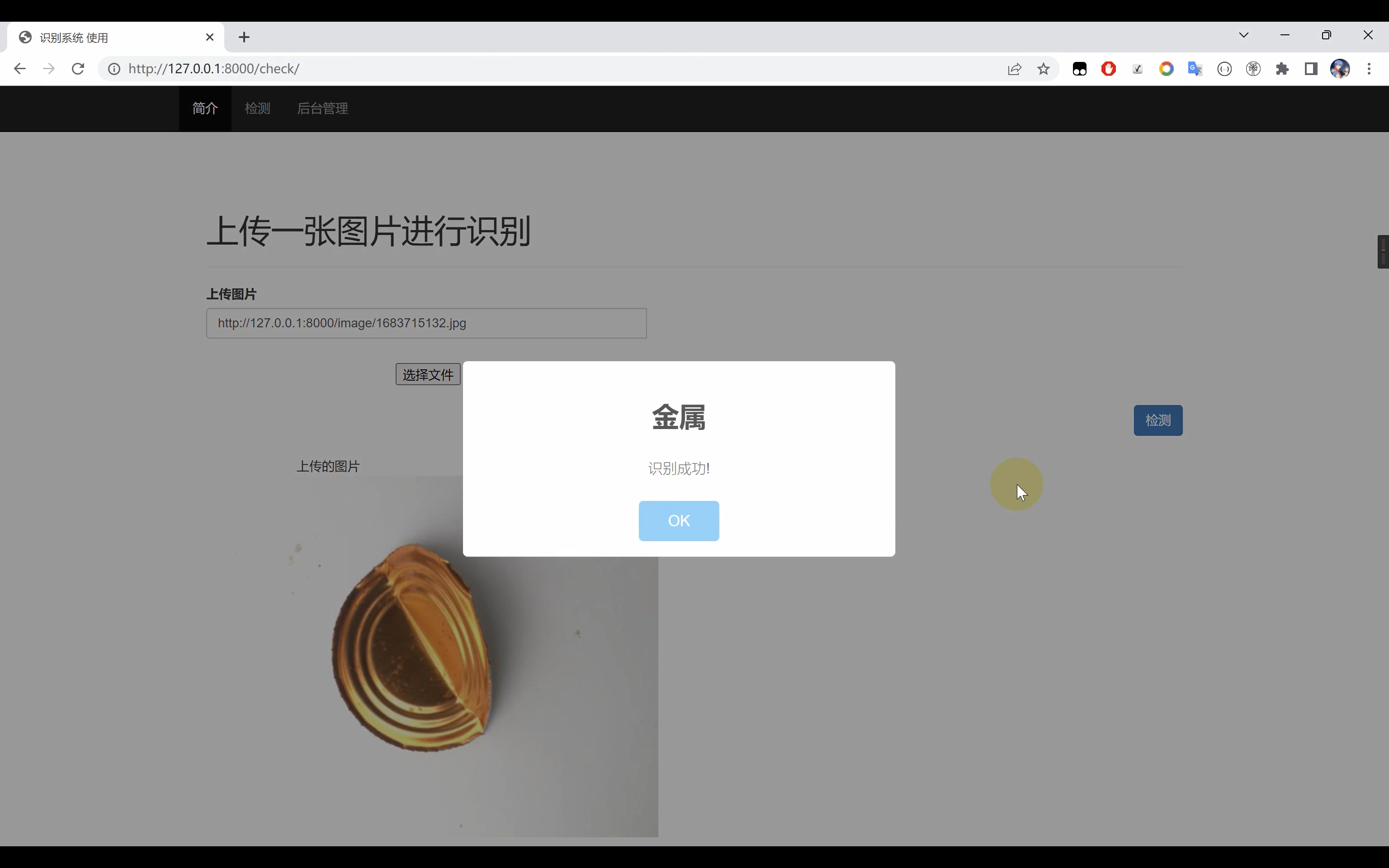
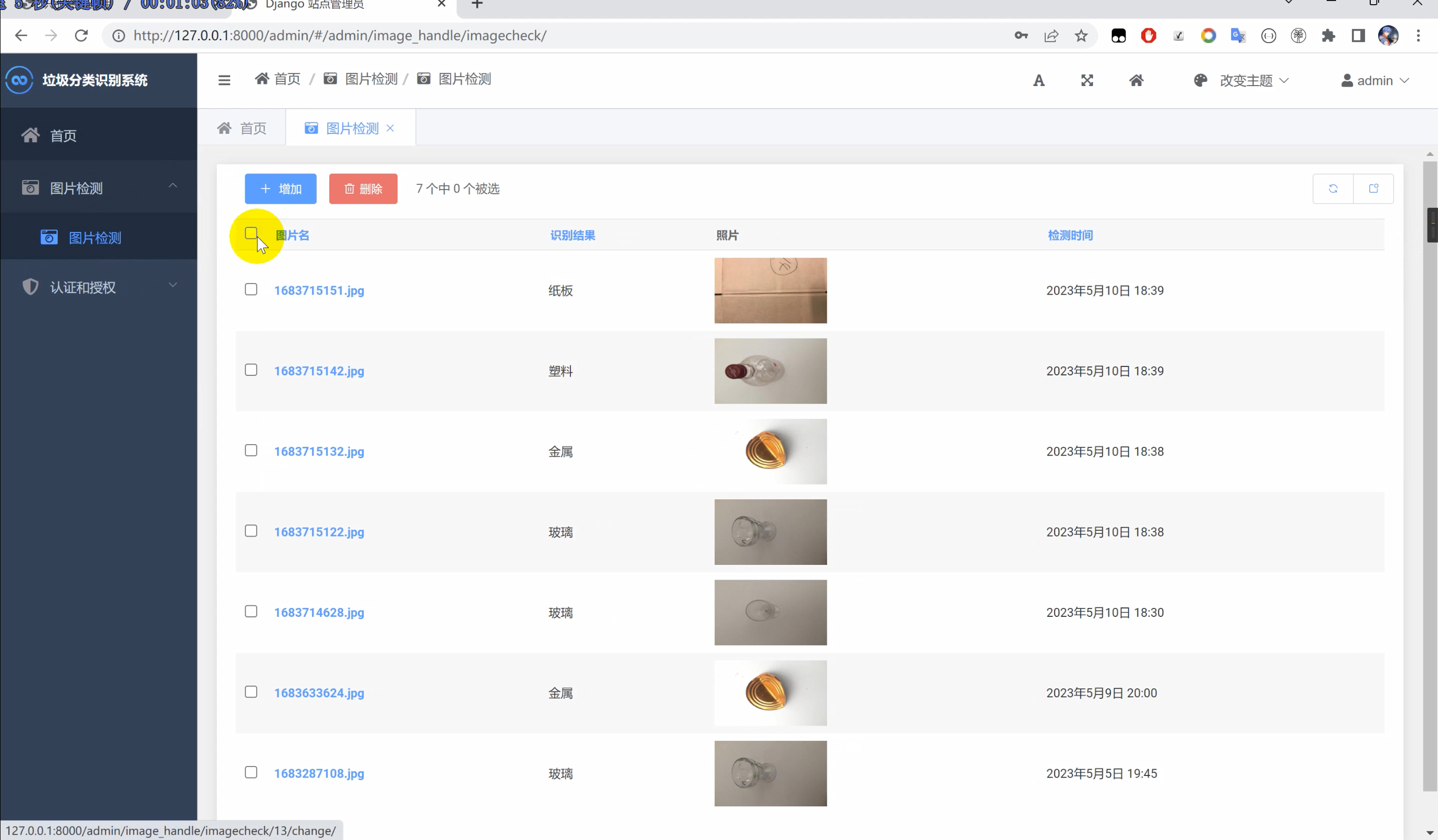
3. 演示视频 and 代码获取
视频+代码:https://s7bacwcxv4.feishu.cn/wiki/XXCLwiITwim7sekGeVgcDHIanTf
4. TensorFlow介绍
TensorFlow是一个由Google Brain团队开发的开源深度学习框架。自从它在2015年发布以来,TensorFlow已经成为了机器学习和深度学习领域的重要工具。以下是Python中TensorFlow的主要特点:
- 灵活性:TensorFlow可以用于各种机器学习任务,不仅仅是深度学习。它支持从线性回归到复杂的神经网络模型。
- 可扩展性:TensorFlow设计之初就考虑到了在多种硬件上运行,从移动设备、桌面设备到服务器和集群。支持多GPU和TPU(Tensor Processing Unit)并行计算。
- 自动微分:TensorFlow提供了自动微分的功能,这使得实现机器学习算法变得容易,特别是对于需要梯度下降的任务。
- 丰富的API:TensorFlow提供了底层和高层的API,使得从研究到生产都可以方便地使用。
- 可视化工具TensorBoard:TensorBoard是一个强大的可视化工具,可以用来展示模型结构、监控训练进度、绘制学习曲线等。
- 模型部署:TensorFlow提供了多种工具和库,如TensorFlow Serving和TensorFlow Lite,来帮助用户轻松地部署和运行模型。
- 生态系统:TensorFlow的生态系统包括了大量的工具和扩展库,如TFX(TensorFlow Extended)用于生产环境、TF-Agents用于强化学习等。
- 持续发展:由于TensorFlow是开源的,并且得到了Google和全球社区的支持,它正在快速地发展和升级。
- 与Keras集成:Keras是一个高级的神经网络API,原本是独立于TensorFlow的。但在后来的版本中,Keras被集成到TensorFlow中,成为tf.keras,使得开发深度学习模型更加简单和直观。
- 多语言支持:虽然Python是TensorFlow最主要的编程语言,但它也支持其他语言,如C++、Java和Go。
以下是一个简单的TensorFlow图像分类的案例,使用的是tf.keras高层API,并基于CIFAR-10数据集,这是一个包含10个类别的60000张32x32彩色图像的数据集。
代码案例:
import tensorflow as tf
from tensorflow.keras import layers, models, datasets
# 1. 加载和预处理数据
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0 # Normalize# 2. 定义模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
# 3. 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 4. 训练模型
model.fit(train_images, train_labels, epochs=10, batch_size=64, validation_data=(test_images, test_labels))
# 5. 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print("\nTest accuracy:", test_acc)
代码介绍:
- 加载和预处理数据:我们从
tf.keras.datasets中加载CIFAR-10数据集,并进行归一化处理,将像素值转化为0到1之间。 - 定义模型:这是一个简单的卷积神经网络(CNN)模型,包含3个卷积层和2个全连接层。使用
Sequential模型来逐层堆叠。 - 编译模型:使用
adam优化器和sparse_categorical_crossentropy损失函数,因为标签是整数。指定accuracy作为评估指标。 - 训练模型:使用训练数据和标签进行模型训练,设置10个epoch,使用64作为批量大小,并提供验证数据集来监控模型在测试数据上的性能。
- 评估模型:使用测试数据集来评估模型的性能。