1、神经元
神经元是神经网络中的基本单元。
每一个神经元包括两个参数:权重系数和偏置系数b。
神经网络的学习过程就是通过优化更新每一个神经元的权重和偏置系数,使得输出值Y更接近其真实值。
假设神经元的输入向量为 ,那么输出
,其中
是该神经元选定的激活函数。
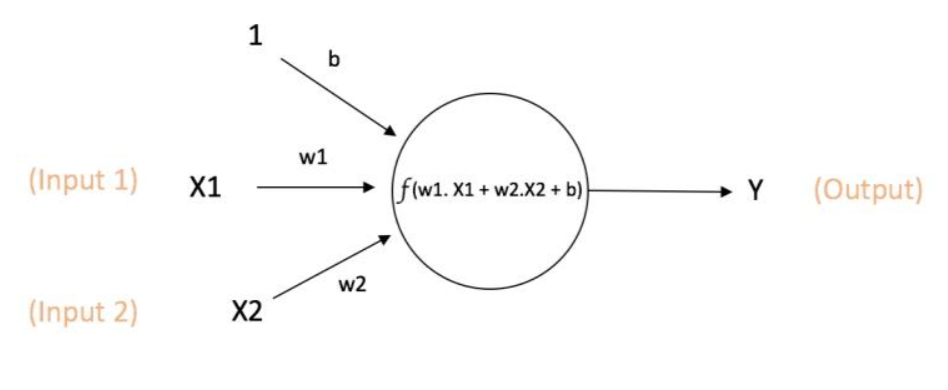
x1、x2表示输入量
w1、w2为权重,几个输入则意味着有几个权重,即每个输入都被赋予一个权重
b为偏置bias
f(z)为激活函数
举个例子,这周末北京有一草莓音乐节,那去不去呢?决定你是否去有二个因素,这二个因素可以对应二个输入,分别用x1、x2表示。此外,这二个因素对做决策的影响程度不一样,各自的影响程度用权重w1、w2表示。一般来说,音乐节的演唱嘉宾会非常影响你去不去,唱得好的前提下 即便没人陪同都可忍受,但如果唱得不好还不如你上台唱呢。所以,我们可以如下表示:
:是否有喜欢的演唱嘉宾。 = 1 你喜欢这些嘉宾, = 0 你不喜欢这些嘉宾。嘉宾因素的权重 = 7
:是否有人陪你同去。 = 1 有人陪你同去, = 0 没人陪你同去。是否有人陪同的权重 = 3。
这样,咱们的决策模型便建立起来了:g(z) = g( * + * + b ),g表示激活函数,这里的b可以理解成 为更好达到目标而做调整的偏置项。
2、激活函数
由图一可知,没有激活函数的神经元只是一个的线性回归模型,只能拟合线性平面
激活函数为其增加了非线性特征的学习能力。
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。
sigmoid的函数表达式如下:
其中z是一个线性组合,比如z可以等于:b + 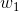
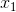
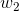
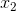
因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):
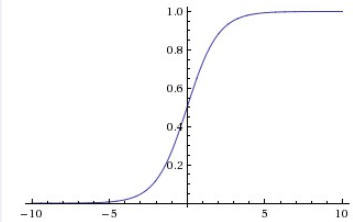
也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。
压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
举个例子,如下图(图引自Stanford机器学习公开课)

z = b + w1*x1 + w2 * x2,其中b为偏置项,假定取-30,w1、w2都取为20
- 如果x1 = 0, x2 = 0, 则z = -30, g(z) = 1/(1 + e ^ (-z))趋近于0。此外,从上图sigmoid函数的图形上也可以看出,当z = -30 的时候,
g(z)的值趋近于0。
- 如果x1 = 0, x2 = 1, 或x1 = 1,x2 = 0, 则z = b + w1 *x1 + w2 *x2 = -30 + 20 = -10, 同样,g(z)的值趋近于0。
- 如果x1 = 1, x2 = 1, 则z = b + w1 * x1 + w2 * x2 = -30 + 20*1 + 20*1 = 10, 此时, g(z)趋近于1.
换言之,只有
3、神经网络构架
输入——它是为学习过程输入模型的一组特征。例如,对象检测中的输入可以是与图像有关的像素值数组。
权重——它的主要功能是重视那些对学习贡献更大的特征。它通过在输入值和权重矩阵之间引入标量乘法来实现。例如,一个否定词比一对中性词更能影响情感分析模型的决策。
传递函数——传递函数的作用是将多个输入组合成一个输出值,以便可以应用激活函数。它是通过对传递函数的所有输入进行简单求和来完成的。
激活函数——它在感知器的工作中引入非线性,以考虑随输入变化的线性。如果没有这个,输出将只是输入值的线性组合,并且无法在网络中引入非线性。
偏差——偏差的作用是转移激活函数产生的值。它的作用类似于一个常数在线性函数中的作用。
当多个神经元连续堆叠在一起时,它们就构成了一层,多层相互相邻堆叠的称为多层神经网络。
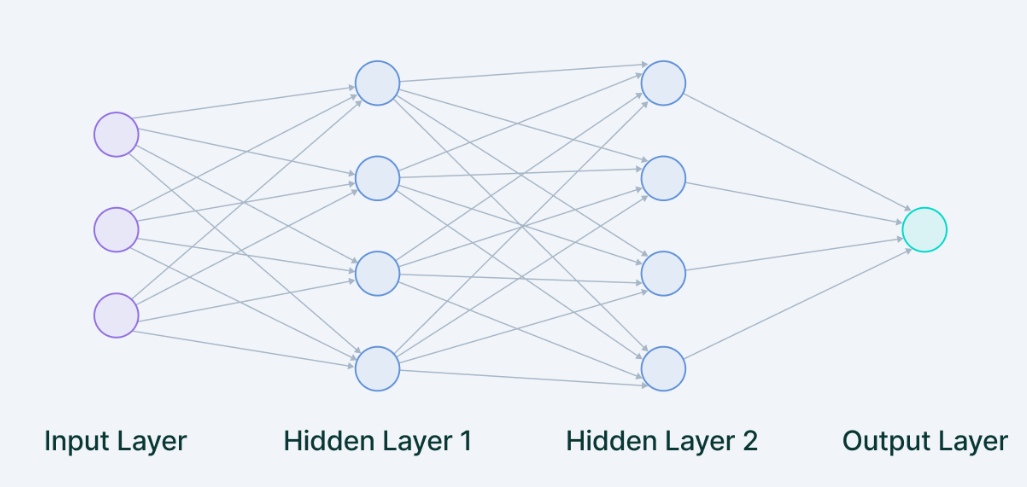
输入层
众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
我们提供给模型的数据从外部源(如 CSV 文件或 Web 服务)加载到输入层。它是完整神经网络架构中唯一可见的层,无需任何计算即可传递来自外界的完整信息。
隐藏层
讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
隐藏层使深度学习成为今天的样子。它们是执行所有计算并从数据中提取特征的中间层。
可以有多个互连的隐藏层,用于搜索数据中的不同隐藏特征。例如,在图像处理中,第一个隐藏层负责更高级别的特征,如边缘、形状或边界。另一方面,后面的隐藏层执行更复杂的任务,例如识别完整的对象(汽车、建筑物、人)。
输出层
是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。
输出层从前面的隐藏层获取输入,并根据模型的学习得出最终预测。这是我们获得最终结果的最重要的层。
在分类/回归模型的情况下,输出层通常有一个节点。但是,它完全是针对特定问题的,并且取决于模型的构建方式。
剖析: 多个层链接在一起组成了网络,将输入数据映射为预测值。然后损失函数将这些预测值与目标进行比较,得到损失值,用于衡量网络预测值与预期结果的匹配程度。
优化器使用这个损失值来更新网络的权重。