对于垃圾回收回收的基本概念
基本单元:
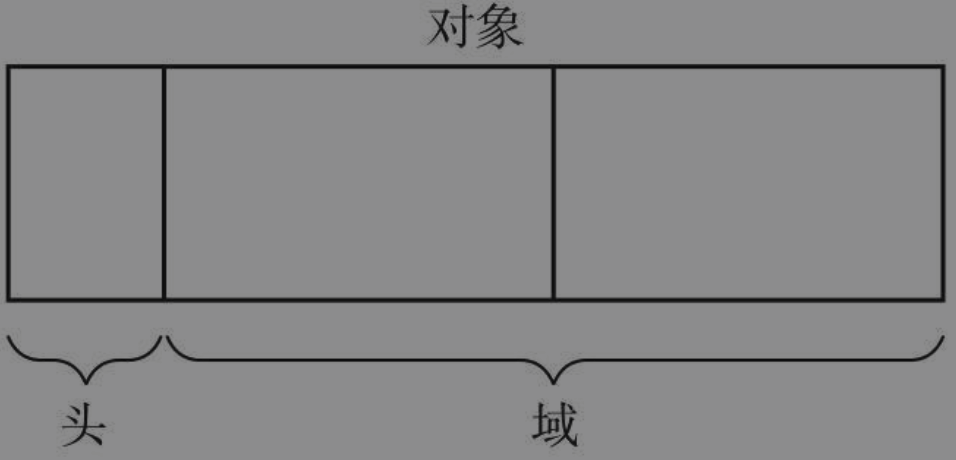
对象(个体基础单元)包括两个部分。head(头),field(域)。
head里核心内容:对象大小,对象种类。
field里主要分两种:指针,非指针。
mutator某种意义上就是实体应用本身,主要进行两个事情创建对象,更新指针。(gc就是为他擦屁股的,帮他处理不需要的遗留)
堆一个动态的存放对象的内存空间。当一个当mutator需要把产生的对象申请往堆里存放,gc会管理这些被丢进堆里的对象,当堆达到最大的时候,gc就会启动,清理出空间让对象能就被继续放入(条件允许我们一般是扩大内存)。
活动对象/非活动对象,可以说是否被mutator引用的对象就是活动对象,非活动对象就是相反的(也就是垃圾)。
提问:死掉的对象可以活过来吗?
分配(allocater),当mutator需要一个新对象的时候,向allocater会申请一个大小合适的空间,allocater会从堆的空间寻找一个足够空间返回给mutator。
堆被所有活动空间占满,无法分配出空间一般会有两种操作:1扩大分配的内存。2直接销毁当前结果,抛出异常日志打出错误信息。
我总结了一下这个流程大致是如此(如若不对请斧正):
应用(mutator)--产生对象--》分配(allocater)--申请空间--》堆
分块(chunk)这是一个有趣的东西,初始化时候整个应用的内存空间(堆)就是一个大大大的快,有点像一个蛋糕,需要多少就从这里切一点。然后不需要的(垃圾)又会被销毁又会被回收拿回来继续分块。
提问:被分块的部分可以被继续被分块吗?
根(root) 再整个gc的世界,根是所有对象的起点。(gc也是无法严谨判断指针和非空指针的)通过mutator直接引用调用栈(call stack)和寄存器。也就是说,调用栈、寄存器以及全局变量空间都是根。


提问:一般的根会有哪些?
一般对gc评价一本从以下四个方面· 吞吐量· 最大暂停时间· 堆使用效率· 访问的局部性。

如图:
吞吐量 = headsize/a+b+c 也就是堆大小除以gc总耗时。
最大暂停时间,也就是abc中的最大值,处于gc的时候他是没法做其他事情的,就好像吃饭你总要去咀嚼吞咽,不能持续喂饭的操作。这就需要等上一口吃完。这种事情就像浏览器在等待响应一样的。
堆使用效率,有两个决定性因素,一个是头(head越小越好),一个是堆的用法(不同的gc算法会有影响,类如复制算法和标记清除就会存在各自差异,辅助算法会把head分成两个部分一部分用一部分做出调整,标记清除适用范围就是整个head
访问的局部性,下面这个图就代表了存储空间内的相互局部性。

一般使用效率高,吞吐量就上不去,不可兼得,简单地说就是:可用的堆越大,GC运行越快;相反,越想有效地利用有限的堆,GC花费的时间就越长(因为频繁的gc)。
(答案评论区,为了防止放弃思考我丢下面去了。。。)