leecode里面的第一题,是两数值和,内容如下
/**************************************************************
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
**************************************************************/
最简单的方法就是暴力枚举,直接将所有的元素全都遍历一遍。如下

该方法没有增加额外的存储空间,使用的内存相较于后面的方法要少,但是时间复杂度为O(N2)
后续leecode提出了疑问说能否提高算法的效率,是时间复杂度优于O(N2)
对应的解法使用哈希算法,理论来讲也比较简单,就是用 目标值=target-当前值
将所有的数组值进行哈希存储,然后将目标值与哈希存储的值进行比较,能够找到就是对应的结果

该方法的内存使用相较于第一种算法是有所增加的,但是整体时间复杂度下降为O(N),其实还是以空间换时间的做法。
知识延伸:
C++ unordered_map
C++ STL 标准库中,不仅是 unordered_map 容器,所有无序容器的底层实现都采用的是哈希表存储结构。更准确地说,是用“链地址法”(又称“开链法”)解决数据存储位置发生冲突的哈希表,整个存储结构如图所示。
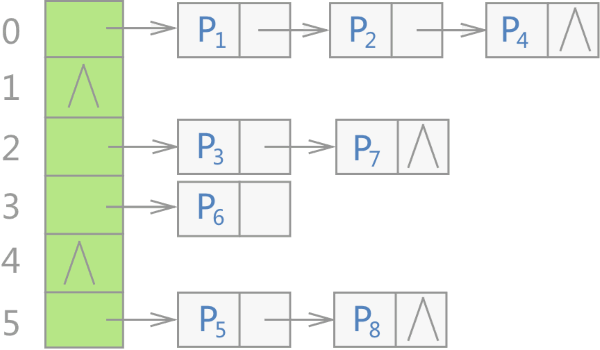
其中,Pi 表示存储的各个键值对。
可以看到,当使用无序容器存储键值对时,会先申请一整块连续的存储空间,但此空间并不用来直接存储键值对,而是存储各个链表的头指针,各键值对真正的存储位置是各个链表的节点。
注意,STL 标准库通常选用 vector 容器存储各个链表的头指针。
不仅如此,在 C++ STL 标准库中,将图 1 中的各个链表称为桶(bucket),每个桶都有自己的编号(从 0 开始)。当有新键值对存储到无序容器中时,整个存储过程分为如下几步:
将该键值对中键的值带入设计好的哈希函数,会得到一个哈希值(一个整数,用 H 表示);
将 H 和无序容器拥有桶的数量 n 做整除运算(即 H % n),该结果即表示应将此键值对存储到的桶的编号;
建立一个新节点存储此键值对,同时将该节点链接到相应编号的桶上。
另外值得一提的是,哈希表存储结构还有一个重要的属性,称为负载因子(load factor)。该属性同样适用于无序容器,用于衡量容器存储键值对的空/满程序,即负载因子越大,意味着容器越满,即各链表中挂载着越多的键值对,这无疑会降低容器查找目标键值对的效率;反之,负载因子越小,容器肯定越空,但并不一定各个链表中挂载的键值对就越少。
举个例子,如果设计的哈希函数不合理,使得各个键值对的键带入该函数得到的哈希值始终相同(所有键值对始终存储在同一链表上)。这种情况下,即便增加桶数是的负载因子减小,该容器的查找效率依旧很差。
无序容器中,负载因子的计算方法为:
负载因子 = 容器存储的总键值对 / 桶数
默认情况下,无序容器的最大负载因子为 1.0。如果操作无序容器过程中,使得最大复杂因子超过了默认值,则容器会自动增加桶数,并重新进行哈希,以此来减小负载因子的值。需要注意的是,此过程会导致容器迭代器失效,但指向单个键值对的引用或者指针仍然有效。
这也就解释了,为什么我们在操作无序容器过程中,键值对的存储顺序有时会“莫名”的发生变动。
参考:https://c.biancheng.net/view/7235.html
- unordered_map unordered 数字 mapunordered_map unordered数字map unordered_map unordered_map unordered map unordered unordered_set unordered_map set unordered_map unordered hack map tuples unordered_map map unordered unordered unordered_map unordered_set map map hash_map hash unordered_map 查询表unordered_map unordered性能 unorder_map