多级缓存
一般的开发中,请求到达服务器以后,会从缓存中读取想要的数据,如果没有则查找数据库
但是当请求太多时,服务器(如Tomcat)不一定能够承担如此巨大的请求;并且,如果Tomcat服务器能够承受这些巨大的请求压力,也势必考验数据库的抗压能力所以就需要使用多级缓存来给服务器减少压力。
多级缓存示意图
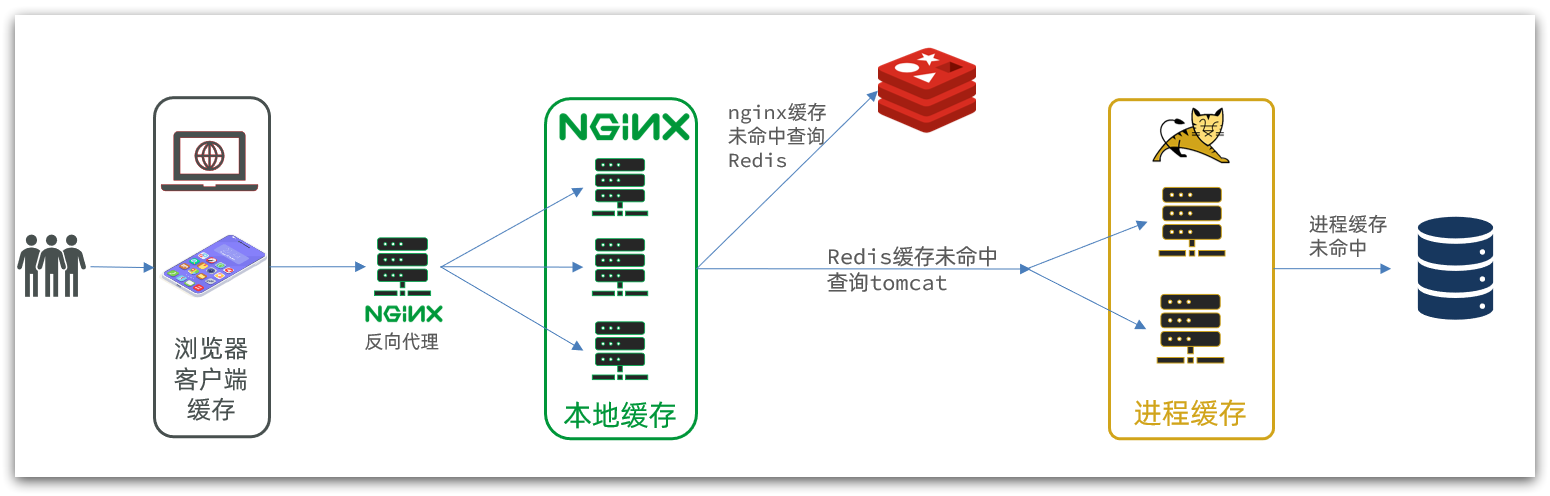
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
如上图中的多级缓存示意图,请求到达第一个Nginx以后,它只是起到反向代理的作用,真正读取Nginx本地缓存在于后面的Nginx集群中。
同理,Redis和进程缓存同样可以使用集群的方式来减少各个模块的压力,本文仅讨论JVM内存缓存的使用方法
JVM进程缓存
进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址:https://github.com/ben-manes/caffeine
下图是Caffeine官方给的各个进程缓存库的表现

很明显,效果就是遥遥领先(余大嘴打钱!),虽然官方有点吹牛逼的意思,但是这也高的太多了。
Caffeine的依赖:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
使用方法很简单,引入依赖,掉库就可以获取Cache对象,只不过泛型是需要自己定义的,<key,value>的类型,其他的比如设置缓存的存在时间,缓存的最大数目等都在下面。
Caffeine
.newBuilder()
//设置缓存的存在时间
.expireAfterWrite(10, TimeUnit.MINUTES)
//最大可以保存的缓存数量
.maximumSize(10L)
.build();

下面给出我在学习中的测试代码,一些方法的特性等都在注释中写出来了:
@Test
void testCaffeineMethod() {
//构建cache对象
Cache<String, String> cache = Caffeine.newBuilder().build();
//存数据
cache.put("first","啊?");
//如果存在则原本返回,不存在则返回null
String first = cache.getIfPresent("first");
System.out.println(first);
//下面这种方法可以将查询缓存,查询数据库等操作集成在一起。
//根据key去缓存中找,如果找到则直接返回,如果不存在则用提供的key去数据库查找,然后将查找到的数据返回并加入缓存中
String second = cache.get("second", key -> {
//TODO 数据库查询逻辑,这里为了方便就随便返回数据了。
return "嗯?";
});
System.out.println(second);
//这里再次测试缓存中是否已经加入了second
String second_ = cache.getIfPresent("second");
System.out.println(second_);
}
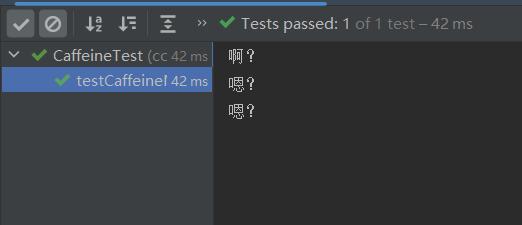
代码执行结果图:
下面是我在学习过程中使用的别人的项目来实战JVM进程缓存机制的,项目前后端分离的,前端Nginx托管,后端SpringBoot+MP+Redis+Caffeine等来实现本地缓存的。其他的我就不往上放了,就贴一下控制器中的代码看下Caffeine使用
起来有多方便。
CaffeineConfig
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache() {
return Caffeine
.newBuilder()
//设置缓存的存在时间
.expireAfterWrite(10, TimeUnit.MINUTES)
//最大可以保存的缓存数量
.maximumSize(10L)
.build();
}
@Bean
public Cache<Long, ItemStock> itemStockCache() {
return Caffeine
.newBuilder()
//设置缓存的存在时间
.expireAfterWrite(10, TimeUnit.MINUTES)
//最大可以保存的缓存数量
.maximumSize(10L)
.build();
}
}
ItemController:
package com.heima.item.web;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.github.benmanes.caffeine.cache.Cache;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.pojo.PageDTO;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import lombok.NonNull;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.stream.Collectors;
@RestController
@RequestMapping("item")
@RequiredArgsConstructor
public class ItemController {
private @NonNull IItemService itemService;
private @NonNull IItemStockService stockService;
private @NonNull Cache<Long, Item> itemCache;
private @NonNull Cache<Long, ItemStock> itemStockCache;
@GetMapping("list")
public PageDTO queryItemPage(
@RequestParam(value = "page", defaultValue = "1") Integer page,
@RequestParam(value = "size", defaultValue = "5") Integer size) {
// 分页查询商品
Page<Item> result = itemService.query()
.ne("status", 3)
.page(new Page<>(page, size));
// 查询库存
List<Item> list = result.getRecords().stream().peek(item -> {
ItemStock stock = stockService.getById(item.getId());
item.setStock(stock.getStock());
item.setSold(stock.getSold());
}).collect(Collectors.toList());
// 封装返回
return new PageDTO(result.getTotal(), list);
}
@PostMapping
public void saveItem(@RequestBody Item item) {
itemService.saveItem(item);
}
@PutMapping
public void updateItem(@RequestBody Item item) {
itemService.updateById(item);
}
@PutMapping("stock")
public void updateStock(@RequestBody ItemStock itemStock) {
stockService.updateById(itemStock);
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
itemService.update().set("status", 3).eq("id", id).update();
}
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id) {
return itemCache.get(id,
key-> itemService.lambdaQuery()
.ne(Item::getStatus, 3)
.eq(Item::getId, key)
.one()
);
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id) {
return itemStockCache.get(id, stockService::getById);
}
}

这俩就是用的Caffeine实现的本地缓存机制。