1 梯度下降简介
1.1 什么是梯度下降

梯度是一个向量
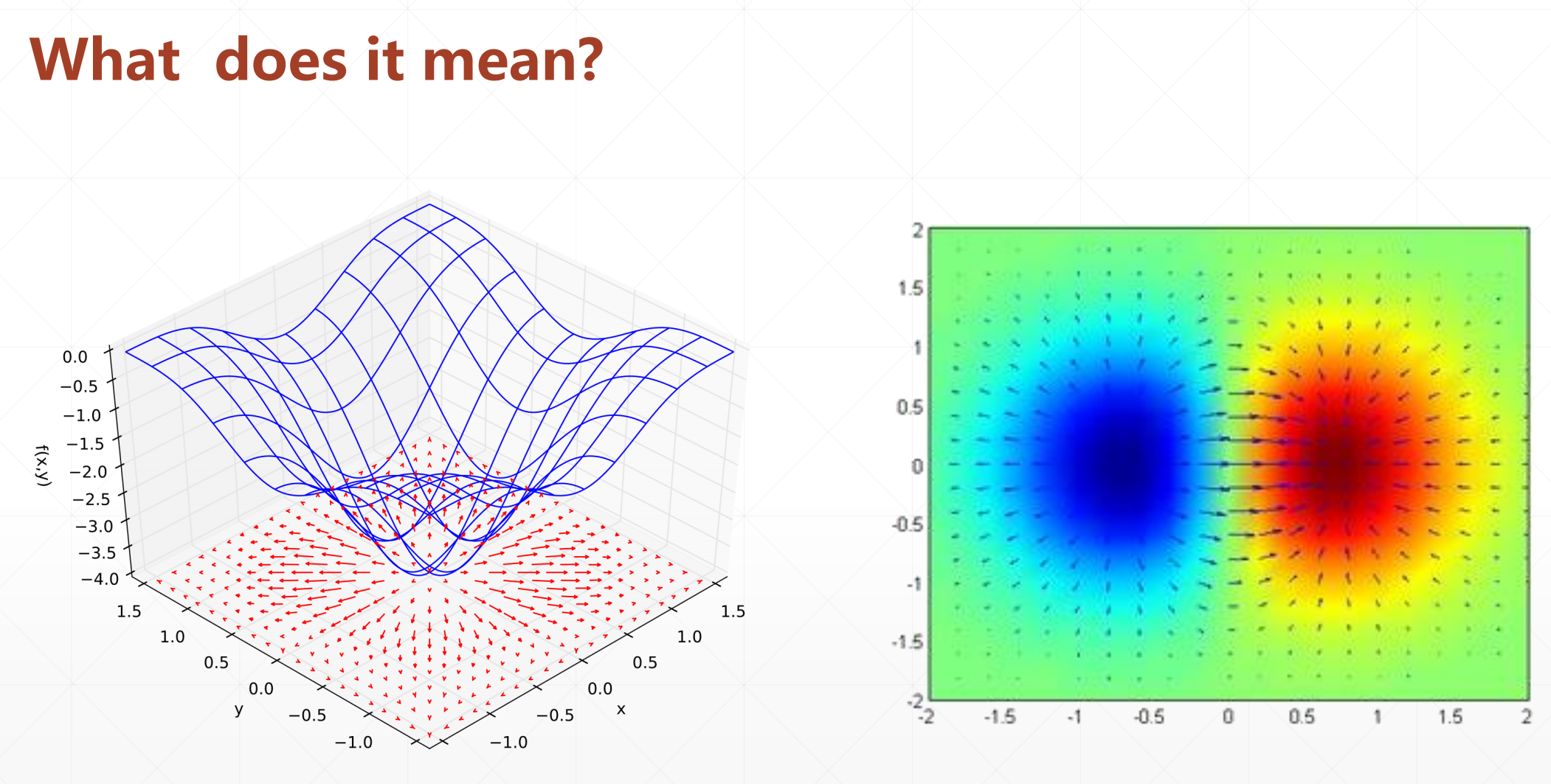
那些红色箭头就是梯度的方向,箭头越大,说明我们增加的越快。
我们之前说过就是一直往他梯度减小的方向走就行,就能走到最低点
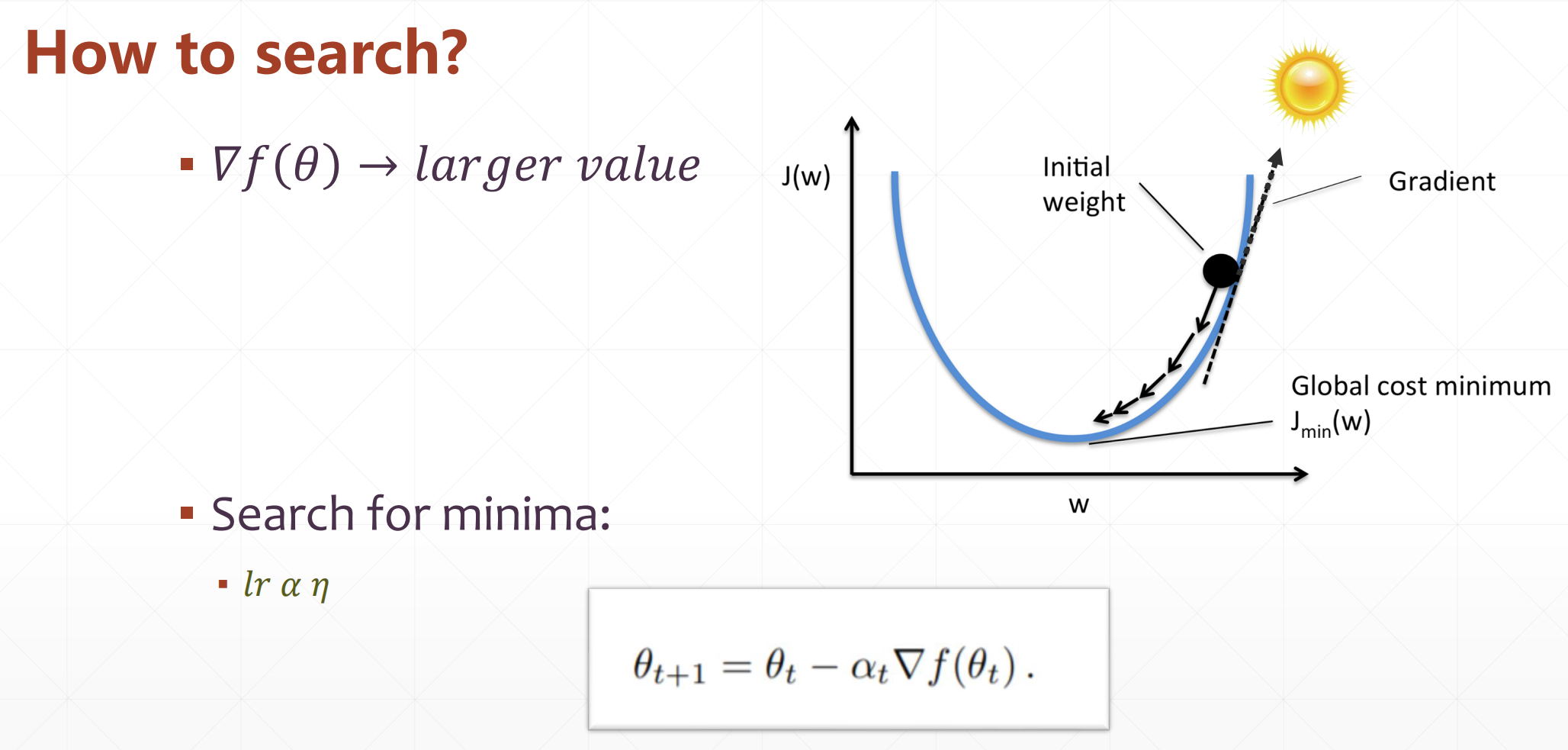
例子:


1.2 怎么用TensorFlow做梯度下降
我们这里用到两个API:
with tf.GradientRape() as tape:
build computation graph
loss=f(x)
[w_grad]=tape.gradient(loss,[w])
#在这里我们传入的如果是[w1,w2,w3],返回的就是[w1_grad,w2_grad,w3_grad]

例子:
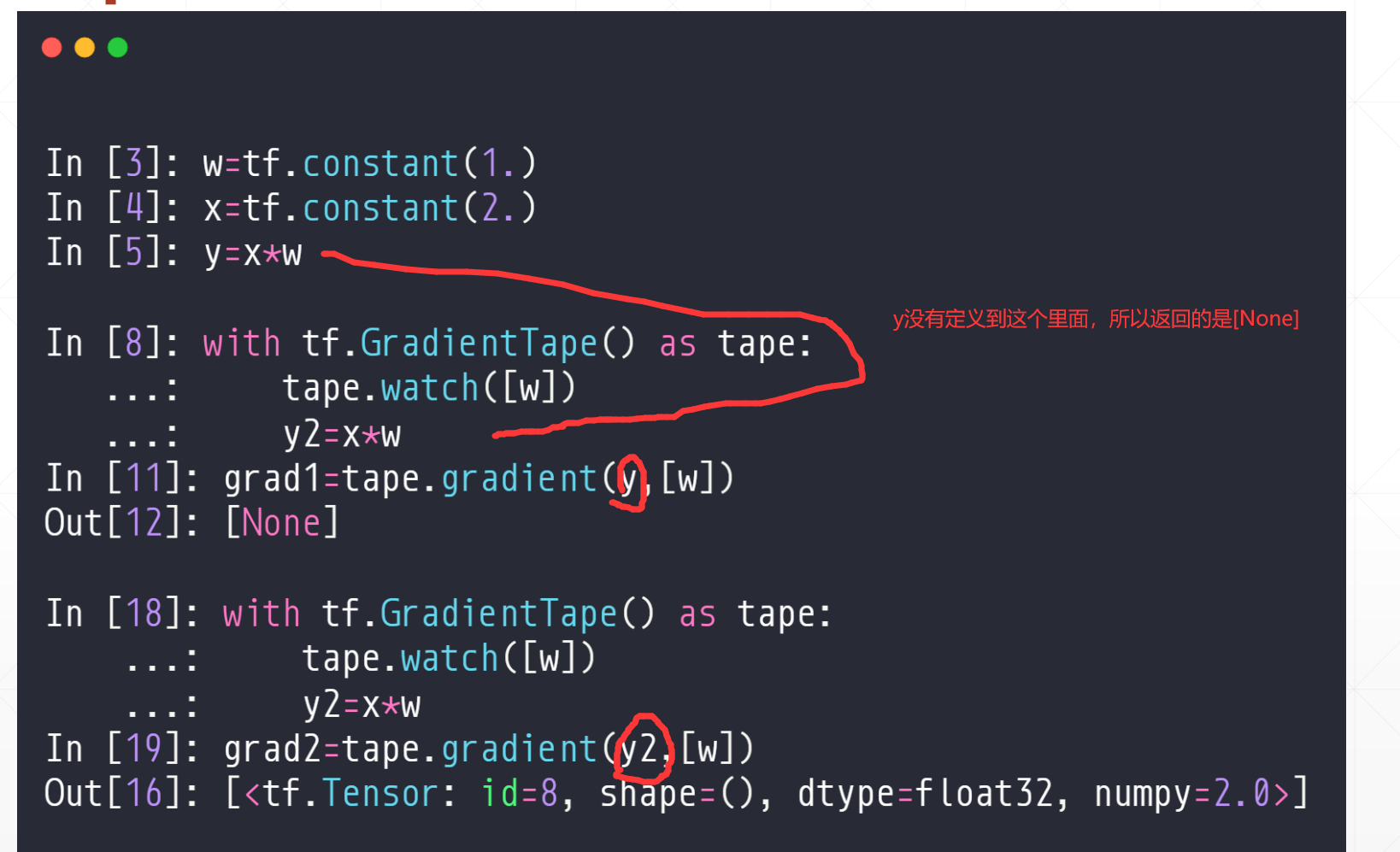
注意我们要求解y的梯度的时候我们一定要把他的表达式定义到函数里面去,对于里面的参数,我们有些需要定义成tf.Variable()类型,这样方便进行梯度跟踪。
1.3 二阶梯度

实现:就是定义两个GradientTape()

2 常见函数梯度
2.1 common Functions
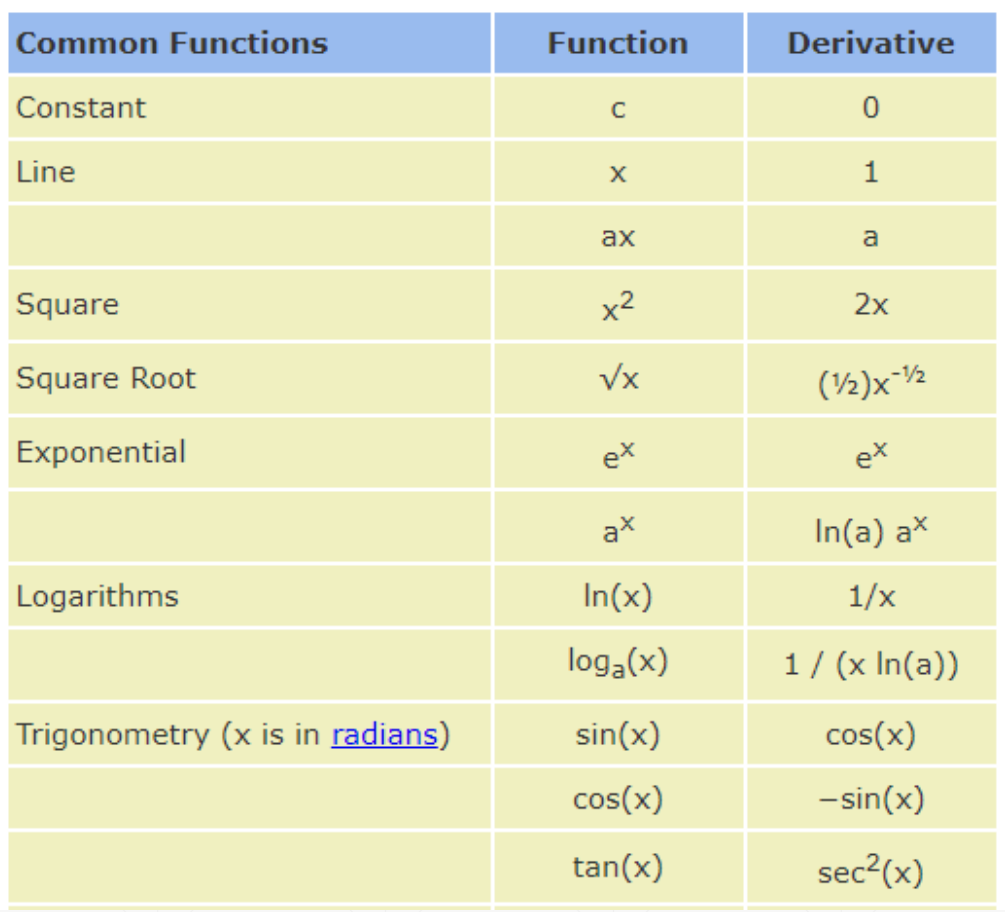
2.2 常见函数的梯度
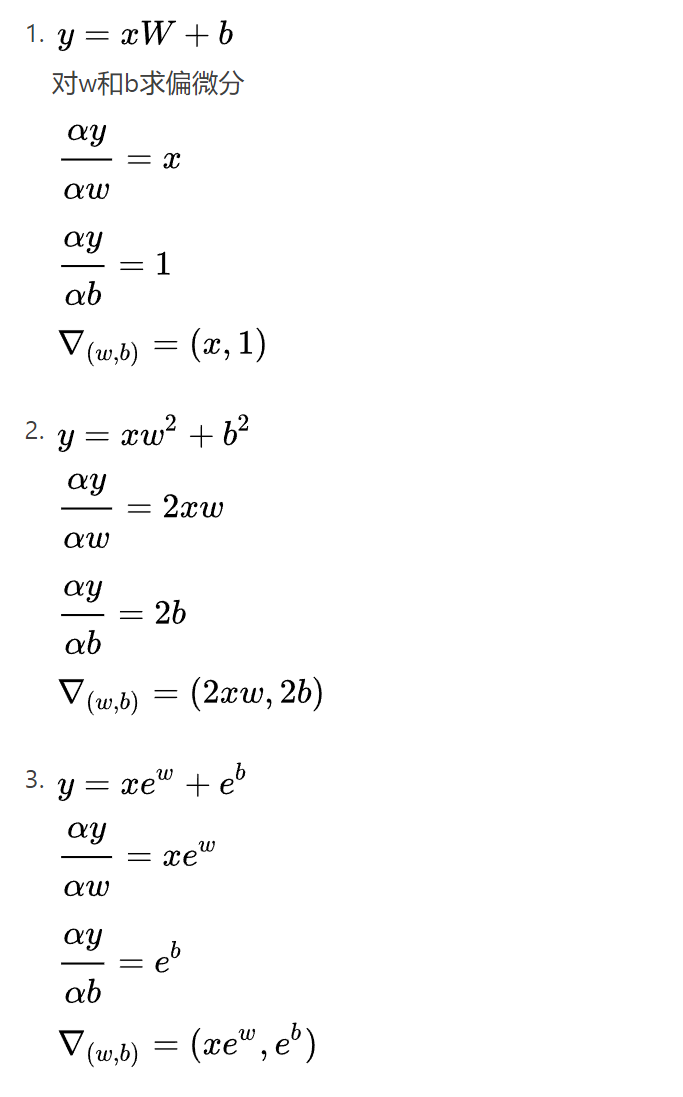

其实就是对每一个数求偏导,然后(,,,,)连起来
3 激活函数及其梯度
▪ sigmoid
▪ tanh
▪ relu
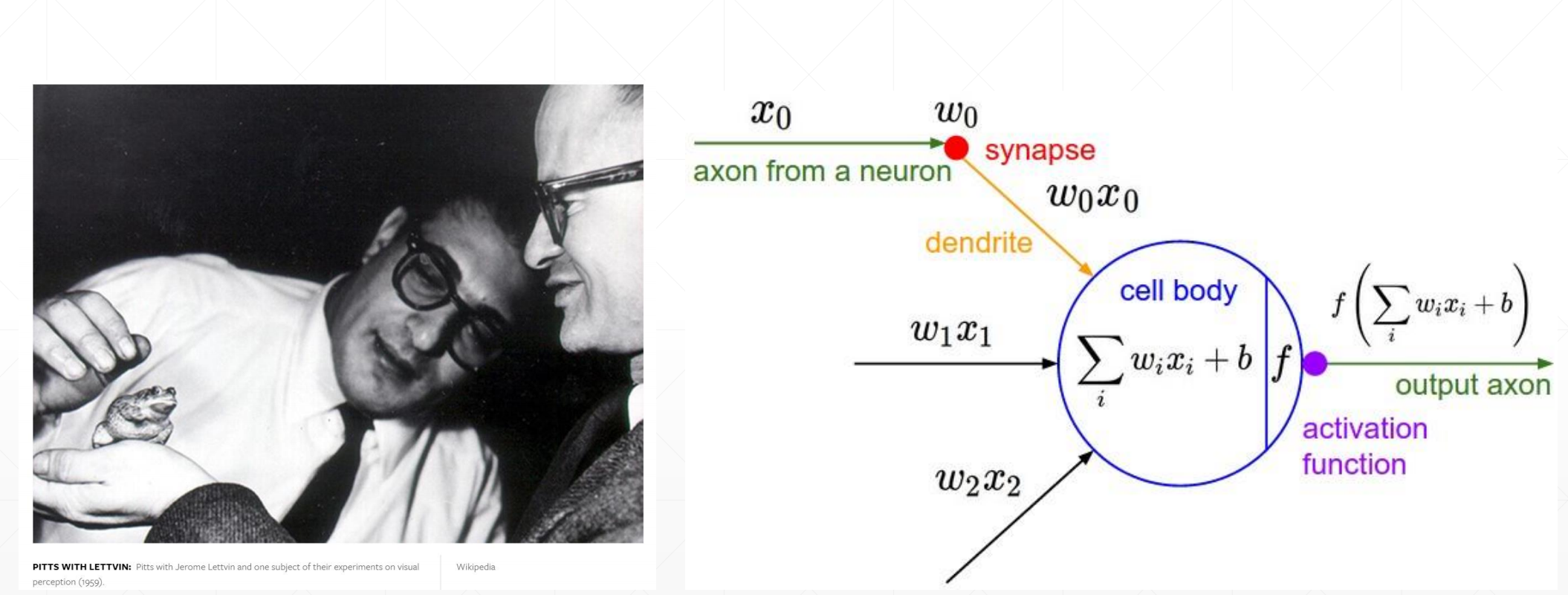
科学家们对青蛙做了一个实验,就是如果这个输入小于一个值的时候这个青蛙不会响应,大于一个值的时候。就是有一个阈值函数,超过了这个阈值才会输出。
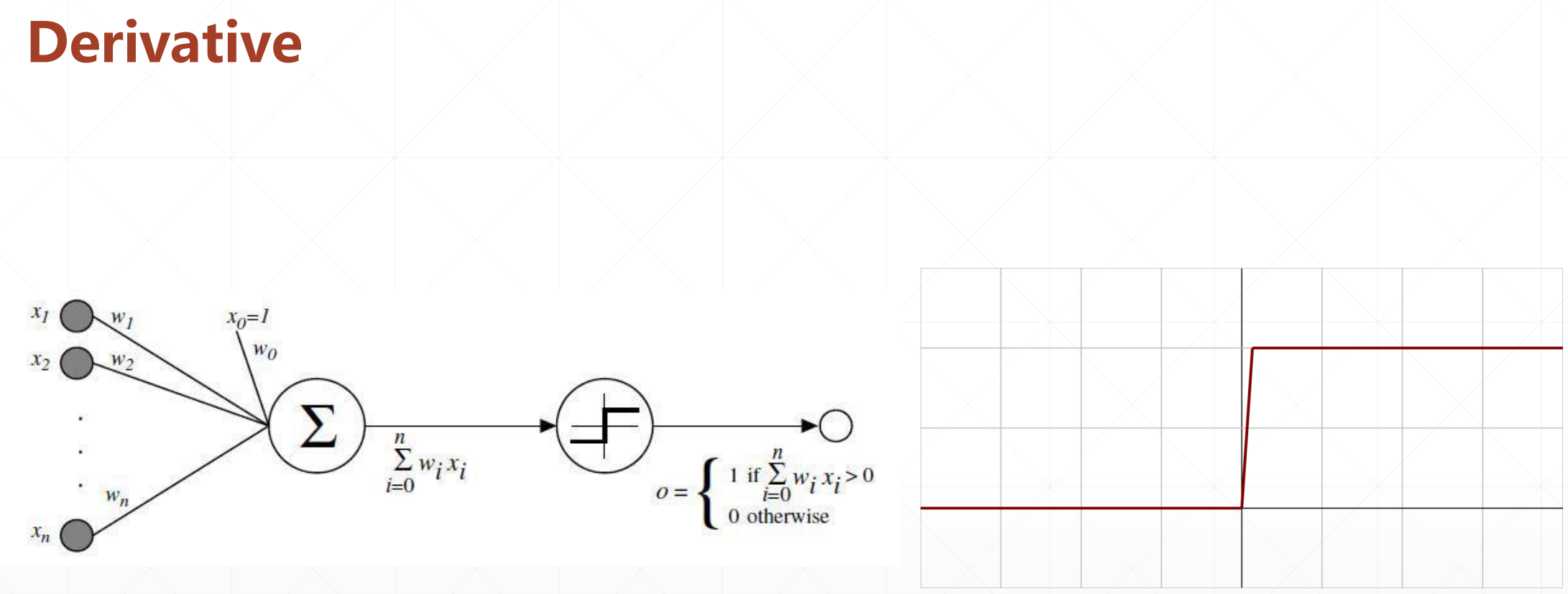
这就是激活函数:就是这个值必须大于0,这个节点才能激活。
激活函数是不可导的,所以我们不能利用梯度下降的方法进行求解。
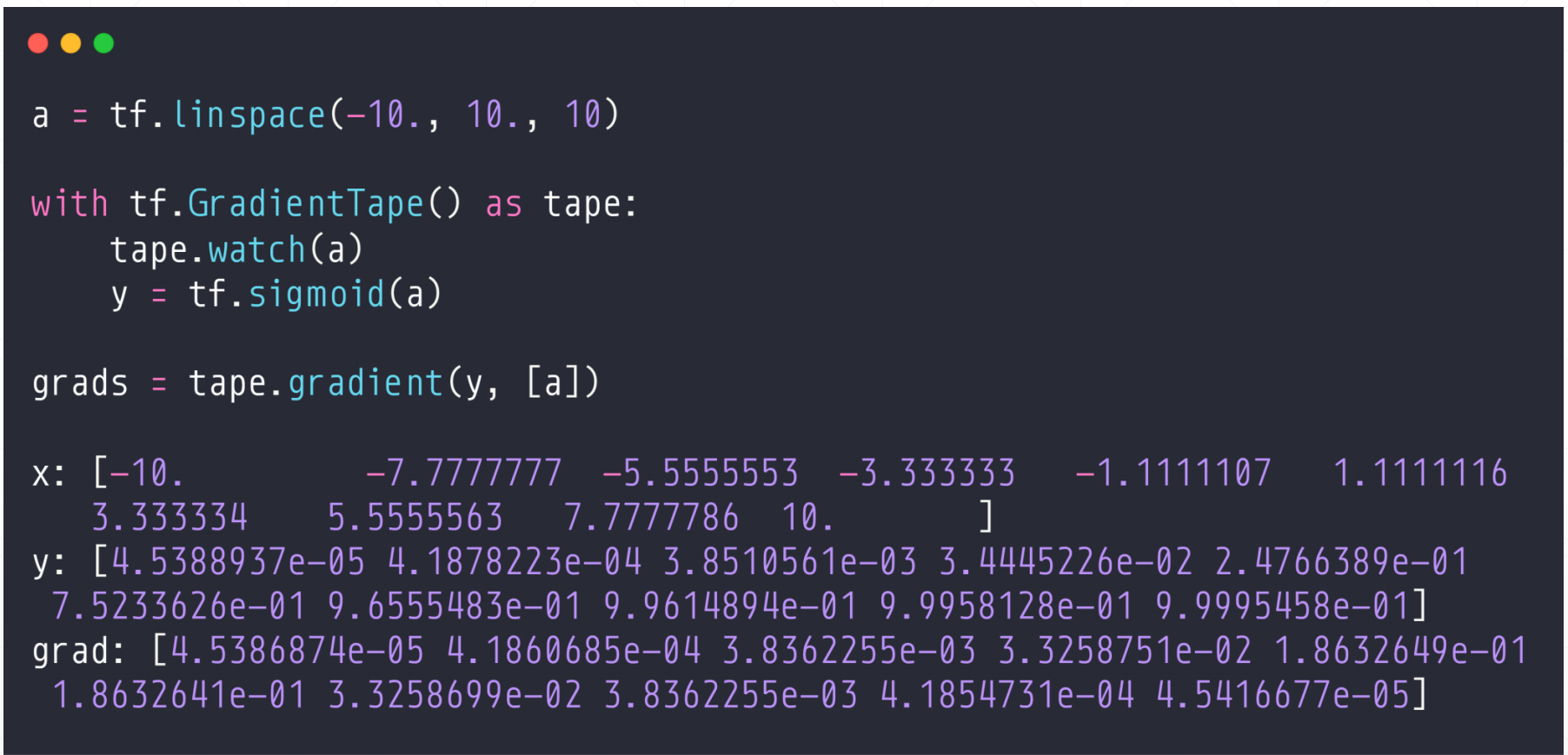
3.1 sigmoid函数
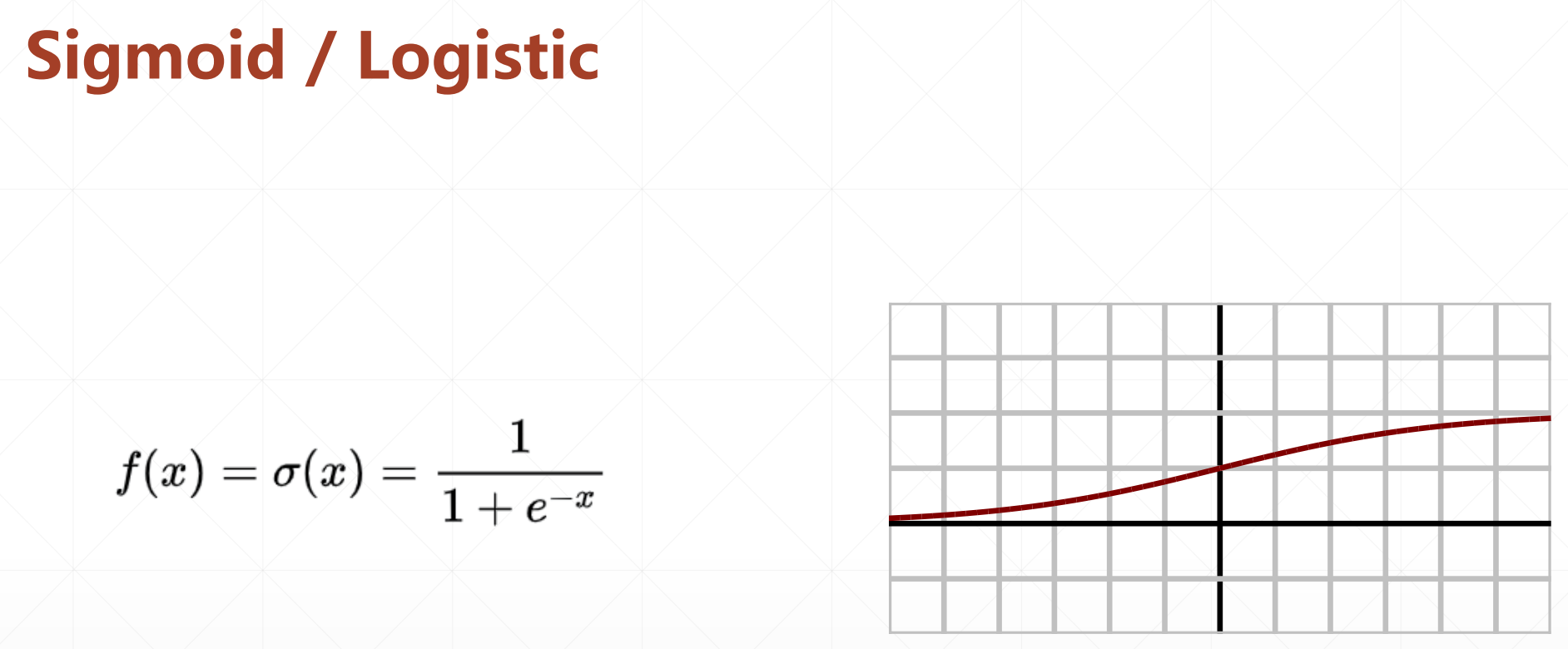
这个函数就很好,就是很低的时候,它不响应,然后趋于0。很大的时候它也不会很大,就是1。注意如果x很大或者很小的时候会出现梯度饱和或者弥散的情况
sigmoid函数的导数:可以看出sigmoid函数的导数是可以通过sigmoid函数本身求出的。
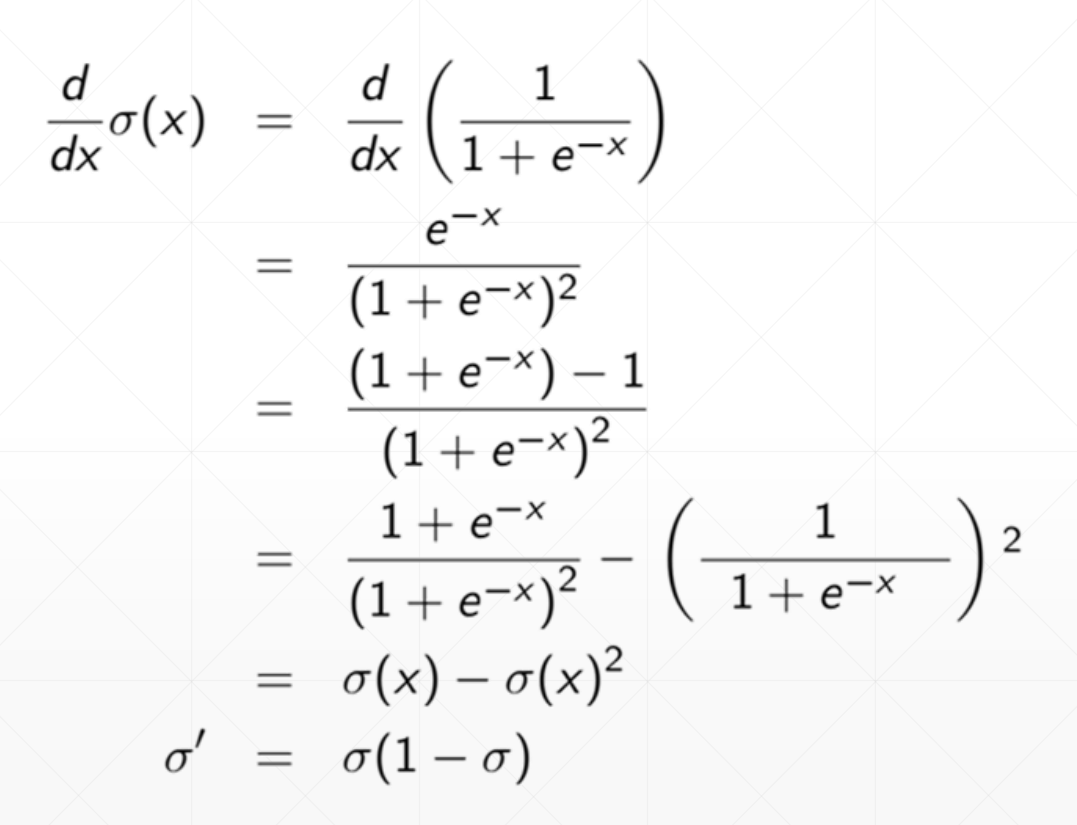
API:
tf.sigmoid()
3.2 Tanh函数
这个是把函数值映射到[-1,1]之间。

他的导数:也是可以通过tanh函数本身求出的。
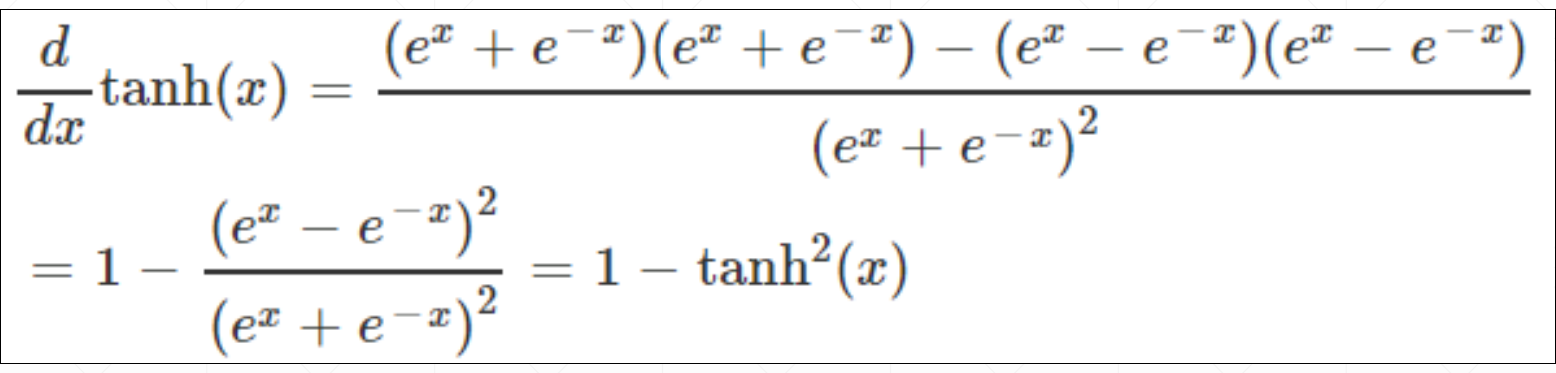
API:
tf.tanh

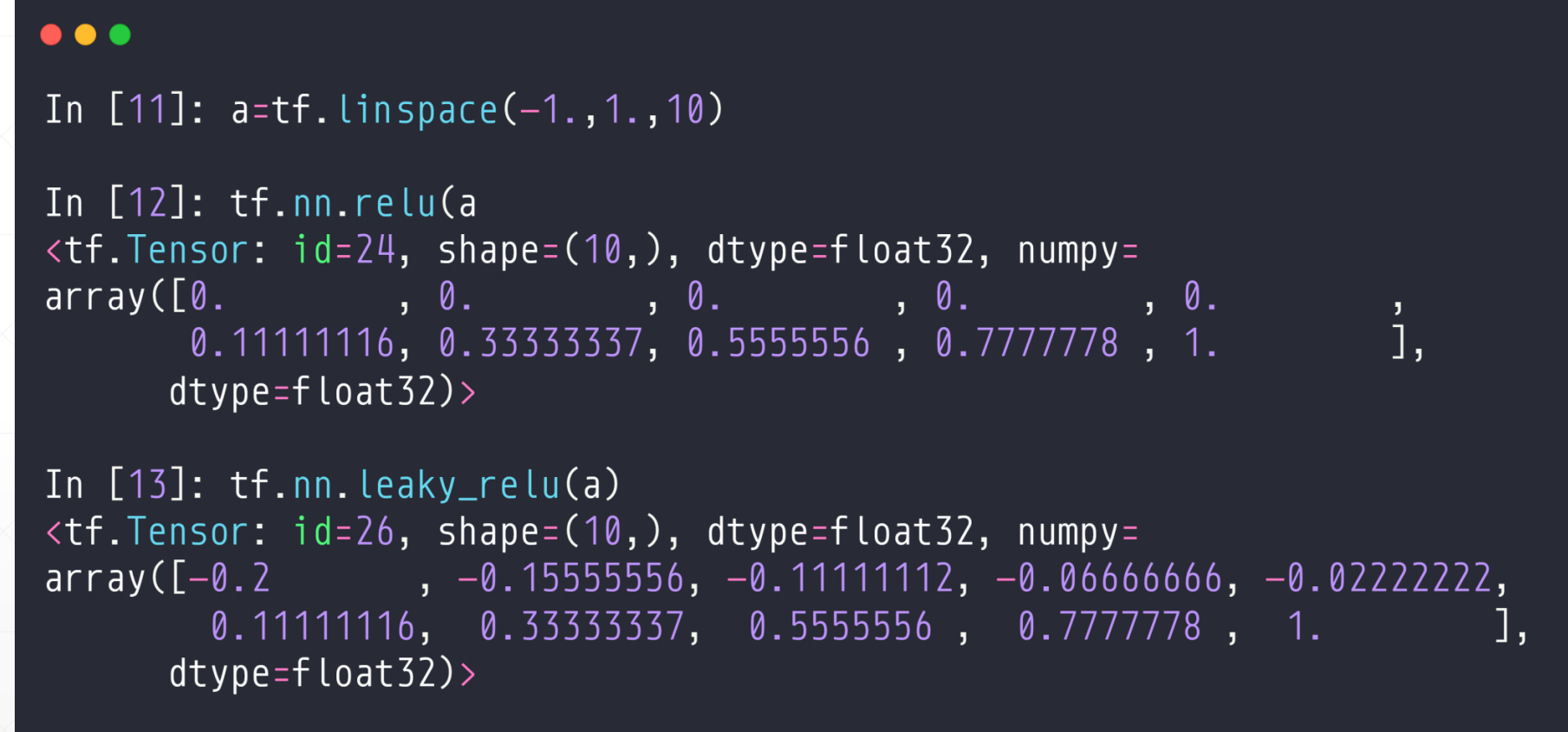
3.3 ReLU函数
ReLU非常适合做deep learning。因为它当x>0的时候他的梯度就是1,不会放大也不会缩小,所以在很大情况下减少了sigmodi带来的那种梯度爆炸或者梯度弥散的情况。非常适合做Deep Learning。

API
tf.nn.relu()
tf.leaky_relu(a)#这个是如果小于0的话,他会很小的接近0.
4 损失函数及其梯度
Mean Squared(MSE)\(\sum\)(y-y')^2
Cross Entropty Loss
- binary(二分类)
- multi-class
- +softmax(通常和softmax连用)
- Leave it to Logistic Regression Part
4.1 MSE

求导:
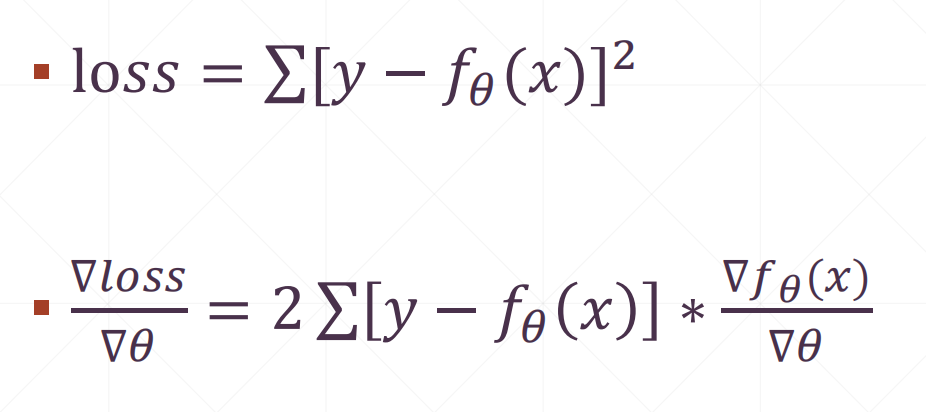
其中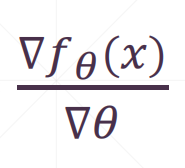
取决于你用什么模型。