pytorch
环境搭建
课程给你的环境当中, 可以直接用pytorch, 当时其默认是没有给你安装显卡支持的. 如果你只用CPU来操作, 那其实没什么问题, 但我的电脑有N卡, 就不能调用.
考虑到我已有pytorch环境(大致方法就是确认pytorch版本和对应的cuda版本安装cuda,再按照官网即可,建议自己搜索), 所以需要安装jupyter. 但是默认情况下如果一个个安装比如这样
pip install jupyter==1.0.0
pip install ipython==7.4.0pip会默认给你安装依赖导致版本异常. 所以我还是在原本的requirements.txt做了裁剪pip安装,实现了自己的pytorch环境的工作.

加载数据
pytorch可以帮我们获取数据集.这是我以前笔记的内容:
import torch
from torch.utils.data import DataLoader
import torchvision
testSet = torchvision.datasets.CIFAR10(root="./train",train=False,transform=torchvision.transforms.ToTensor(),download=True)
mydataloader = DataLoader(testSet, batch_size=16,shuffle=True)作业的区别大抵就是: dataloader的batch_size不大一样, 随后Transform也多了一层.
transform = T.Compose([
T.ToTensor(),
T.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])这就是图像预处理,我们曾经的图像一直是减去了平均灰度图像, 而现在被直接写死了, 并额外做了个标准化.
低抽象度的实现
我们在B站搜到的教程大多数都是直接调用API搭建神经网络, 被封装的很好. 但我们应当如同之前那样, 从操作矩阵开始. 不过尽管如此, 也会比之前略简单, 因为只要我们开启了选项x.requires_grad == True, pytorch就能够帮我们完成梯度的记录, 后续只需要简单的代码就可以完成梯度下降了.
pytorch的矩阵被称为(更准确说是被封装为)张量(tensor), 其实就是换了个名字, 你可以理解区别就是它可以被放在GPU运算. 首先是flatten函数.
import torch # 核心module
def flatten(x):
N = x.shape[0] # read in N, C, H, W
return x.view(N, -1) # "flatten" the C * H * W values into a single vector per image
def test_flatten():
x = torch.arange(12).view(2, 1, 3, 2)
print('Before flattening: ', x)
print('After flattening: ', flatten(x))这个操作和numpy几乎是一摸一样,此外Numpy的很多其他操作也都支持. 但是视图的意义在于, x.view本质上和x指代的是同一个数组, 只是呈现形式不同, 如果我们把x.view赋给了其他元素(比如xv = x.view), 那么x元素修改,xv会同步修改. 然而奇妙的是, 我们对xv可以当作是一个真正reshape后的矩阵来使用,这也方便了全连接层.
import torch.nn.functional as F # 要用到函数就要做这个
dtype = torch.float32 # 单精度. 不用双精度原因是节约计算量, 且专业卡以外的geforce N卡普遍大幅削弱了双精度算力
def two_layer_fc(x, params):
x = flatten(x) # 展平成N个向量
w1, w2 = params
x = F.relu(x.mm(w1)) # mm矩阵乘法,relu函数
x = x.mm(w2) # mm乘法
return x
def two_layer_fc_test():
hidden_layer_size = 42
x = torch.zeros((64, 50), dtype=dtype) # 生成矩阵,语法和numpy一致
w1 = torch.zeros((50, hidden_layer_size), dtype=dtype)
w2 = torch.zeros((hidden_layer_size, 10), dtype=dtype)
scores = two_layer_fc(x, [w1, w2])
print(scores.size())
two_layer_fc_test()与之类似, 我们通过内置的函数实现卷积网络推演 (请注意: 这里要求是conv=>relu=>conv=>relu=>fc)
out1 = F.conv2d(x, conv_w1, bias=conv_b1, stride=1, padding=(2,2)) # 注意参数
relu1 = F.relu(out1)
out2 = F.conv2d(relu1, conv_w2, bias=conv_b2, stride=1, padding=(1,1))
relu2 = F.relu(out2)
scores = torch.mm(flatten(relu2), fc_w) + fc_b权重的初始化
之前我们都是直接用weight scale超参数. 但是我们需要一个经验的初始值, 也就是所谓的"Kaiming normalization":
如果权重为二阶矩阵(FC), 则令n=矩阵的shape[0]
如果权重为>三阶矩阵(CNN..), 则令n=shape[1]之后所有shaape相乘
随后令W ~ N(0,√(2/N))当然, 不同的激活函数对应的初始化也不一样, 比如说这个就是针对relu的. 而假若我们用的是tanh这样的激活函数, 则使用xaiver初始化.
验证准确性
包括在后面高度抽象化的使用中, 我们是不希望pytorch计算梯度的. 所以加上了no_grad手动要求不计算梯度.
def check_accuracy_part2(loader, model_fn, params):
num_correct, num_samples = 0, 0
with torch.no_grad():
for x, y in loader: # x是图像,y是label
x = x.to(device=device, dtype=dtype) # x.to表示将这个tensoy移动到某个设备中演算
y = y.to(device=device, dtype=torch.int64) # 转化成int, 因为结果只可能是整数,防止精度损失导致判断异常
scores = model_fn(x, params)
_, preds = scores.max(1) # #取最大值
num_correct += (preds == y).sum() # 计算准确度
num_samples += preds.size(0)
acc = float(num_correct) / num_samples
print('Got %d / %d correct (%.2f%%)' % (num_correct, num_samples, 100 * acc))而在手动计算梯度的时候, 我们先通过自带的函数计算梯度, 随后反演的时候不允许梯度计算.
for t, (x, y) in enumerate(loader_train):
x = x.to(device=device, dtype=dtype)
y = y.to(device=device, dtype=torch.long)
scores = model_fn(x, params) # 推演
loss = F.cross_entropy(scores, y) # 计算误差,softmax
loss.backward() # 计算梯度
with torch.no_grad():
for w in params:
w -= learning_rate * w.grad # 调用w.grad得到梯度值
w.grad.zero_() # 令梯度为0,避免影响下一次计算训练网络
因为前面很多地方已经封装好了, 我们要做i的就是根据备注初始化参数即可. 按照指示, 得到了大约47%的准确度.
conv_w1 = random_weight((32,3,5,5))
conv_b1 = zero_weight((32,))
conv_w2 = random_weight((16,32,3,3))
conv_b2 = zero_weight((16,))
fc_w = random_weight((16 * 32 * 32,10))
fc_b = zero_weight(10)更抽象 - 继承网络基类
从这开始, 如果你入门过pytorch, 就会开始熟悉起来了. 在更抽象的过程中, 我们不需要手动去操作张量. 我们定义网络的内, 其中的成员就是网络的各层. 这个网络需要继承nn.Module这个网络基类. 其中有两个核心函数:
- 构造函数: 定义各个层
- forward函数: 层推演
从现在开始, 我们就是API caller了, 仅仅体验一番是绝对不可能记住的! pytorch是工具, 我们就要学会去查阅技术文档. torch.nn — PyTorch 1.8.0 documentation 我感觉pytorch的文档写的还是不错的, 很规范而整洁, 用好几乎能替代google了(
import torch.nn as nn # 这两个包是方便我们操作封装的
import torch.optim as optim
class TwoLayerFC(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super().__init__() # 务必初始化超类
self.fc1 = nn.Linear(input_size, hidden_size)
nn.init.kaiming_normal_(self.fc1.weight) # 对weight初始化
self.fc2 = nn.Linear(hidden_size, num_classes)
nn.init.kaiming_normal_(self.fc2.weight)
def forward(self, x):
x = flatten(x)
scores = self.fc2(F.relu(self.fc1(x))) # 直接用self.层(tensor)就能完成操作
return scores下面是卷积网络:
def __init__(self, in_channel, channel_1, channel_2, num_classes):
super().__init__()
# 务必记住生成图像尺寸的公式
# H' = 1 + (H + 2 * pad - HH) / stride
# W' = 1 + (W + 2 * pad - WW) / stride
self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=channel_1,kernel_size=5,padding=2, bias=True)
nn.init.kaiming_normal_(self.conv1.weight)
nn.init.constant_(self.conv1.bias,0) # 设置权重的初始值为0
self.relu = F.relu
self.conv2 = nn.Conv2d(in_channels=channel_1,out_channels=channel_2,kernel_size=3,padding=1,bias=True)
nn.init.kaiming_normal_(self.conv2.weight)
nn.init.constant_(self.conv2.bias,0)
self.fc = nn.Linear(channel_2 * 32 * 32, num_classes)
def forward(self, x):
scores = None
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
scores = self.fc(flatten(x))
return scores下面的就没什么特别的了, 固定的步骤, 我做一下总结:
初始化(loss,optimizer等),设置GPU(model,loss,img,label) => 设置为训练模式 => 清零梯度 => model(x) => 计算梯度,反演 => 梯度下降
model = model.to(device=device) # move the model parameters to CPU/GPU
for e in range(epochs):
for t, (x, y) in enumerate(loader_train):
model.train() # put model to training mode
x = x.to(device=device, dtype=dtype)
y = y.to(device=device, dtype=torch.long)
scores = model(x)
loss = F.cross_entropy(scores, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % print_every == 0:
print('Iteration %d, loss = %.4f' % (t, loss.item()))
check_accuracy_part34(loader_val, model)
print()作业只要求我们完成初始化
model = ThreeLayerConvNet(3, channel_1, channel_2, 10)
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)在封装之后准确率达到了52%.
sequential
这个更加简单, 我们甚至不需要写一个类了, 只需要指定各个层是什么就可以了.
model = nn.Sequential(
Flatten(),
nn.Linear(3 * 32 * 32, hidden_layer_size),
nn.ReLU(),
nn.Linear(hidden_layer_size, 10),
)
optimizer = optim.SGD(model.parameters(), lr=learning_rate, # SGD可以指定动量作为升级版
momentum=0.9, nesterov=True)model = nn.Sequential(
nn.Conv2d(3,channel_1,kernel_size=5,padding=2),
nn.ReLU(),
nn.Conv2d(channel_1,channel_2,kernel_size=3,padding=1),
nn.ReLU(),
nn.Flatten(),
nn.Linear(channel_2*32*32,10)
)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate,
momentum=0.9, nesterov=True)有了改进的梯度下降方法帮助,准确率达到了58%.
开放式作业 - 设计神经网络 (CIFAR10炼丹记前编)
真理 ------

我当时看的那个教程就是采用了cifar作为目标. 在那个时候, 我参照了这样的网络模型

对应的代码如下:
model = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,stride=1,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,stride=1,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Flatten(),
torch.nn.Linear(1024,64),
torch.nn.Linear(64,10)
)很遗憾, 当时我仅仅做到了67%的准确度. (这个图里面是tensorboard)
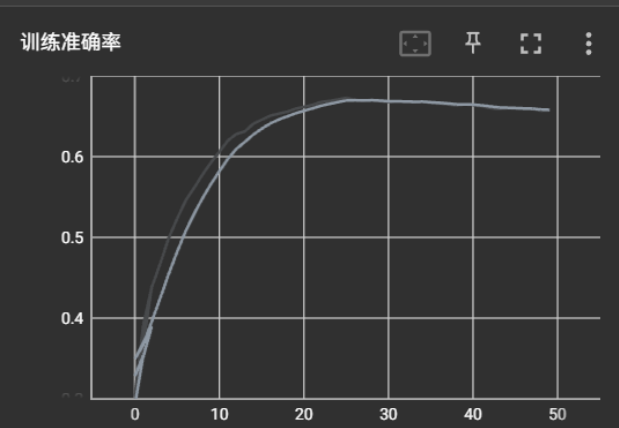
但是其他博客各路大佬做到了76%. 我就开始思考, 究竟问题在何处?
首先我先单纯把我之前的代码转移到这个作业上, 确认按照作业的参数统一标准. 得到准确度为66.96%, 果真如此.
我发现了那时试验的最大硬伤: 没有激活函数,且下降方式是SGD. 所以我加上了ReLU, 同时更换下降为adam, lr=1e-3. 这样准确度提升到了71.8%. 值得注意的是, 我在pycharm自己的代码试验只能跑到70%左右,可能是自己跑的epoch不够多,毕竟loss波动不等于没有下降趋势.
随后参照博客(3条消息) cs231n assignment2 PyTorch_一叶知秋Autumn的博客-CSDN博客 , 将输出通道数3=>32=>64=>128(原本是3=>32=>32=>64), 进一步提升到73.1%. 再增加无法看到任何效果.
我们还没用到batch normalize和dropout, 纠结了这么久没想到用课程之前学的确实还是有点失败的. 我在每层conv/relu间加入了正则化, 并在全连接层中间加入了0.5的dropout. 嗯,很好, 我们将准确度又拉高了2.9%. 这一步可能是我所有操作中最有效的了. 在此基础上加上l2正则化(我的reg=0.01)之后效果会急剧下降, 因为已经有了dropout防止过拟合, 二者作用互补, 有时不应当一起使用.
随后疯狂对着上面的网络调参, 包括将卷积核大小从5=>3(+1.8%,原因不知), 使用leakyrelu(无用), 增大全连接层隐含层并在全连接层内补上relu(没用). 准确度达到78%.
考虑我的显卡还不错, 所以增大了batch_size(=>256)和增大了epoch数量(50), 期望在时间相近下取得较好效果. 具体实验参照了这个博客如何用Keras从头开始训练一个在CIFAR10上准确率达到89%的模型 - 知乎 (zhihu.com) 当然这就有点不讲武德了, 纯粹就是试试看时间拉长后的效果如何. 准确度达到79.6%. 预计如果训练足够长时间, 准确度能够达到80%-81%.

但是结合别人的结果, 这也让我感觉, 或许再怎么调参上限就是如此了. 所以留给我们的就是几个方向: 数据增强/改变训练方式, 更高阶的调节手段, 更换网络架构.
上面的实验算是将之前课程的全部内容过了一遍. 我后面会专门写一个博客记录一下, 因为我自知这个是需要系统学习的, 看看学了assignment3之后会不会有新知. 不说了,要准备期中考试了(