在前面已经学习了:
What we have learned
▪ create tensor
▪ indexing and slices
▪ reshape and broadcasting
▪ math operations
现在用tensorFlow做一个前向传播的一个小实战:

1.加载数据
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
#加载数据集
#x:[60k,28,28]
#y:[60k]
(x, y), _ =datasets.mnist.load_data()
x = tf.convert_to_tensor(x,dtype=tf.float32) / 255
y = tf.convert_to_tensor(y,dtype=tf.int32)
print(x.shape, y.shape, x.dtype, y.dtype)
print(tf.reduce_min(x), tf.reduce_max(x))
print(tf.reduce_min(y), tf.reduce_max(y))
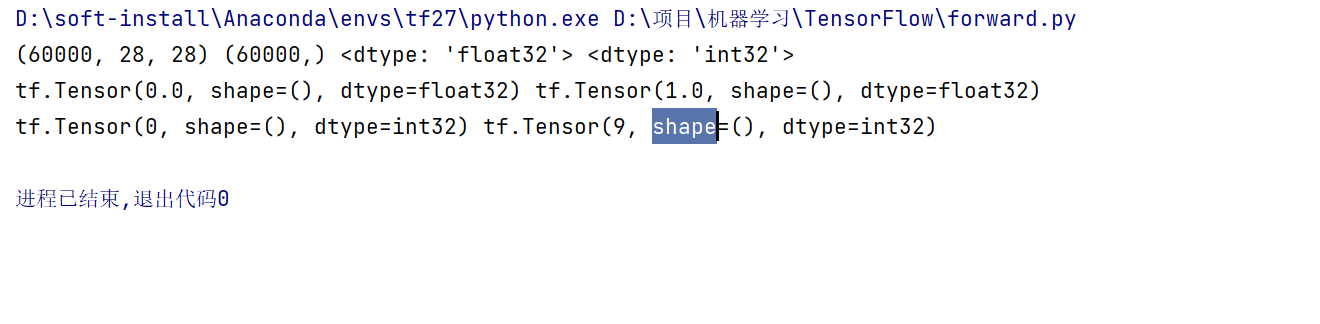
我们会发现这个x最小是0,最大是255,但是我们除了255,所以是[0-1],y是[0-9]
定义相关参数
# [b, 784] => [b, 256] => [b, 128] => [b, 10]
# [dim_in, dim_out], [dim_out]
#这里要定义成Variable ,因为后面求偏导数的时候要跟踪他的梯度
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
这里要注意,w1,w2,w3,b1,b2,b3要定义成Variable类型,因为后面求偏导数的时候要跟踪他的梯度
梯度下降
lr = 1e-3
losses = []
for epoch in range(20): # iterate db for 10,也就是多迭代几次
for step, (x, y) in enumerate(train_db): # for every batch
# x:[128, 28, 28]
# y: [128]
# [b, 28, 28] => [b, 28*28]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape: # tf.Variable
# x: [b, 28*28]
# h1 = x@w1 + b1
# [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b, 256] + [b, 256]
h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256])
h1 = tf.nn.relu(h1)
# [b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# [b, 128] => [b, 10]
out = h2@w3 + b3
# compute loss
# out: [b, 10]
# y: [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# mse = mean(sum(y-out)^2)
# [b, 10]
loss = tf.square(y_onehot - out)
# mean: scalar
loss = tf.reduce_mean(loss)
# compute gradients
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# print(grads)
# w1 = w1 - lr * w1_grad
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
if step % 100 == 0:
print(epoch, step, 'loss:', float(loss))
losses.append(float(loss))
这里要注意的是w1.assign_sub(),是为了保证w1还是Variable类型,进行相减