第五章:对抗搜索
本章讨论在有其他Agent计划与我们对抗时,该如何预先规划。
1. 博弈
当多个Agent一同行动时,Agent自身无法知道其他Agent的行为会对自身带来什么影响,这就导致了问题求解的 「偶发性」。而如果每个Agent的目标之间还是相互冲突的,那就会出现 「博弈」,也就是 对抗搜索。
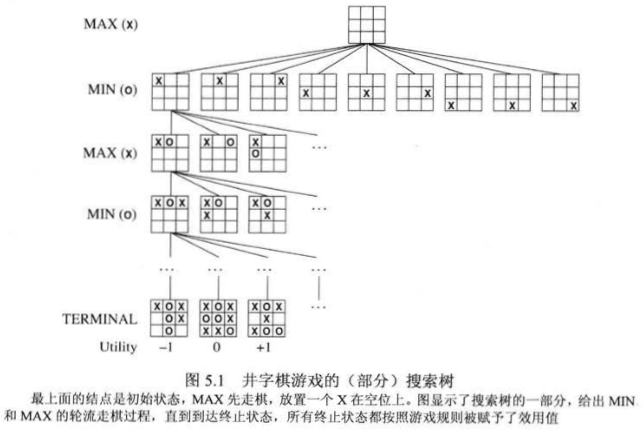
以井字棋为例,我们可以将游戏形式化成含有下列组成部分的搜索问题:
- \(S_0\): 初始状态,规范游戏开始时的情况。
- PLAYER(s):定义此时该谁行动。
- ACTIONS(s):返回此状态下的合法移动合集。
- RESULT(s,a): 转移模型,定义行为结果。
- TERMINAL-TEST(s):终止测试,游戏结束返回真,否则返回假。游戏结束的状态称 终止状态。
- UTILTY(s,p):效用函数(也称目标函数或收益函数),定义游戏者 \(p\) 在终止状态 \(s\) 下的数值。
初始状态、ACTIONS函数和RESULT函数定义了游戏的 「博弈树」 ,其中结点是状态,边是移动。
2. 博弈中的优化决策
给定一棵博弈树,最优策略可以通过检查每个结点的极小极大值来决定,记为MINMAX(n)。如果以博弈者MAX的视角来看,MAX本身更喜欢移动到有极大效用值的状态,而MIN则是喜欢极小值(毕竟对手的最小效用相当于自身的最大效用)。
1. 极小极大算法
极小极大值算法从当前状态计算极小极大决策,它用简单的递归算法计算每个后继的极小极大值。

递归算法先一直前进到树的叶结点,然后随着递归自下而上回溯,通过搜索树把极小极大值回传。采用的是深度优先搜索,这样的时间开销完全不实用,但它仍可以作为对博弈进行数学分析和改进算法的基础。
2. 多人博弈时的最优决策
来看看将极小极大思推广到多人博弈中。假设现在正进行三人博弈,我们用一个三维向量 \((v_A, v_B, v_C)\) 来表示结点的效用值。
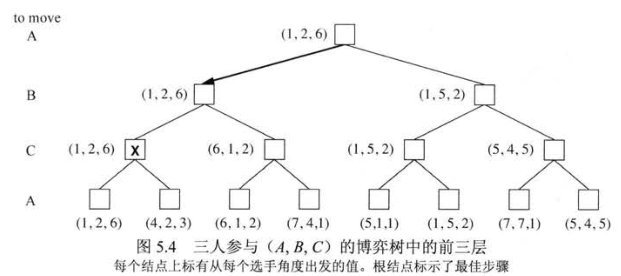
但根据实际情况,最终终止状态的选择会比较复杂,例如,A、B、C三者是各自为营,还是像斗地主那样有共同敌人?这些细节的讨论会放在以后章节。
3. α-β剪枝
极小极大算法的搜索会让状态数剧增,借用剪枝思想,我们可以消除部分搜索树但仍能返回同样正确的结果,这个特殊的技术称为 「α-β剪枝」。
我们说过,对手喜欢选择走对我们而言效用值最低的结点。因此,在记录对手所走的情况时,我们可以只考虑最低效用的结点;对我们而言同理,可以在确定对手的走法后,只考虑效用最高的结点。
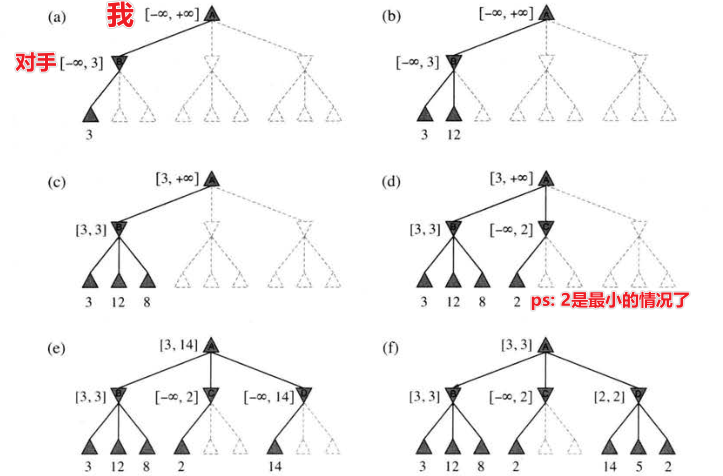
该剪枝的名称取自描述这条路径上的回传值的两个参数 :
\(\alpha\) = 到目前为止路径上发现的 对自身而言 的最佳选择(极大效用)
\(\beta\) = 到目前为止路径上发现的 对对手而言 的最佳选择(极小效用)
4.不完美的实时决策
无论是极小极大算法还是α-β剪枝,都需要搜索部分空间直至终止状态,无法在合理的时间内确定下一步。为此,我们应该尽早截断搜索,应将启发式评估函数用于搜索中的状态,有效地把非终止结点转变为终止结点。
1. 评估函数
对于给定的棋局,评估函数返回对游戏的期望效用值得估计,博弈程序得性能关键取决于此。
第一,评估函数对于终止状态得排序应该和真正得效用函数得排序结果一样:赢>平局>输。
第二,评估函数的计算不能耗时太长。
第三,对于非终止状态,评估函数应该和取胜几率密切相关。
第三点是最值得讨论的,大多数评估函数都要考虑状态的不同 特征 参数,例如象棋中敌我“车”的数量、“马”的数量、“炮”的数量等。评估函数 \(E(s)\) 可以用 加权线性函数 的形式表示:
其中, \(f_i\) 表示某个特征,而 \(w_i\) 表示这个特征对终止状态(胜负)的影响权重。对象棋而言,它可能就是每种棋的价值。
当然,这实际上是以很强的假设为基础的:每个特征的贡献独立于其他特征的值。在更复杂的情况可能还要用到非线性的特征组合(成熟的象棋AI基本就是)。而这仍取决于博弈总结出的经验规律,而后续会讲到 「机器学习」 会帮助我们确定复杂的评估函数的权重。
2. 截断搜索
下面可以对剪枝的逻辑进行修改了,在进行搜索时,我们不再比较效用值,而是比较评估值。我们还要对搜索深度或者时间进行限制,从而截断搜索。但评估函数的近似本质,使这种方法可能会导致错误,所以它适用于那些静态棋局——即评估值不会很快出现大的摇摆变化的棋局。
3. 前向剪枝
待续。
4. 搜索与查表
很多博弈程序子啊开局和残局都使用查表而不是搜索。这样可以节省很多状态。我们仍以象棋为例,开局的前几步行棋没有太多选择,因而可以依赖于许多专家知识和过去的棋局。大概10步之后才会到达一个很少见到的棋局,可以在这时从查表方式切换为搜索。博弈接近尾声时棋局的可能性同样有限,可以又恢复到查表。
5. 随机博弈
很多不可预测的外部事件会把我们推到无法预计的情景中,许多博弈用随机因素来反映这种不可预测性。我们把这叫做 随机博弈 。因此没有明确的极小极大值,只能计算它所有可能结果的平均值(期望)来替代。和极小极大值一样,期望极小极大值的近似评估可以通过在某结点截断搜索并对每个叶结点计算其评估函数来进行。评估函数应该与棋局获胜概率(或者说是棋局的期望效用值)成正线性变换。对于这样的机会博弈树,也可以使用类似α-β剪枝的技术,还可以用蒙特卡洛仿真来评估棋局等等。
6. 部分可观察地博弈
在战争中通常会有侦察兵和间谍来收集信息,同时会对敌人隐瞒信息或虚张声势以搞乱敌方。 「部分可观察博弈」 就具备这些特征。例如军棋和牌类游戏,形式的严峻可能并不能决定最终的胜负(你的血量已如风中残烛,这时AI对博弈过程的跟踪就依赖 信念状态,也就是之前提到过的在给出历史感知信息情况下的逻辑可能状态集合。