一、作业内容
- 作业①:
- 要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
- 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
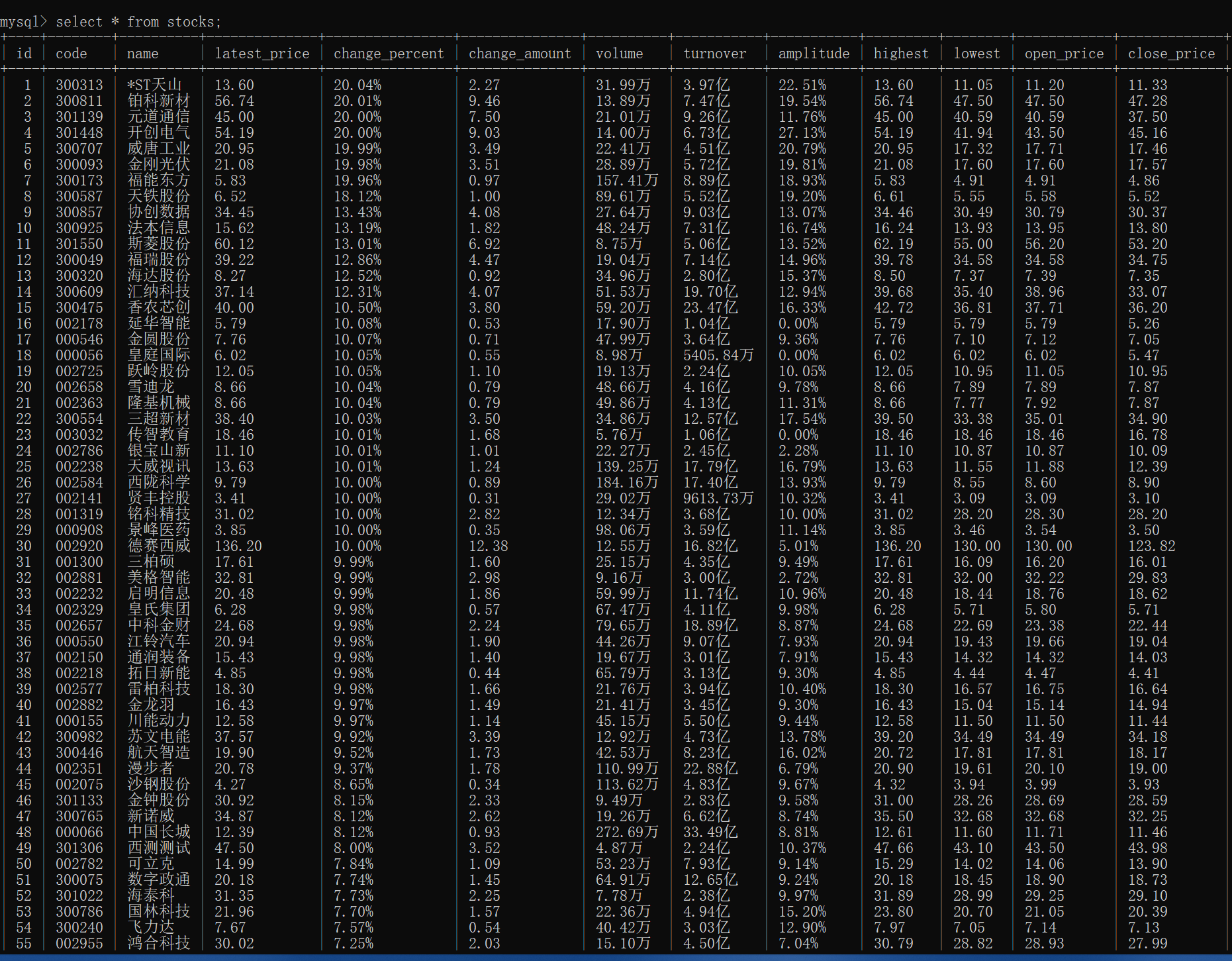
- 输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
- Gitee文件夹链接
|
序号 |
股票代码 |
股票名称 |
最新报价 |
涨跌幅 |
涨跌额 |
成交量 |
成交额 |
振幅 |
最高 |
最低 |
今开 |
昨收 |
|
1 |
688093 |
N世华 |
28.47 |
62.22% |
10.92 |
26.13万 |
7.6亿 |
22.34 |
32.0 |
28.08 |
30.2 |
17.55 |
|
2...... |
代码如下:
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains import time import pymysql # 连接自己的数据库,根据自己情况修改 conn = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd='yy2039070', charset='utf8',db='a1') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 必须先删除原有数据 cursor.execute("delete from stocks") # 创建一个表来存储股票信息 cursor.execute('''CREATE TABLE IF NOT EXISTS stocks (id INTEGER PRIMARY KEY, code TEXT, name TEXT, latest_price TEXT, change_percent TEXT, change_amount TEXT, volume TEXT, turnover TEXT, amplitude TEXT, highest TEXT, lowest TEXT, open_price TEXT, close_price TEXT)''') driver = webdriver.Chrome() print("请输入需要查找的股票,沪深京:1,上证:2,深证:3") while True: num = input("请输入:") if num == '1': # 沪深京A股 driver.get("https://quote.eastmoney.com/center/gridlist.html#hs_a_board") break elif num == '2': #上证A股 driver.get("https://quote.eastmoney.com/center/gridlist.html#sh_a_board") break elif num == '3': # 深证A股 driver.get("https://quote.eastmoney.com/center/gridlist.html#sz_a_board") break n = input("请输入需要查找的页码:") n = int(n) # 爬取前n页股票信息 for page in range(1, n+1): #爬取n页 print(f"正在爬取第 {page} 页股票信息") # 定位所有股票信息的元素 stocks_list = driver.find_elements(By.XPATH,"//div[@class='listview full']//tbody//tr") # 打印股票信息 for stock in stocks_list: stock_id = stock.find_element(By.XPATH,'.//td[1]').text stock_code = stock.find_element(By.XPATH,'.//td[2]/a').text stock_name= stock.find_element(By.XPATH,'.//td[3]/a').text stock_latest_price= stock.find_element(By.XPATH,'.//td[5]//span').text stock_change_percent= stock.find_element(By.XPATH,'.//td[6]//span').text stock_change_amount= stock.find_element(By.XPATH,'.//td[7]//span').text stock_volume= stock.find_element(By.XPATH,'.//td[8]').text stock_turnover= stock.find_element(By.XPATH,'.//td[9]').text stock_amplitude= stock.find_element(By.XPATH,'.//td[10]').text stock_highest= stock.find_element(By.XPATH,'.//td[11]//span').text stock_lowest= stock.find_element(By.XPATH,'.//td[12]//span').text stock_open_price= stock.find_element(By.XPATH,'.//td[13]//span').text stock_close_price= stock.find_element(By.XPATH,'.//td[14]').text print(f"序号: {stock_id}") print(f"股票代码: {stock_code}") print(f"股票名称: {stock_name}") print(f"最新报价: {stock_latest_price}") print(f"涨跌幅: {stock_change_percent}") print(f"涨跌额: {stock_change_amount}") print(f"成交量: {stock_volume}") print(f"成交额: {stock_turnover}") print(f"振幅: {stock_amplitude}") print(f"最高: {stock_highest}") print(f"最低: {stock_lowest}") print(f"今开: {stock_open_price}") print(f"昨收: {stock_close_price}") print("-" * 60) sql ="INSERT INTO stocks (id,code, name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, close_price) VALUES (%s, %s,%s, %s, %s,%s, %s, %s, %s, %s, %s, %s, %s)" cursor.execute(sql,[stock_id,stock_code, stock_name, stock_latest_price, stock_change_percent, stock_change_amount, stock_volume, stock_turnover, stock_amplitude, stock_highest, stock_lowest, stock_open_price, stock_close_price]) conn.commit() print("数据已存入数据库") # 点击下一页按钮 next_page_button = driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]') action = ActionChains(driver) time.sleep(5) action.move_to_element(next_page_button).perform() next_page_button.click() time.sleep(5) conn.close() # 关闭浏览器 driver.quit()
为了方便演示,选择以(1,1),(2,2),(3,3)方式输入:
(1,1):
输入及部分终端输出如下:
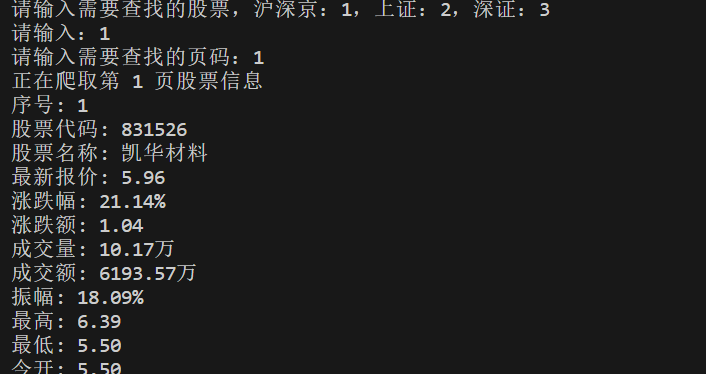
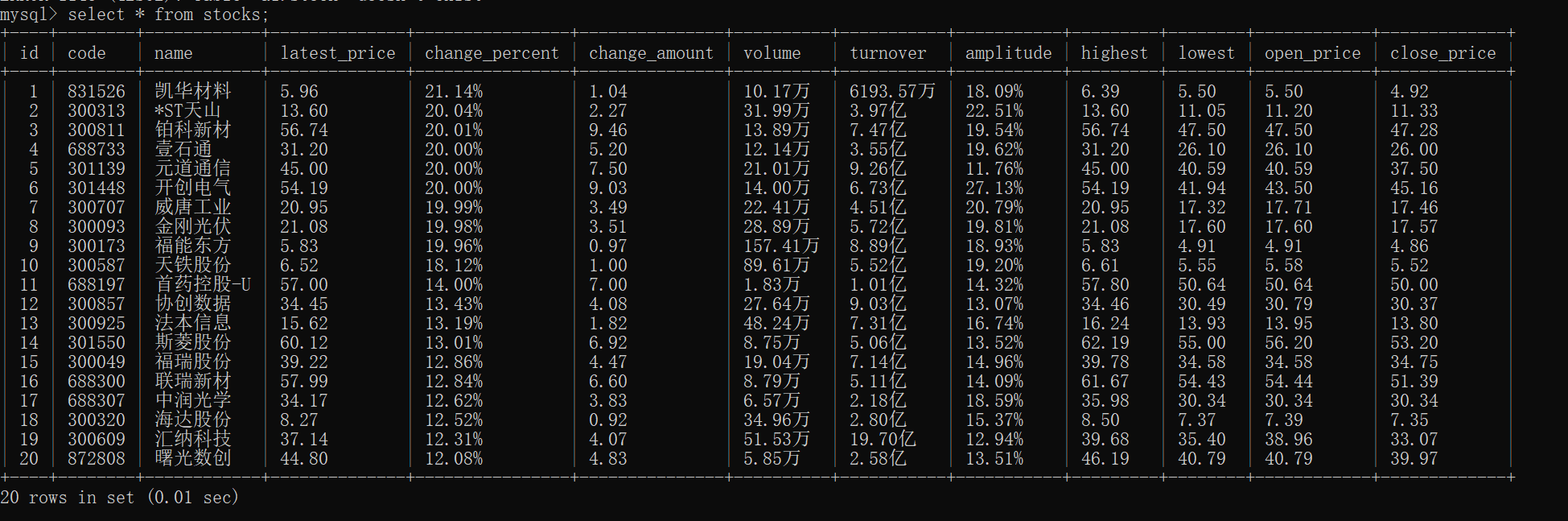
数据库输出如下:
(2,2):
部分终端输出如下:
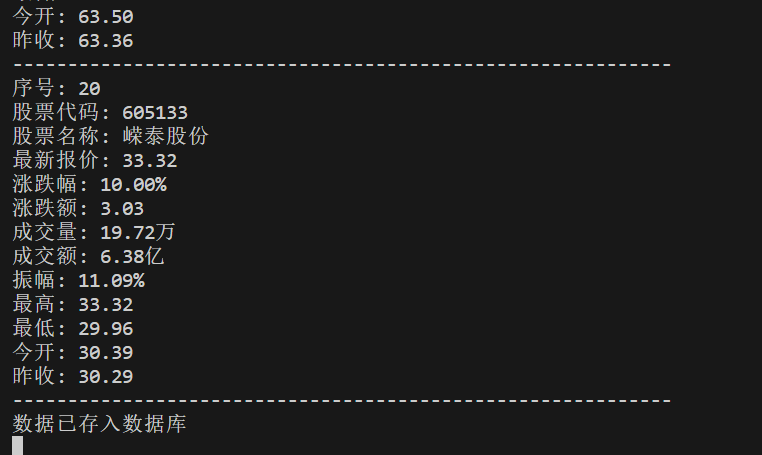
数据库输出如下:

(3,3):
部分终端输出:
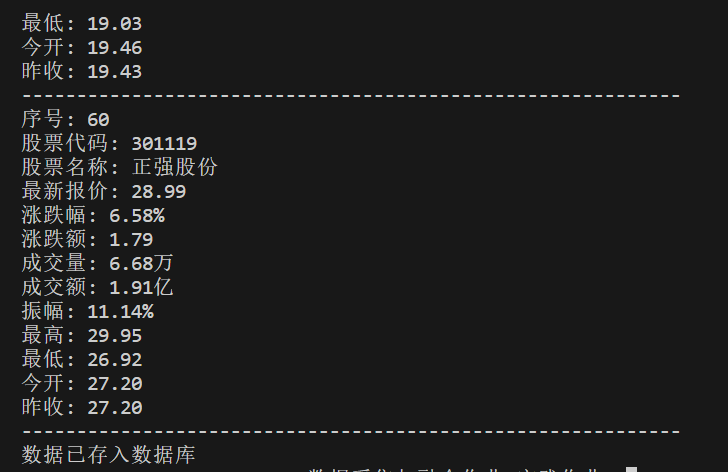
数据库输出:
心得体会:这个作业还是比较轻松的,帮我回忆了一下selenium的命令,只需要稍加修改代码即可完成。再就是必须先删除原有数据,否则会报错,也不知道为什么
- 作业②:
- 要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
- 候选网站:中国mooc网:https://www.icourse163.org
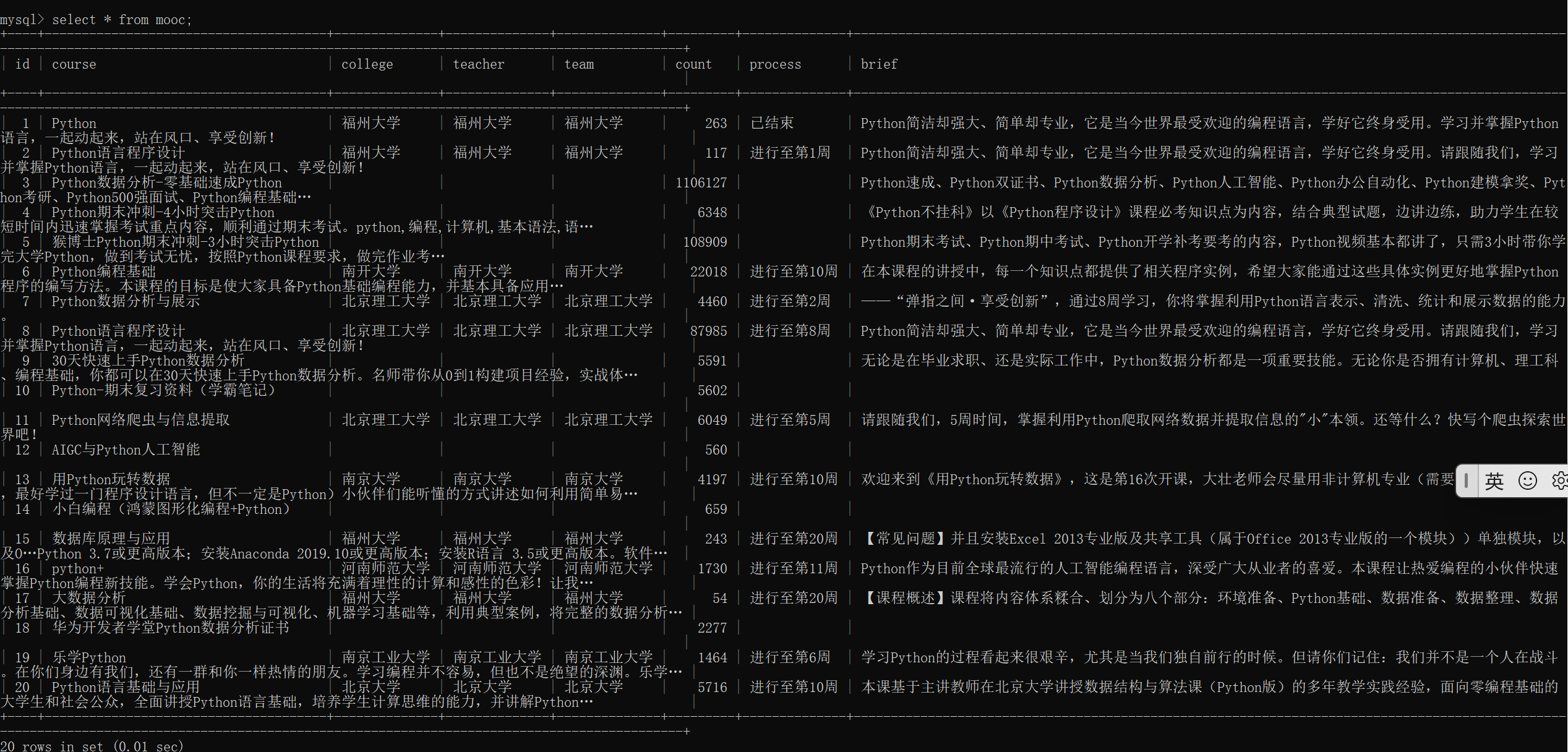
- 输出信息:MYSQL数据库存储和输出格式
- Gitee文件夹链接
|
Id |
cCourse |
cCollege |
cTeacher |
cTeam |
cCount |
cProcess |
cBrief |
|
1 |
Python数据分析与展示 |
北京理工大学 |
嵩天 |
嵩天 |
470 |
2020年11月17日 ~ 2020年12月29日 |
“我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” …… |
|
2...... |
- 代码如下:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.keys import Keys import time import random import pymysql from selenium.common.exceptions import NoSuchElementException conn = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd='yy2039070', charset='utf8',db='a1') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) cursor.execute("delete from mooc") cursor.execute('''CREATE TABLE IF NOT EXISTS mooc ( id INTEGER PRIMARY KEY, course TEXT, college TEXT, teacher TEXT, team TEXT, count INTEGER, process TEXT, brief TEXT)''') driver = webdriver.Chrome() #最大化浏览器 driver.maximize_window() driver.get("https://www.icourse163.org/") time.sleep(3) #点击登录按钮 login_button = driver.find_element(By.XPATH,'//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div') login_button.click() time.sleep(3) #反爬 driver.switch_to.default_content() driver.switch_to.frame(driver.find_elements(By.TAG_NAME,'iframe')[0]) time.sleep(2) #输入用户名 username=driver.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input') username.clear() username.send_keys("18950090367") time.sleep(2) #输入密码 password=driver.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]') password.send_keys("Yy2039070@") time.sleep(2) login=driver.find_element(By.ID,"submitBtn") login.click() time.sleep(2) driver.switch_to.default_content() time.sleep(5) #搜索框 search_box = driver.find_element(By.XPATH,'/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input') search_box.send_keys("python", Keys.RETURN) # 声明一个list,存储dict data_list = [] def start_spider(): WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="m-course-list"]/div/div'))) # 将滚动条拉到最下面的位置,因为往下拉才能将这一页的商品信息全部加载出来 driver.execute_script('document.documentElement.scrollTop=10000') # 随机延迟,等下元素全部刷新 time.sleep(random.randint(3, 6)) driver.execute_script('document.documentElement.scrollTop=0') # 开始提取信息,找到ul标签下的全部li标签 num = 0 for link in driver.find_elements(By.XPATH, '//div[@class="m-course-list"]/div/div'): num += 1 course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text try: school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text except NoSuchElementException: school_name = '' try: teacher = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text except NoSuchElementException: teacher = '' try: team_member = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text except NoSuchElementException: team_member = '' try: count = link.find_element(By.XPATH, './/span[@class="hot"]').text.replace('人参加', '') except NoSuchElementException: count = '' try: process = link.find_element(By.XPATH, './/span[@class="txt"]').text except NoSuchElementException: process = '' try: introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text except NoSuchElementException: introduction = '' try: cursor.execute("INSERT INTO mooc (id, course,college,teacher,team,count,process,brief) VALUES (%s, %s,%s, %s, %s, %s, %s, %s)", [num, str(course_name), str(school_name), str(teacher), str(team_member), str(count), str(process), str(introduction)]) except Exception as err: print("出现错误:", err) conn.commit() print("数据已存入数据库") def main(): start_spider() if __name__ == '__main__': main() # 退出浏览器 driver.quit() conn.close()
数据库输出:
心得体会:
这次作业难度提高了一些,不过还是可以完成的,其中count的数据如果有中文就会报错,只能用replace替换掉,其他的再操作中没遇到什么困难。
- 作业③:
- 要求:
- 掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
- 环境搭建:
- 任务一:开通MapReduce服务
- 实时分析开发实战:

-

-
- 任务二:配置Kafka
-

- 任务三: 安装Flume客户端
-
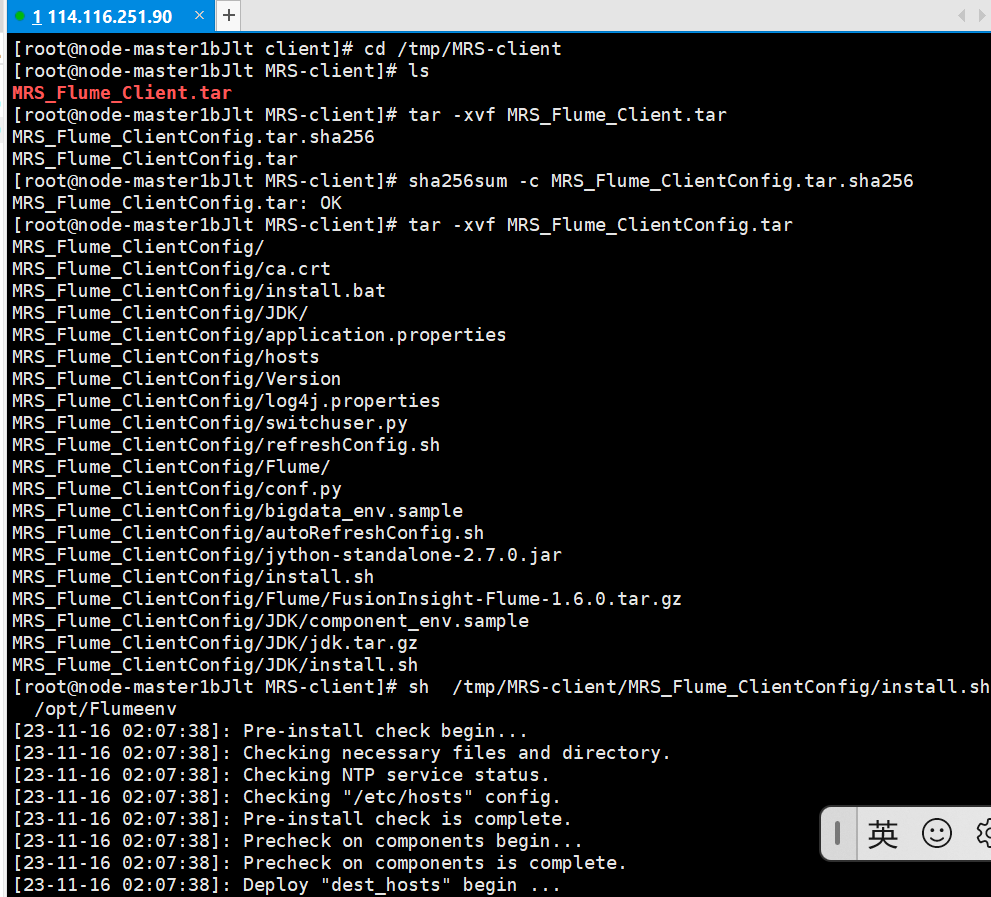
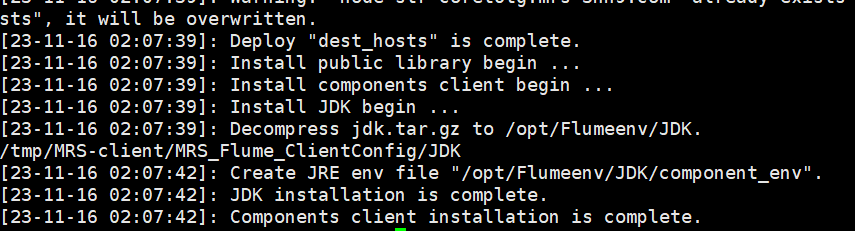
-
解压Flume客户端

-
安装Flume客户端成功

- 任务四:配置Flume采集数据


可以看到数据已经发生变化
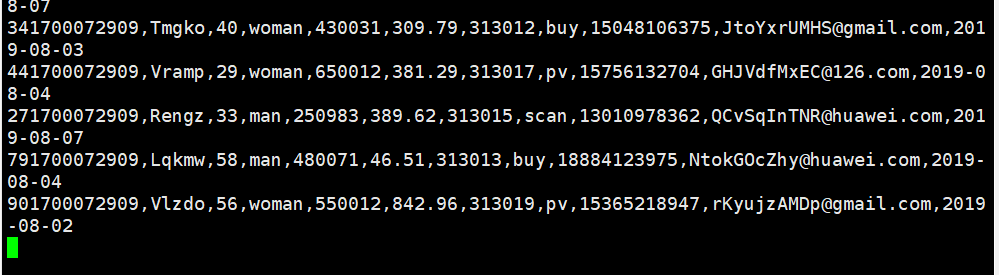
输出:实验关键步骤或结果截图。
二、编码要求
- 本作业采用python作为编程语言
- 符合python编程和命名规范
- 对相关函数变量作出相应的注释
三、博客撰写要求
- 博客分为俩大标题,每个标题中分为俩个小标题
- 第一个小标题中内容包含作业代码和图片,第二个小标题中内容为作业心得
- 博客园中代码需要按代码块的形式添加
- 推荐使用markdown语法进行博客撰写,也可以使用博客园自带文档编辑器
- 可适当对标题内容进行拓展
四、作业评分项和规则