作者: Yansheng Li
发表年代: 2023
使用的方法: 无监督领域自适应(UDA)、GAN、ClassMix、边界增强
来源: IEEE TGRS
方向: 语义分割
期刊层次: CCF B;工程技术1区;IF 8.2
文献链接:
https://doi.org/10.1109/TGRS.2023.3313883
Li Y, Shi T, Zhang Y, et al. SPGAN-DA: Semantic-Preserved Generative Adversarial Network for Domain Adaptive Remote Sensing Image Semantic Segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023.
SPGAN-DA:用于领域自适应遥感图像语义分割的语义保留生成对抗网络
要解决什么问题?
减少源域和目标域之间的域偏移对语义分割任务的影响,在遥感图像中实现有效的领域自适应语义分割。
背景:
-
域偏移的主要挑战
a. 跨成像模式
b. 跨地理位置
c. 跨景观布局
-
无监督领域自适应(UDA)方法:通过调整源域和目标域的分布来缓解域偏移问题。
-
现有方法可分为三种
a. 图到图的转换:通过基于生成对抗网络(GAN)的方法转换源域图像,使其在视觉上与目标域相似。有助于训练前减少域差异。
b. 对抗性学习方法:
- 判别器网络:最大限度地减少源特征分布与目标特征分布之间的差异。
- 判别器从语义分割网络中获取特征图,并尝试区分输入的域。同时,对分割网络进行训练,使其能够骗过判别器,并对源域和目标域产生良好的分割效果。
c. 自学习方法:主要思想是利用集合模型或先前模型的高置信度预测作为未标记数据的伪标签,从而迫使模型以隐含的方式学习领域不变特征。
主要贡献:
-
SPGAN:它从源域到目标域进行无偏转换(即视觉内容不变转换),以对齐光谱信息或成像模式。这是通过在GAN框架中引入表征不变和语义保留的约束来实现的,并以端到端的方式进行优化。
-
类别分布对齐(CDA)语义分割模块:进一步缩小不同数据集之间的横向布局差距。
a. 模型输入层,首先通过ClassMix操作将转换图像中的对象粘贴到目标图像上。
b. 模型输出层,提出了边界增强来改进对象边界的性能。
c. 利用这两个方面来协同训练领域自适应语义分割模型。
-
SPGAN-DA可以在经典的遥感跨域语义分割基准上持续发挥良好作用。
具体结构:
-
整体框架
a. 阶段一:通过SPGAN转移风格,把源域映射到目标域。
b. 阶段二:转换后的类目标图像和目标域图像协同训练一个鲁棒的分割模型。
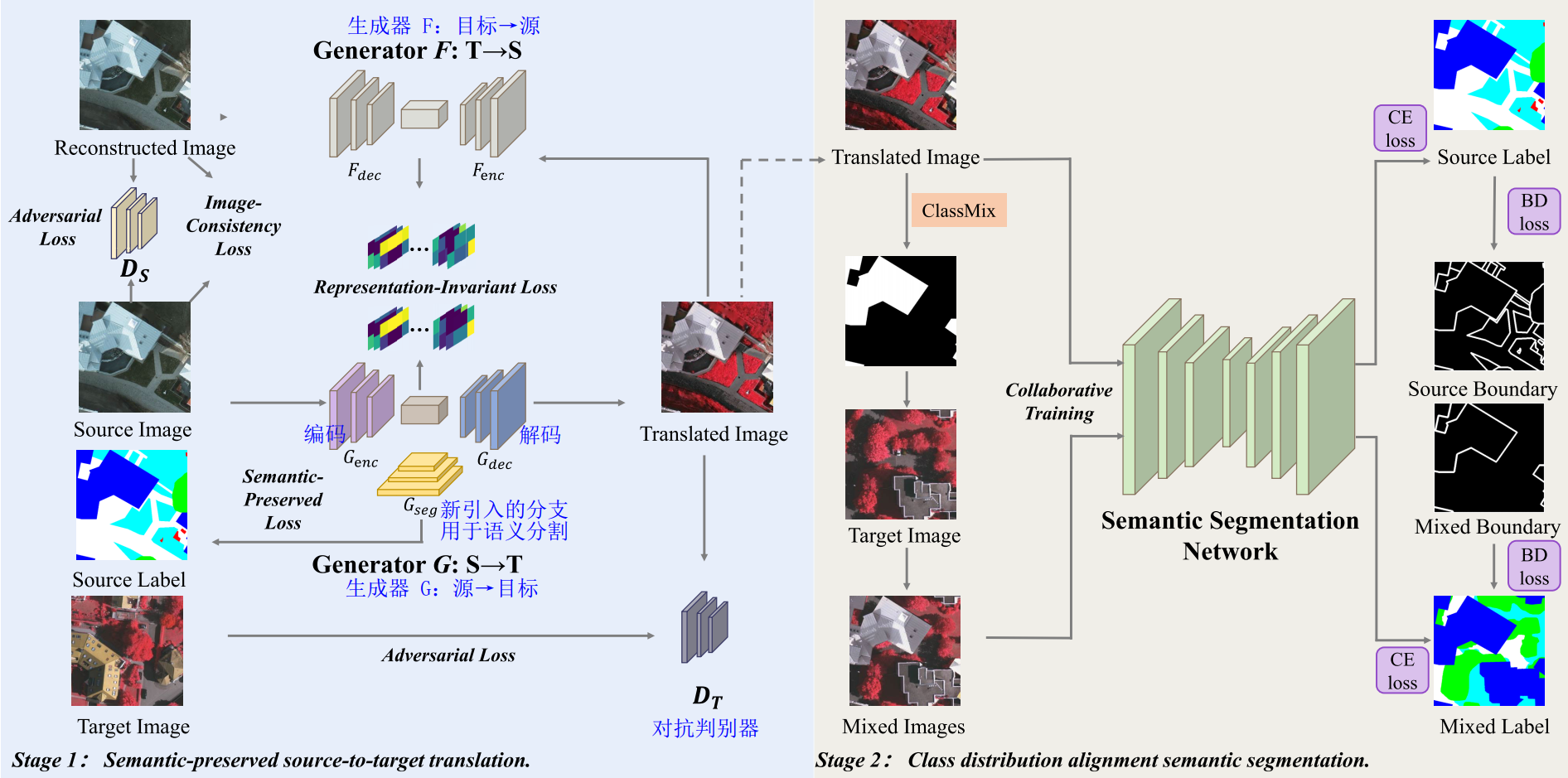
-
语义保留的生成对抗网络(SPGAN):
a. 图像一致性损失:让图像在转换过程中更多地保留源内容
- 源→目标→源,再现原始样本,增强循环一致性
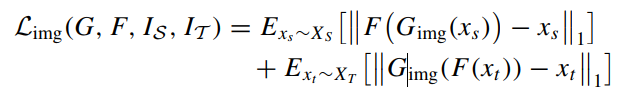
-
\(|| · ||_1\) 表示 \(ℓ1\) 常模,又称曼哈顿常模
-
在概率论和统计学中,锥形符号 (\(\sim\)) 表示 "从......抽取 "或 "从......采样"。例如,\(E_{x\sim X}\) 表示对整个领域 \(X\) 的期望值,其中 \(x\) 是从 \(X\) 中采样的。
b. 表征不变损失:
-
考虑了高层次的表征不变信息,确保两个相反生成网络的中间表征具有相同的分布。
-
这使得生成的图像在分布上更接近目标图像,并能很好地保留细节。
-
可确保表征包含更多的高频和抽象信息,从而提高领域自适应语义分割模型的有效性。
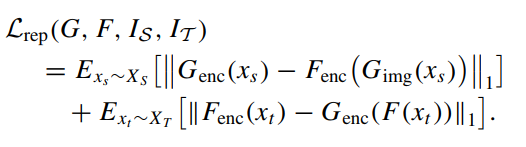
-
语义保留损失:不需要源域上的预训练模型
a. 确保翻译后的图像保持一致的语义内容
b. \(ℓ(·)\) 表示交叉熵损失函数
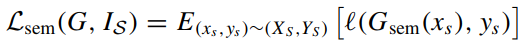
-
SPGAN 整体的损失函数:
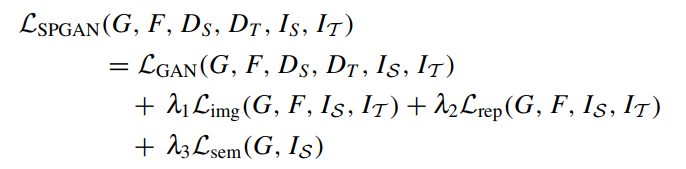
-
\(G_{enc}\) 负责编码图像,\(G_{dec}\) 负责解码图像,\(G_{seg}\) 是一个新引入的分支,用于进行语义分割,以便 \(G\) 能够以监督方式保留语义信息。通过这种方式在转换过程中保留了语义信息,从而有助于减轻转换图像的偏差,并对齐源域和目标域的光谱信息。
-
生成器 \(G\) :源域→目标域,生成器 \(F\) :目标域→源域。允许模型在两个方向上学习不同域之间的映射,确保语义信息在两个域中都得到保留并保持一致。
-
类别分布对齐(CDA)语义分割模块:
a. ClassMix:在转换后的图像中随机粘贴一半的类别,然后将相应的像素剪切下来粘贴到目标域的图像上。生成风格与目标域高度相似的混合图像,从而有效缩小翻译图像与目标图像之间的差距。
-
生成混合图像 \(x_{m}\)
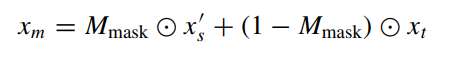
-
均值教师模型为 \(x_{m}\) 分配伪标签
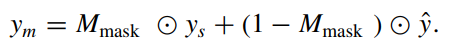
b. 利用转换后的图像 \(x_{s}'\) 和混合后的图像 \(x_{m}\) 来训练具有交叉熵损失的语义分割模型
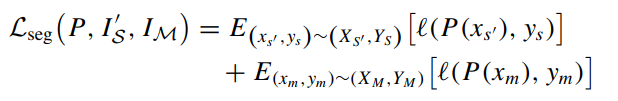
c. 边缘增强:通过ClassMix遮罩获得边界权重贴图遮罩,并保留离剪切粘贴边缘最近的四个像素。换句话说,只有距离小于4的像素才被考虑来计算边界权重。
-
混合后的图像的边缘增强损失:
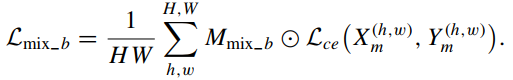
-
转换后的图像的边缘损失:γ是一个比例因子,用于平衡源域图像和混合图像对边界增强的贡献。
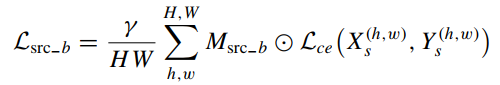
-
边缘增强模块的总体损失:
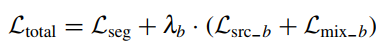
-
实验设置:
-
数据集
a. ISPRS 2D:Potsdam 和 Vaihingen 两个子集
b. LoveDA:城市和乡村
b. 3个跨域实验
-
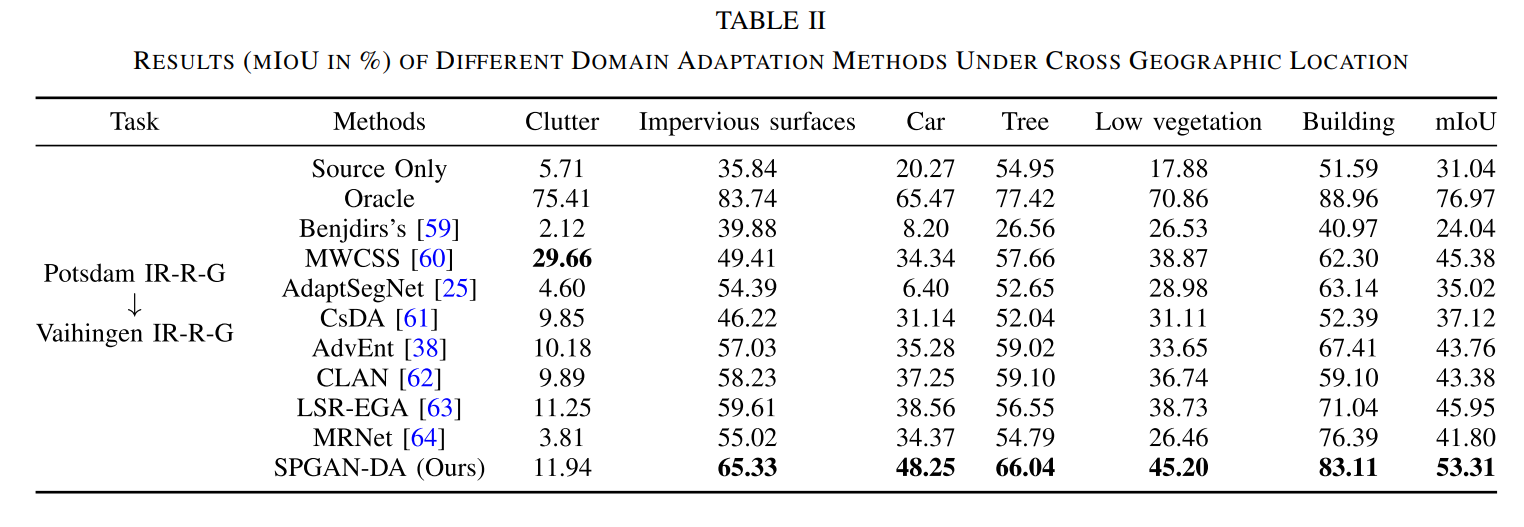
跨地理位置:Potsdam IR-R-G为源域,Vaihingen IRR-G为目标域
-
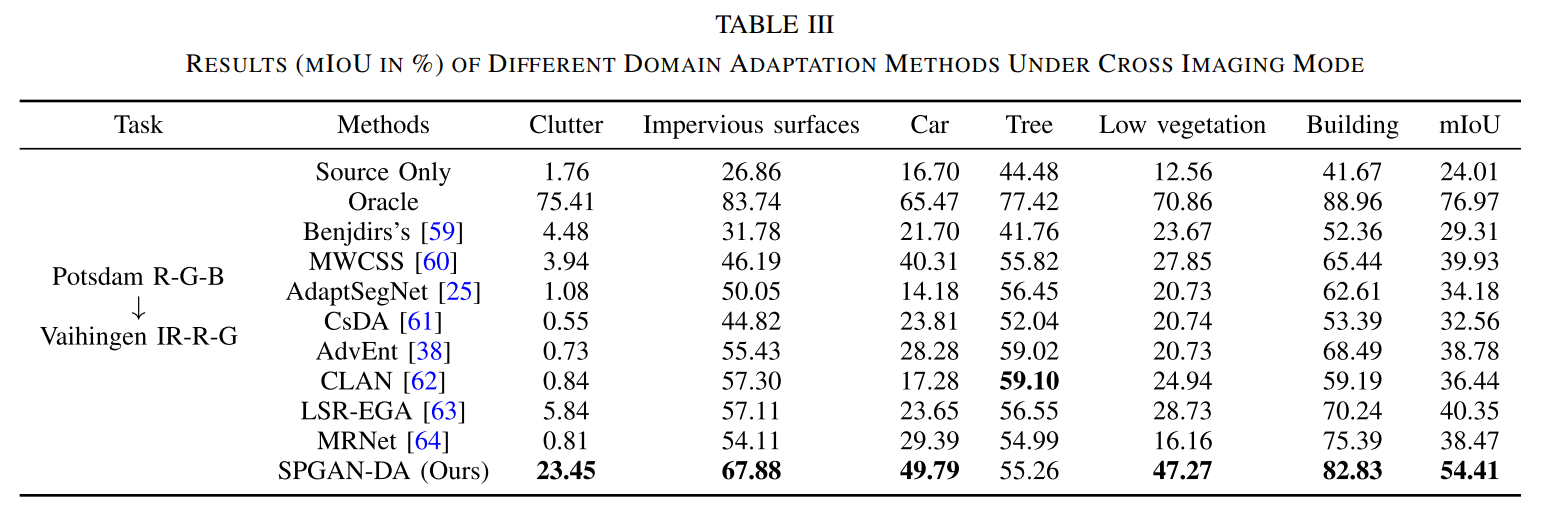
跨成像模式:Potsdam R-G-B为源域,Vaihingen IR-R-G为目标域
-
跨景观布局:LoveDA的Urban R-GB为源域,LoveDA的Rural R-G-B为目标域
-
-
实施细节
a. 生成器:8个卷积层,kernel_size = 4, stride = 2, out_channel ∈ {64, 128, 256, 512, 512, 512, 512, 512},镜像的卷积之间还有跳跃连接组成U形结构。(没图没源码)
b. 判别器:5个卷积层,kernel_size = 4, out_channel ∈ {64, 128, 256, 512, 1}
c. GAN的优化器:RMSProp
d. 分割模型:DeepLab-v2
e. 主干网络:ResNet-101
f. 分割模型的优化器:SGD
-
评价指标:FID,IoU
-
优越性评估
a. SPGAN图像转换质量
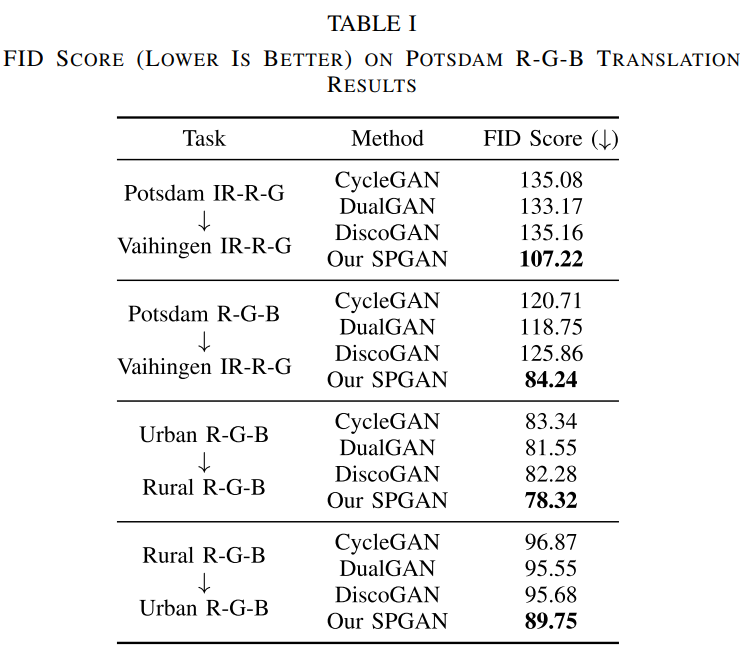
b. 对比实验
跨地理位置
跨成像模式
跨景观布局

-
消融实验:只有源域(SO)作为基准,对抗性损失和图像一致性损失(AL + ICL),表征不变损失(RIL),语义保留损失(SPL),边缘增强损失(BEL)
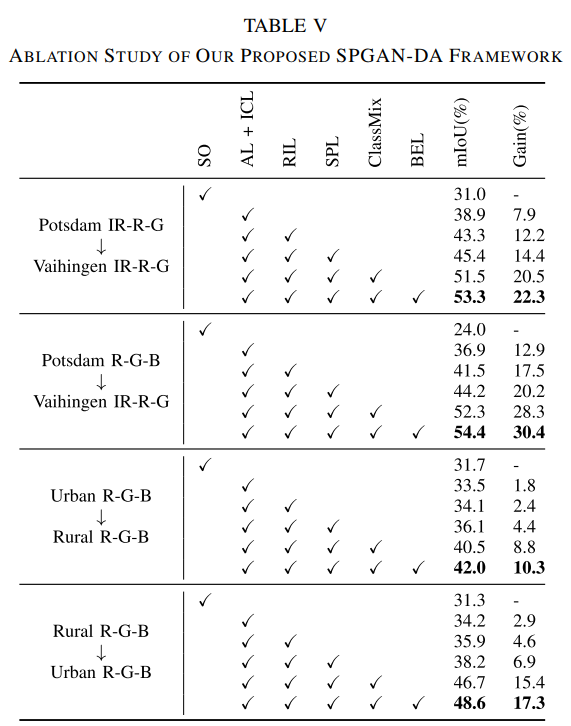
-
边缘权重的敏感性(超参数)分析:\(\lambda_{b}\) 指导网络对边界的关注程度

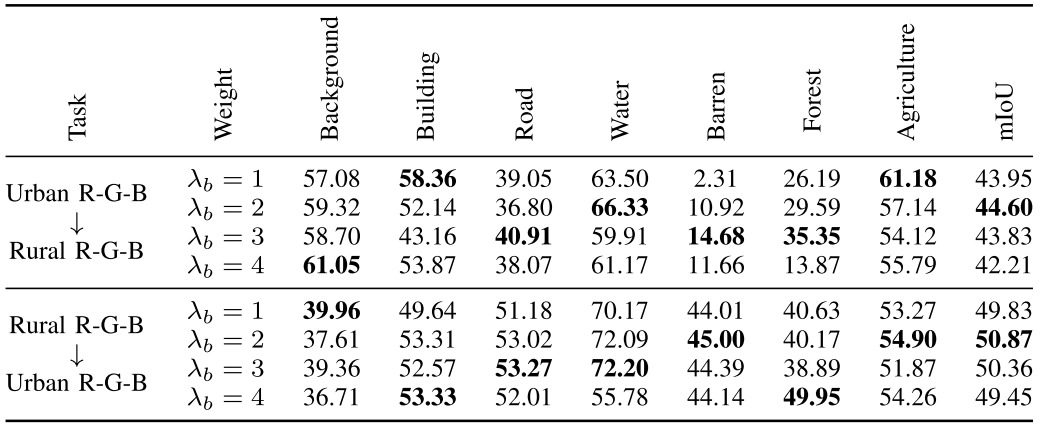
-
可视化特征分布:通过t-分布随机邻域嵌入得到二维特征图
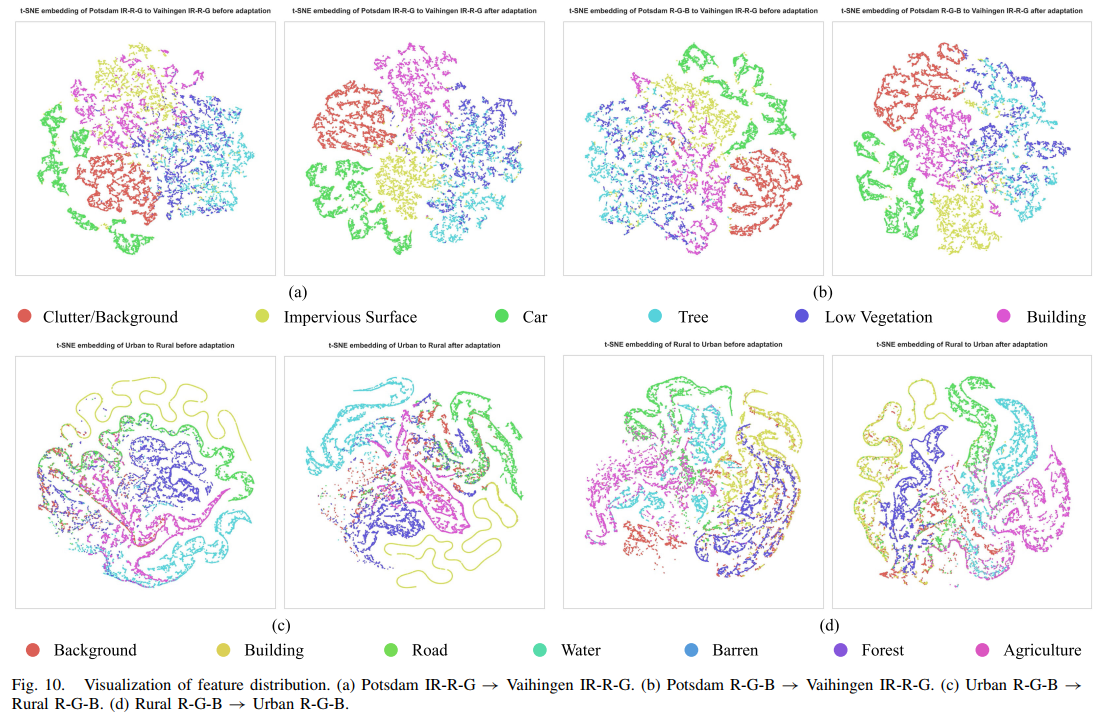
-
分割方法对比
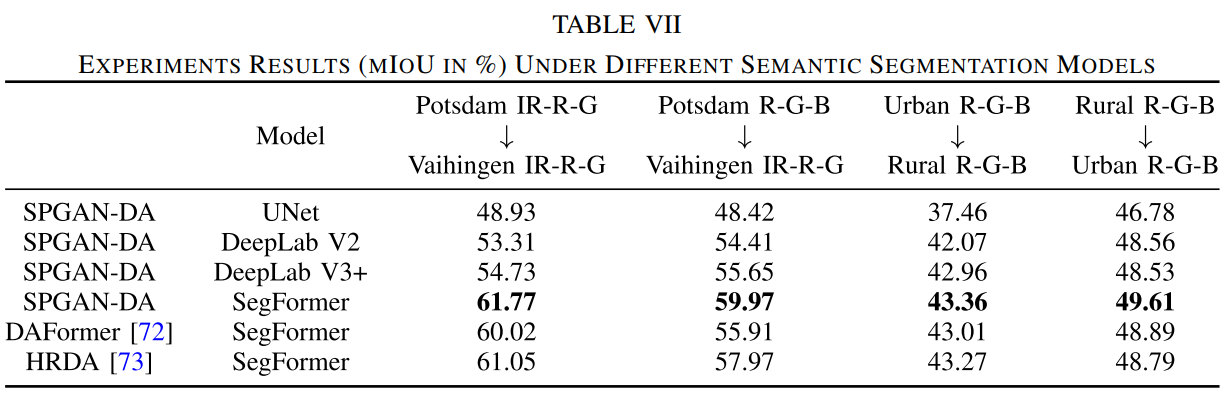
源码链接:
无
补充知识:
-
生成对抗网络的训练过程是一个博弈过程,生成器和判别器相互竞争,相互提升,直到达到一种动态平衡。生成器努力生成更逼真的样本,而判别器努力提高自己的辨别能力。
-
在 SPGAN-DA 框架中,x 代表输入数据点,而 X 代表输入数据点的整个域。在概率论和统计学中,锥形符号 (~) 表示 "从......抽取 "或 "从......采样"。例如,\(E_{x\sim X}\) 表示对整个领域 X 的期望值,其中 x 是从 X 中采样的。
-
FID(Fréchet Inception Distance)是一种用于评估生成模型生成图像质量的指标。它是由Martin Heusel等人于2017年提出的。FID Score基于两个图像分布之间的Fréchet距离,该距离在统计学中用于度量两个分布的相似性。