三种JVM
- Sun公司的 HotSpotJava Hotspot™ 64-Bit Server VM (build 25.181-b13,mixed mode)
- BEA JRockit
- IBM J9VM
我们学习和使用的大都是:Hotspot
JVM体系结构
jvm的位置
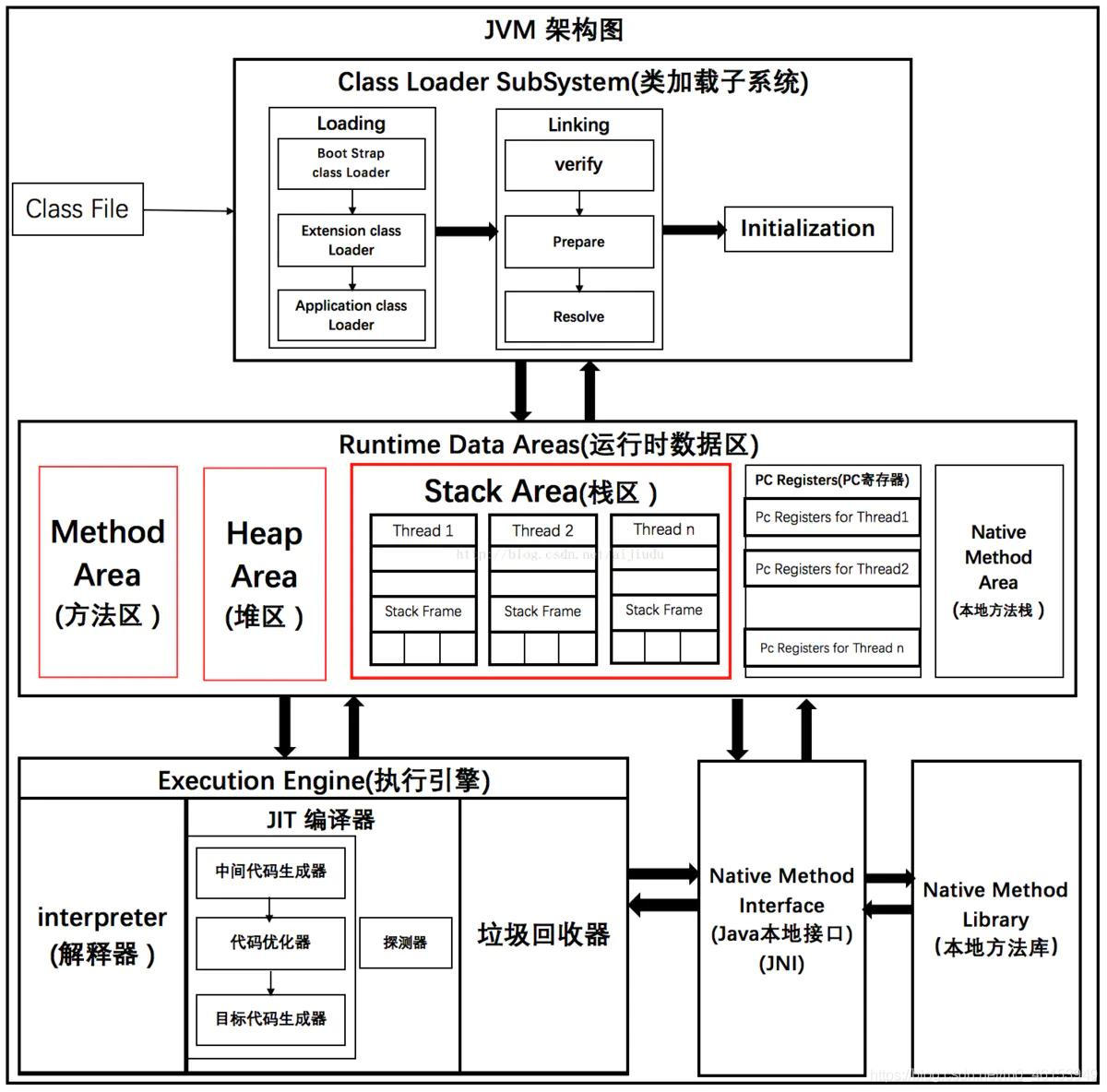
JVM体系结构
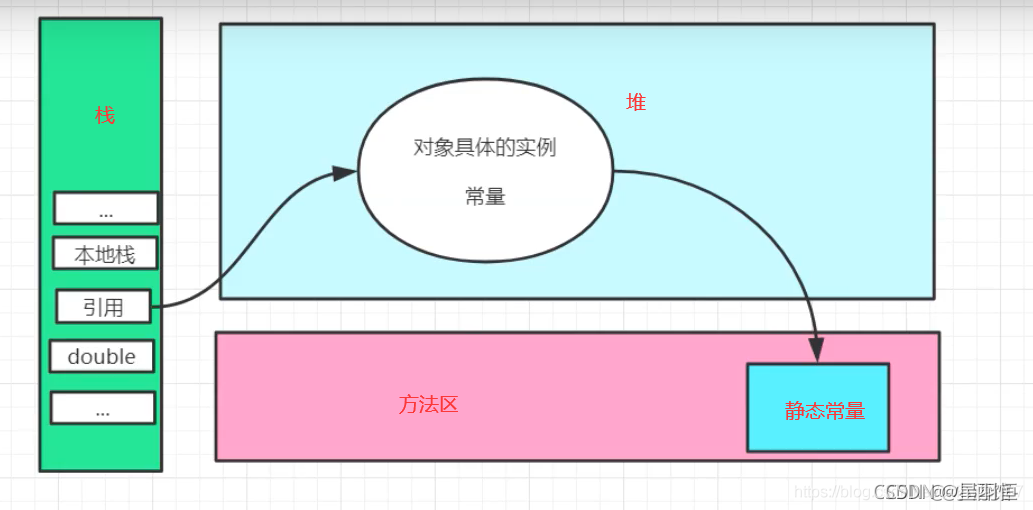
方法区
-
方法区存储虚拟机加载的类信息、常量、静态变量、即时编译器翻译后的代码等数据;
-
是JVM规范中的一部分,并不是实际的实现,在实际实现上并不相同(HotSpot在1.7版本以前和1.7版本,1.7后都有变化)。
-
当方法区无法满足内存分配需求时,将抛出OutOfMemoryError(OOM)异常
java堆
-
仅有一个堆,Java堆用于存放new出来的对象的内容。
-
是垃圾收集器管理的主要区域。可细分为:新生代和老生代;新生代又可分为Eden、from Survivor, to Survivor。
-
如果在堆中 没有内存完成实例分配, 并且堆也无法再扩展时,将会抛出 OutOfMemoryError 异常。
Java栈
- 存放的东西(局部变量):八大基本类型 + new出来的对象引用地址 + 实例方法的引用地址。
- 每一条 java虚拟机线程都有自己私有的java虚拟机栈,这个 栈和线程同时创建, 用于存储 栈帧。
- Java虚拟机栈是 Java方法执行的内存模型,每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
- 栈帧(Stack Frame) 存储局部变量表,操作数据栈,动态链接,方法出口等信息,随着方法的调用而创建,随着方法的结束而销毁。
- 在Java虚拟机规范中,对这个区域规定了两种异常状况:
- 如果 线程请求的栈深度 大于 虚拟机所允许的深度,将抛出StackOverflowError异常;
- 如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时,会抛出OutOfMemoryError异常。
本地方法栈
- 本地方法栈和虚拟机栈非常相似,不同的是 虚拟机栈服务的是【Java方法】,而 本地方法栈服务的是【Native方法】
- HotSpot虚拟机 直接把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError 和 OutOfMemoryError 异常。
程序计数器
- java虚拟机可以支持多个线程同时运行,每个java虚拟机线程都有自己的程序计数器(PC寄存器)。
- 在任意时刻,一个java虚拟机的线程,只会执行一个方法的代码。
- 程序计数器记录 【当前线程所执行的Java字节码的地址】。
- 当执行的是Native方法时,程序计数器为空。 程序计数器是JVM规范中唯一一个没有规定会导致OOM(OutOfMemory)的区域。
类加载的过程
概述
图示
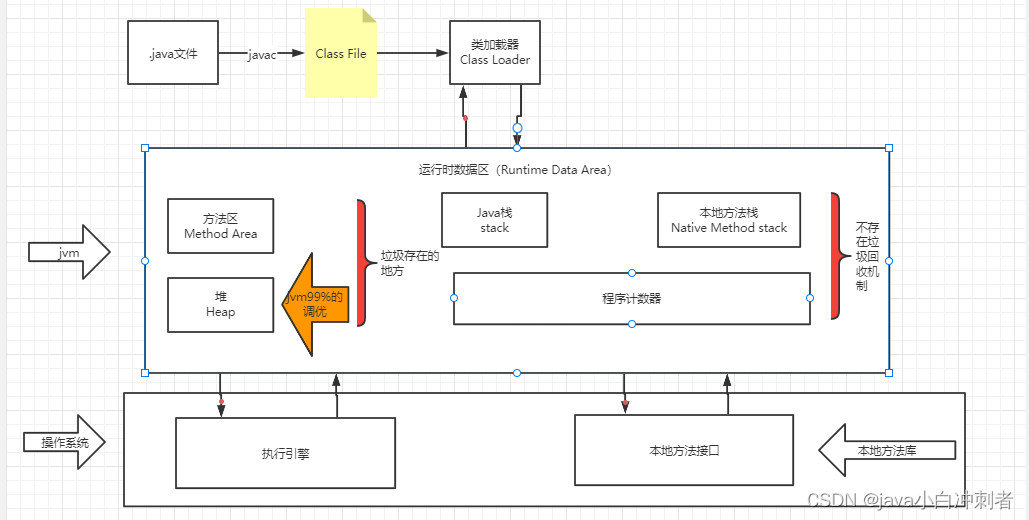
运行顺序
- java源代码文件会被java编译器译为字节码文件(.class后缀)。
- 然后由JVM中的类加载器加载各个类的字节码文件。
- 加载完毕后,交由JVM执行引擎执行。
垃圾和调优
99%的JVM调优都是在堆中调优,java栈,本地方法栈,程序计数器是不会有垃圾存在的。
流程
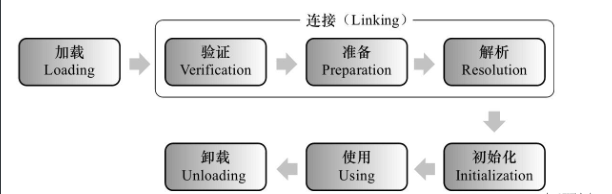
其中 加载、验证、准备、初始化、卸载这五个阶段的过程是固定的,在类加载过程中必须按照这种顺序按部就班的进行,而解析阶段就不一样了,可以在初始化后进行,是为了支持java语言的运行时绑定。
加载
- 通过一个类的权限定名获取定义此类的二进制字节流;
- 将这个字节流所代表的的静态存储结构转换为方法区的运行时数据结构;
- 在堆内存中生成一个代表这个类的java.lang.Class对象,作为访问方法区这个类的各种数据结构的入口;
加载阶段完成后,虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区中,而且在java堆中也创建一个java.lang.Class类的对象,这样便可以通过该对象访问方法区中的这些数据。
验证
这一阶段主要是为了确保Class文件的字节流中包含的信息符合虚拟机的要求,并且不会危害虚拟机自身的安全
四个校验动作:
- 文件格式验证:验证字节流是否符合Class文件格式的规范。
- 元数据验证:对字节码描述的信息进行语义分析,以保证其描述的信息符合Java语言规范的要求。
- 字节码验证:通过数据流和控制流分析。确定程序语义是合法的、符合逻辑的。
- 符号引用验证:确保解析动作能正确执行。
准备
是正式为类变量分配内存并设置初始值的阶段,这些变量所使用的的内存都将在方法区(方法区的静态域中)分配。
进行内存分配的仅包括类变量(static),而不包括类常量(static final)和实例变量,实例变量会在对象实例化时随着对象一块分配在java堆中,初始值通常情况下是数据类型的默认值。
解析
是将虚拟机常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定附。(个人理解:解析过程可能在初始化之前,也可能在初始化之后。因为针对在运行中才能确定的的值,解析的时机不同。比如针对类变量来说,在初始化时就要将符号引用转换为直接引用。针对成员变量来说,在创建对象的时候才解析。)
符号引用:
- 与虚拟机实现的布局无关,引用的目标并不一定要已经加载到内存中。虚拟机能接收的符号引用必须是一致的,因为符号引用的字面量形式明确定义在java虚拟机规范的Class文件格式中。
直接引用:
- 可以是指向目标的指针,相对偏移量或者是一个能间接定位到目标的句柄,如果有了直接引用那么引用目标必定已经在内存中存在。
初始化
概述
类初始化时类加载的最后一步,处理加载阶段,用户可以通过自定义的类加载器参数,其他阶段都完全由虚拟机主导和控制。到了初始化阶段才真正执行Java代码。
类的初始化的主要工作是为了静态变量赋程序设定的初始值(类变量的赋值动作和静态代码块中的语句合并)
static int a=100; 在准备阶段a被赋默认值0,在初始化阶段就会被赋值为100
类初始化时机
java虚拟机规范中严格规定了有且只有五种情况必须对类进行初始化:
- 使用new创建类的实例,或者使用getstatic、putstatic读取或设置一个静态字段的值(放入常量池中的常量除外),或者调用一个静态方法的时候,对应类必须进行初始化。
- 通过java.lang.reflect包的方法对类进行反射调用的时候,要是类没有进行过初始化,则要首先进行初始化。
- 初始化一个类的时候,如果发现其父类没有进行过初始化,则首先触发父类初始化。
- 当虚拟机启动时,用户需要指定一个主类(包含main()方法的类),虚拟机会首先初始化这个类。
- 使用jdk1.7的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果REF_getStatic、REF_putStatic、RE_invokeStatic的方法句柄,并且这个方法句柄对应的类没有进行初始化,则需要先触发其初始化。
final在类加载过程中的理解
我们知道,用final修饰的变量就是常量。常量是在常量池中开辟的内存。
常量分为两种:编译期常量和运行期常量
编译期常量
指的就是程序在编译时就能确定这个常量的具体值
在Java中,编译期常量的定义是:用final关键字修饰的基本类型或String类型并直接赋值(非复杂运算)的变量(无论是否用static修饰),是编译器的一种优化,体现在字节码文件中。
编译时常量的一般规则
- 必须声明为fianl
- 必须是java原始数据类型或者String
- 必须用声明初始化
- 值必须是常量表达式
举例
final int i = 10;
final int j = 20, k = 30;
final String s = "Hello";
final float f = 10.5f;
final int i = 10 * 20; 只使用字面量
final int j = i; 使用其他的编译时常量
final int k = i * 20; 混合使用编译时常量和字面量
在将.java文件编译为.class文件的过程中,编译期常量会被替换为字面量
// 编译之前
final int i = 10;
short j = i;
System.out.println(i);
// 编译之后变成
final int i = 10;
short j = 10;
System.out.println(10);
运行期常量
就是程序在运行时才能确定常量的值,由运行时解释器解释完成的
举例
final int j = i; 使用了变量
final int k = Math.round(10.2); 方法调用
对类的依赖性
编译期常量和运行时常量对类的创建有什么不同的影响?
看代码分析
class Test {
静态代码块
static {
System.out.println("Class Test Was Loaded!"); }
编译期常量
public static final int num = 10;
运行时常量
public static final int len = "Rhien".length();
}
public class Main {
public static void main(String[] args) throws Exception {
System.out.println("num:"+Test.num);
System.out.println("=== after get num ===");
System.out.println("len:"+Test.len);
}
}
自己分析:
首先Main类有main()所以初始化,因为没内容所以无结果
再num是静态变量吧,算在内,所以读取静态变量是触发Test类初始化所以打印"Class Test Was Loaded!"
之后不用分析,纯运行结果接着打印
num:10
=== after get num ===
len:5
/* 而实际的打印输出是
* num:10
* === after get num ===
* Class Test Was Loaded!
* len:5
*/
原因在于编译期常量不依赖类,不会引起类的初始化;而运行时常量依赖类,会引起类的初始化
编译期常量会在编译阶段存入调用类的常量池,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化
补充:
静态常量什么时候被赋值?
如果是编译期的静态常量,因为能够直接的确定值,所以在编译时就已经被赋值并且在存储在常量池中
如果时运行期的静态常量,因为不能直接确定值,只有在真正运行的时候,通过符号引用转换为直接引用后,运行目标的字节码,才能确定他的值,所以在类加载过程中的初始化阶段才能被赋值。
类加载器
作用:加载.class文件
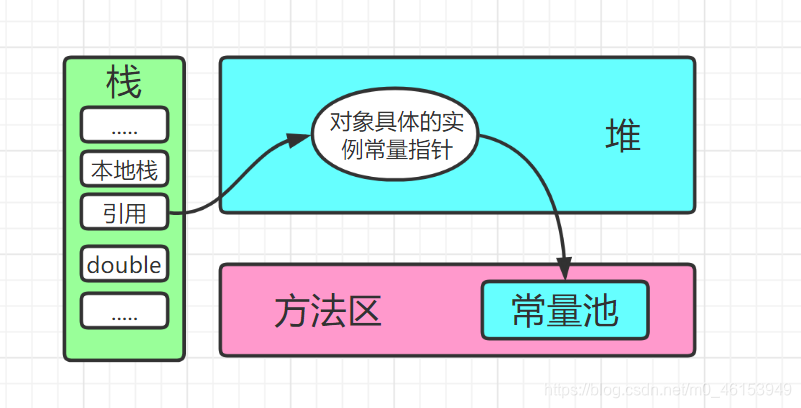
新建的对象放入堆中,引用(地址)放到栈,其中引用指向堆里边对应的对象。
基本流程
先来看看一个类加载到 JVM 的一个基本结构:
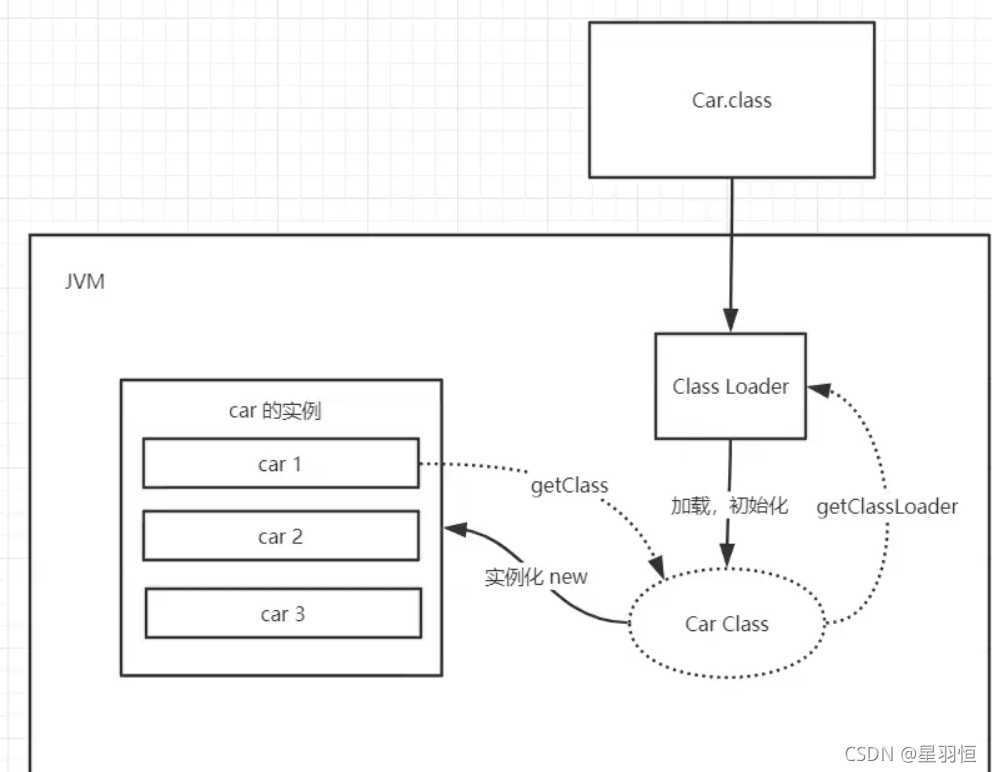
类是模板,对象是具体的,通过new来实例化对象。car1,car2,car3,名字在栈里面,真正的实例,具体的数据在堆里面,栈只是引用地址
虚拟机自带的加载器
- 启动类(根)加载器 Bootstrap ClassLoader
- 扩展类加载器 Extension ClassLoader
- 应用程序(系统类)加载器 Application ClassLoader
Car car = new Car();
Class<? extends Car > aClass = car.getClass();
// Application 加载器
ClassLoader classLoader = aClass.getClassLoader();
// ExtClassLoader 扩展类加载器
classLoader.getParent();
// null 1.不存在 2. java 获取不到(可能是c++写的)
classLoader.getParent().getParent();
类加载器的分类
- Bootstrap ClassLoader 启动类加载器-------->负责加载jre\lib目录下的rt.jar
- Extention ClassLoader 标准扩展类加载器-------->负责加载jre\lib\ext目录下的所有jar包
- Application ClassLoader 应用类加载器-------->负责加载用户类路径上所指定的类库,如果应用程序中没有自定义加载器,那么此加载器就为默认加载器。
- User ClassLoader 用户自定义类加载器
双亲委派机制
举例
package java.lang;
/**
* @author
* @create
*/
public class String {
/*
双亲委派机制:安全
1.APP-->EXC-->BOOT(最终执行)
*/
public String toString() {
return "Hello";
}
public static void main(String[] args) {
String s = new String();
System.out.println(s.getClass());
s.toString();
}
/*
向上委托,向下加载:
1.类加载器收到类加载的请求
2.将这个请求向上委托给父类加载器去完成,一直向上委托,直到启动类加载
3.启动加载器检查是否能够加载当前这个类,能加载就结束,使用当前的加载器,否则,抛出异常,通知子加载器进行加载
4.重复步骤3
*/
}
idea报了一个错误:

报错是因为:自己的类在自定义的java.lang.String,而在jre目录下也有个java.lang.String类,在执行main方法的时候,首先会加载String类,但是到底是要加载那个String类,加载器按照APP→EXC→BOOT顺序委托,最终在BOOT负责jre目录下的java.lang包下找到的String类,所以就会选择这个类加载,但是在加载过程中,没有main方法,加载失败报出异常(找不到main方法)
执行过程:在运行一个类之前,首先会在应用程序加载器(APP)中找,继续向上在扩展类加载器EXC中找,然后再向上,在启动类( 根 )加载器BOOT中找。如果在BOOT中有这个类的话,最终执行的就是根加载器中的。如果BOOT中没有的话,就会倒找往回找。
过程总结
- 类加载器收到类加载的请求;
- 将这个请求向上委托给父类加载器去完成,一直向上委托,直到启动类加载器;
- 启动类加载器检查是否能够加载当前这个类,能加载就结束,使用当前的加载器。不能加载就会抛出异常,一层一层向下,通知子加载器进行加载。
- 重复步骤3
作用
概念
当某个类加载器需要加载某个.class文件时,它首先把这个任务委托给他们的上级类加载器,递归这个操作,如果上级类加载器没有加载,自己才会去加载这个类。
例子
当一个Hello.class这样的文件要被加载时。不考虑我们自定义类加载器,首先会在AppClassLoader中检查是否加载过,如果有那就无需再加载了。如果没有,那么会拿到父加载器,然后调用父加载器的loadClass方法。父类中同理也会先检查自己是否已经加载过,如果没有再往上。注意这个类似递归的过程,直到到达Bootstrap classLoader之前,都是在检查是否加载过,并不会选择自己去加载。直到BootstrapClassLoader,已经没有父加载器了,这时候开始考虑自己是否能加载了,如果自己无法加载,会下沉到子加载器去加载,一直到最底层,如果没有任何加载器能加载,就会抛出ClassNotFoundException。
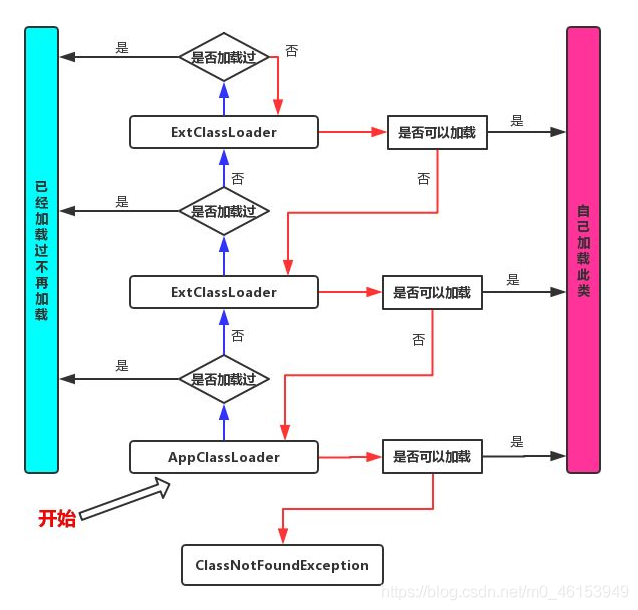
作用
- 为了防止重复加载同一个.class。通过委托去向上面问一问,加载过了,就不用再加载一遍了。保证数据的安全。
- 保证核心.class不能被篡改。通过委托方式,不会去篡改核心.class,即使篡改了也不会去加载,即使加载也不会是同一个.class对象了。不同的加载器加载同一个.class也不是同一个Class对象。这样就保证了Class的安全执行
比如:如果有人想替换系统级别的类:String.java。篡改它的实现,在这种机制下这些系统的类已经被Bootstrap classLoader加载过了(为什么?因为当一个类需要加载的时候,最先去尝试加载的就是BootstrapClassLoader),所以其他类加载器并没有机会再去加载,从一定程度上防止了危险代码的植入。
沙箱安全机制
概述
Java安全模式的核心就是Java沙箱(sandbox)
什么是沙箱
沙箱是一个限制程序运行的环境。沙箱机制就是 将Java代码限定在虚拟机(JVM)特定的运行范围中,并且严格限制代码对本地系统资源的访问。
通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。
沙箱主要限制系统资源访问,那系统资源包括什么?
CPU、内存、文件系统、网络。不同级别的沙箱对这些资源访问的限制也可以不一样。
所有的Java程序运行都可以指定沙箱,可以定制安全策略。
历史
在Java中将执行的程序分成本地代码和远程代码两种。
-
本地代码默认可信任的,远程代码则被看做是不受信任的。对于授信的本地代码,可以访问一切本地资源。
-
而对于非授信的远程代码在早期的Java实现中,安全依赖于沙箱 Sandbox 机制。如下图所示JDK1.0安全模型
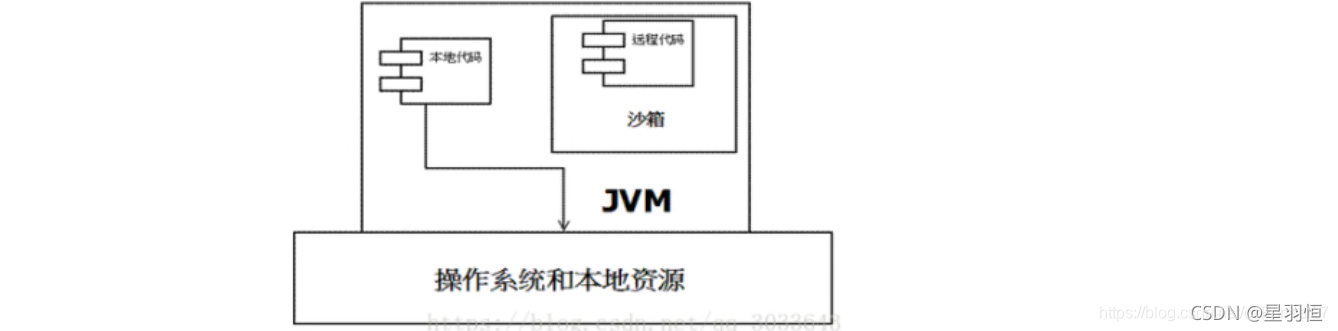
-
但如此严格的安全机制也给程序的功能扩展带来障碍,比如当用户希望远程代码访问本地系统的文件时候,就无法实现。
-
因此在后续的Java1.1版本中,针对安全机制做了改进,增加了安全策略,允许用户指定代码对本地资源的访问权限。
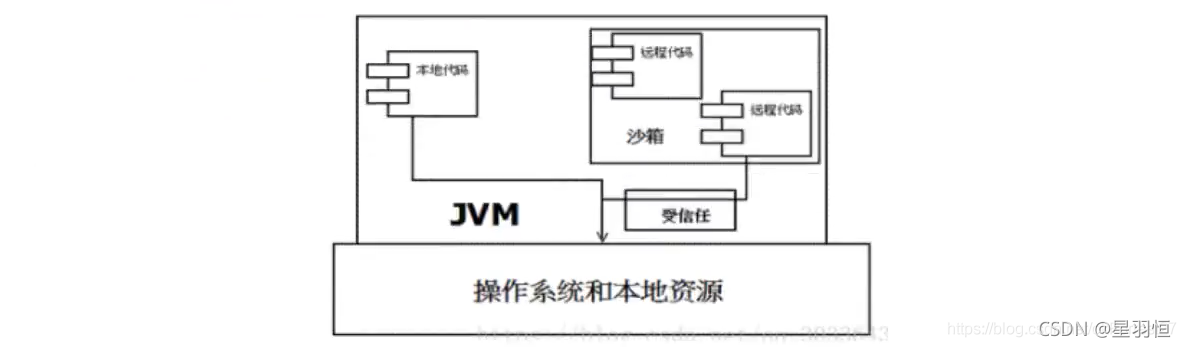
-
在Java1.2版本中,再次改进了安全机制,增加了代码签名。
-
不论本地代码或是远程代码,都会按照用户的安全策略设定,
-
由类加载器加载到虚拟机中权限不同的运行空间,来实现差异化的代码执行权限控制。
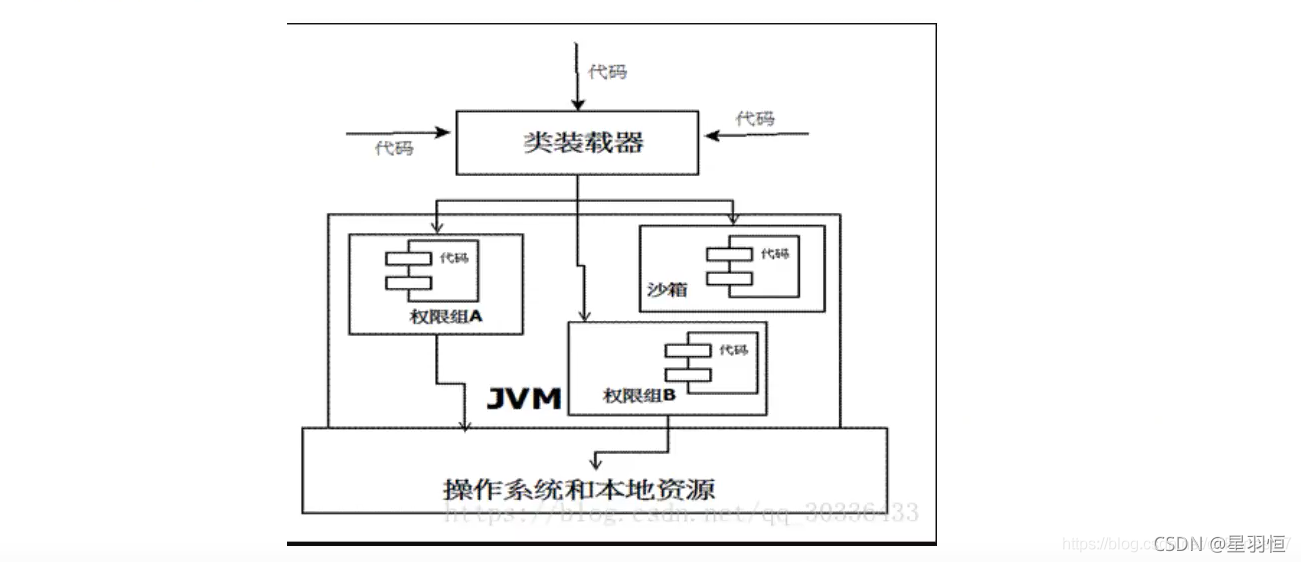
-
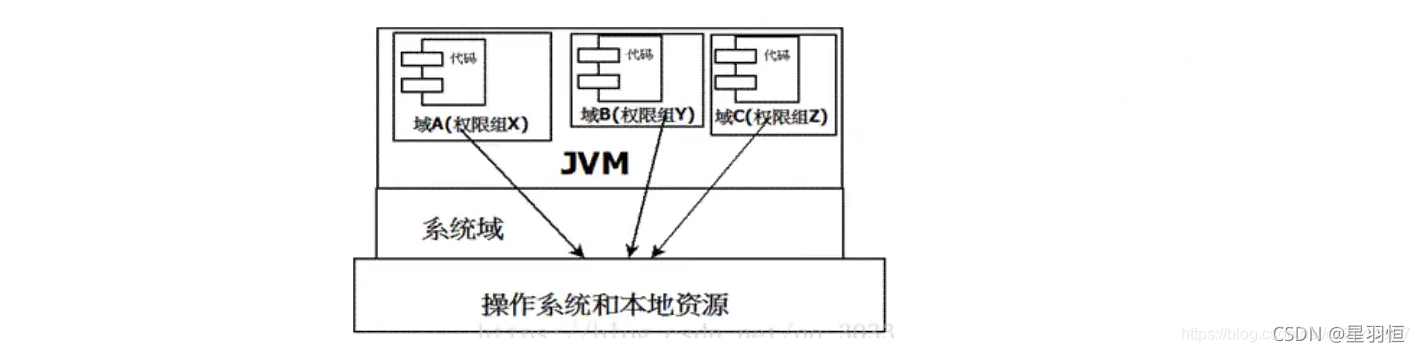
当前最新的安全机制实现,则引入了 域(Domain) 的概念。
-
虚拟机会把所有代码加载到不同的系统域和应用域,系统域部分专门负责域关键资源进行交互,而各个应用域部分则通过系统域的部分代理来对各种需要的资源进行访问。
-
虚拟机中不同的受保护域(Protected Domain),对应不一样的权限(Permission)。
-
存在于不同域中的类文件就具有了当前域的全部权限,
下图所示为最新的安全模型(jdk 1.6)
组成沙箱的基本组件
字节码校验器(bytecode verifier)
- 确保Java类文件遵循Java语言规范。这样可以帮助Java程序实现内存保护。
- 但并不是所有的类文件都会经过字节码校验,比如核心类。如:new String();
类裝载器(class loader) :
- 其中类装载器在3个方面对Java沙箱起作用
- 它防止恶意代码去干涉善意的代码;
- 它守护了被信任的类库边界;
- 它将代码归入保护域,确定了代码可以进行哪些操作。
- 虚拟机为不同的类加载器载入的类提供不同的命名空间。
- 命名空间由一系列唯一的名称组成, 每一个被装载的类将有一个名字,
- 这个命名空间是由Java虚拟机为每一个类装载器维护的,它们互相之间甚至不可见。
- 类装载器采用的机制是双亲委派模式
- 从最内层JVM自带类加载器开始加载,外层恶意同名类得不到加载从而无法使用;
- 由于严格通过包来区分了访问域,外层恶意的类通过内置代码也无法获得权限访问到内层类,破坏代码就自然无法生效。
- 存取控制器(access controller) :存取控制器可以控制核心API对操作系统的存取权限,而这个控制的策略设定,可以由用户指定。
- 安全管理器(security manager) : 是核心API和操作系统之间的主要接口。实现权限控制,比存取控制器优先级高。
- 安全软件包(security package) : java.security下的类和扩展包下的类,允许用户为自己的应用增加新的安全特性,包括:
- 安全提供者
- 消息摘要
- 数字签名
- 加密
- 鉴别
Native、本地方法栈
概述
凡是带了native关键字的,说明java的作用范围达不到了,会去调用底层C语言的库; 会进入本地方法栈,然后通过本地接口(JNI)( Java Native Interface ),调用本地方法库。
JNI作用:开拓Java的使用,融合不同的编程语言为Java所用,Java诞生的时候C、C++横行,想要立足,必须要有调用C、C++的程序。
它在内存区域中专门开辟了一块标记区域: Native Method Stack,登记native方法
在最终执行的时候,通过本地接口 (JNI),加载本地方法库中的方法
如private native void start0();
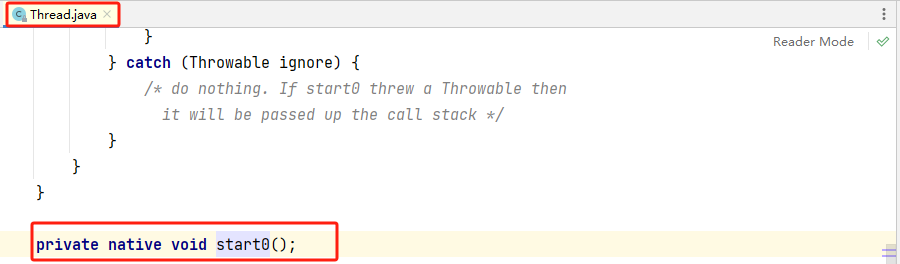
原理图:
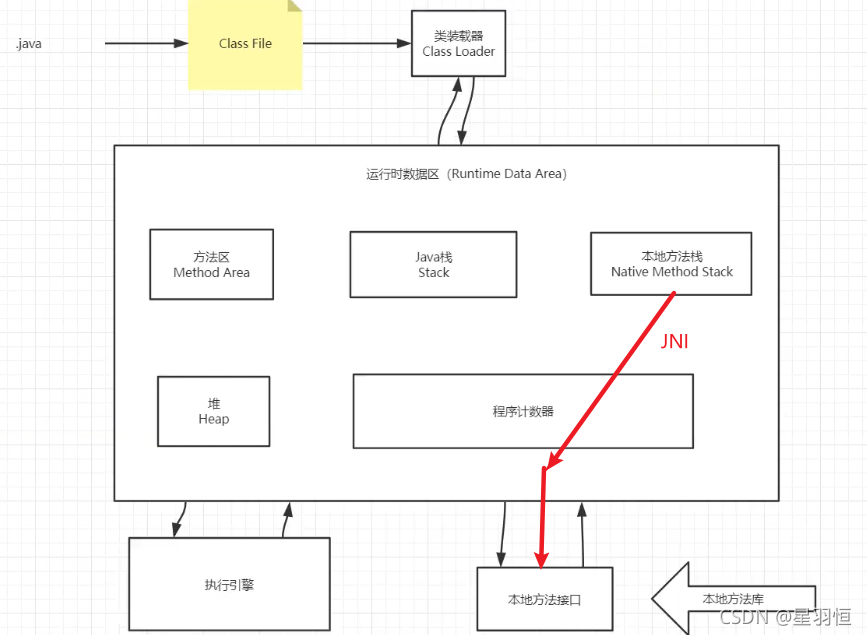
Method Stack & JNI
本地方法栈
本地方法栈(Native Method Stack)
它的具体做法是 Native Method Stack 中登记 native方法,
在执行引擎执行的时候通过本地接口 (JNI),加载本地方法库(Native Libraies)。
本地接口
本地接口JNI(Native Interface)
本地接口的作用是融合不同的编程语言为Java所用,它的初衷是融合C/C++程序,Java在诞生的时候是C/C++横行的时候,想要立足,必须有调用C、C++的程序,于是就在内存中专门开辟了一块区域处理标记为native的代码,它的具体做法是 在 Native Method Stack 中登记native方法,在 ( ExecutionEngine ) 执行引擎执行的时候加载Native Libraies。
目前该方法使用的越来越少了,除非是与硬件有关的应用,比如通过Java程序驱动打印机或者Java系统管理生产设备,在企业级应用中已经比较少见。因为现在的异构领域间通信很发达,比如可以使用Socket通信,也可以使用Web Service等等,不多做介绍!
PC寄存器
程序计数器:Program Counter Register
每个线程都有一个程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码(用来存储指向像一条指令的地址,也即将要执行的指令代码),在执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不计。
方法区
下面的图示没有代码,不太准确

方法区存放被所有线程共享的所有字段和方法字节码,以及一些特殊的方法,如构造函数、接口代码也在此定义。简单说,所有定义的方法的信息都保存在此区域,此区域属于共享区间。
重点:静态变量、常量、类信息(构造方法、接口定义)、运行时的常量池存在方法区中,但是实例变量和数组的内容存在堆中内存中,和方法区无关。
简单点说:方法区就存:static final Class信息 运行时常量池
方法区存放的实例图
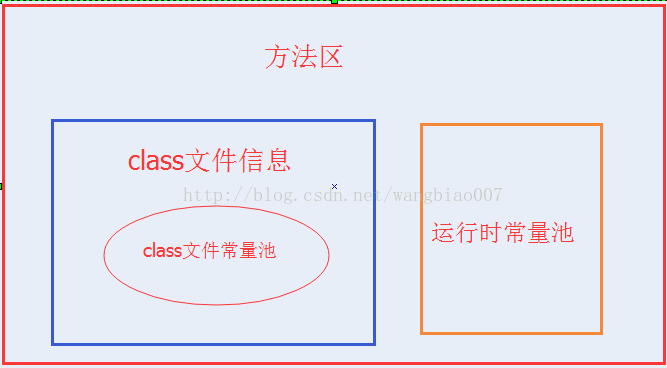
方法区分类
方法区分类:方法区里存储着class文件的信息和动态常量池,class文件的信息包括类信息和静态常量池。
常量池
参考网站:https://blog.csdn.net/weixin_42679575/article/details/128021153
参考网站:https://baijiahao.baidu.com/s?id=1767025926654459345&wfr=spider&for=pc
参考网站:https://zhuanlan.zhihu.com/p/351226127
常量池分类
常量池分类:常量池分为静态常量池(class文件常量池)和 动态常量池(运行时常量池)。
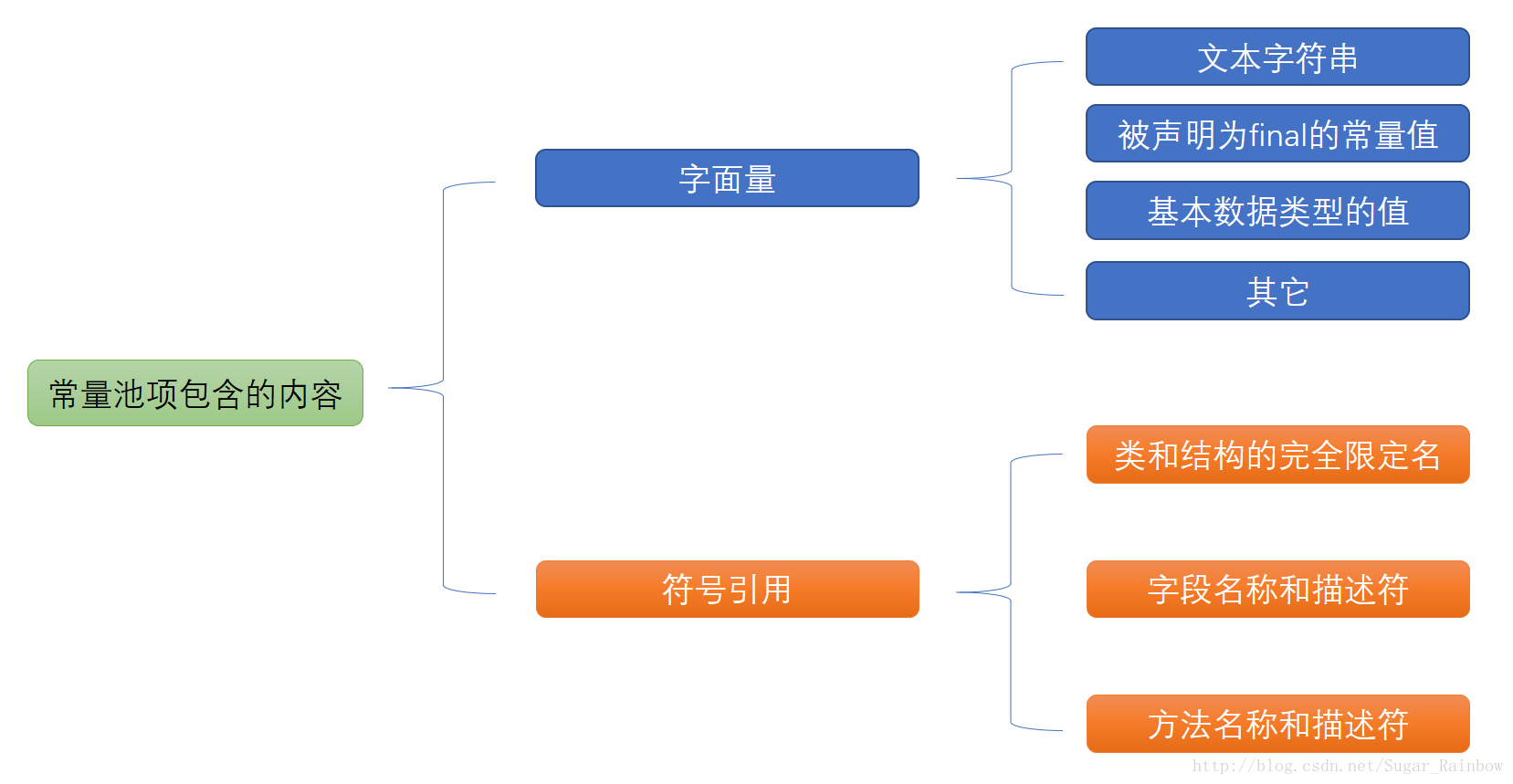
静态常量池和动态常量池的关系以及区别
静态常量池存储的是当class文件被java虚拟机加载进来后存放在方法区的一些字面量和符号引用,字面量包括字符串和基本类型能够直接确定值得量,符号引用其实引用的就是常量池里面的字符串,但字符引用不是直接存储字符串,而是存储字符串在常量池里的索引。
动态常量池是当class文件被加载完成后,java虚拟机会将静态常量池的内容转移到动态常量池里
运行时常量池中包含多种不同的常量,包括编译期就已经明确的数值字面量,也包括到运行期解析后才能够获得的方法或者字段引用。此时不再是常量池中的符号地址了,这里换为真实地址。例如调用String的intern方法就能将string的值添加到String常量池中,这里String常量池是包含在动态常量池里的,但在jdk1.8后,将String常量池放到了堆中。
使用常量池的好处
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
- 节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
- 节省运行时间:比较字符串时,比equals()快。对于两个引用变量,只用判断引用是否相等,也就可以判断实际值是否相等。
搬一下大神博客中的例子
String的intern方法
这个方法首先在常量池中查找是否存在一份equals相等的字符串,如果有的话就返回该字符串的引用,没有的话就将它加入到字符串常量池中,所以存在于class中的常量池并非固定不变的,可以用intern方法加入新的。
字符串常量池
最流行的、最典型的就是字符串了
典型范例:
String a = "abc";
String b = new String("abc");
System.out.println(a == b);
----*----
结果:false
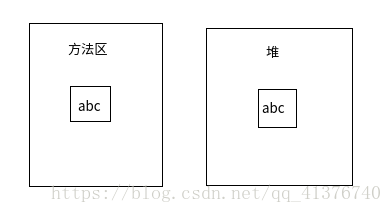
这个是第一个需要理解的地方,a指向哪片内存,b又指向哪片内存呢?对象储存在堆中,这个是不用质疑的,而a作为字面量一开始储存在了class文件中,之后运行期,转存至方法区中。它们两个就不是同一个地方存储的。知道了它之后我们就可以通过实例直接进一步了解了。
实例
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8;
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true
分析:
- s1 = = s2 很容易可以判断出来。s1 和 s2 都指向了方法区常量池中的Hello。
- s1 = = s3 这里要注意一下,因为做+号的时候,会进行优化,自动生成Hello赋值给s3,所以也是true
- s1 = = s4 s4是分别用了常量池中的字符串和存放对象的堆中的字符串,做+的时候会进行动态调用,最后生成的仍然是一个String对象存放在堆中。
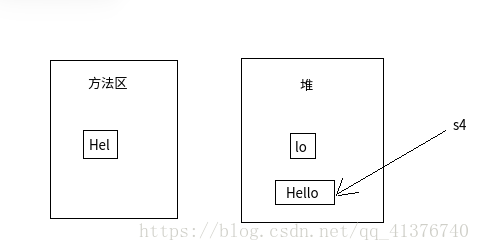
s1 = = s9在JAVA9中,因为用的是动态调用,所以返回的是一个新的String对象。所以s9和s4,s5这三者都不是指向同一块内存- s1 = = s6 为啥s1 和 s6地址相等呢? 归功于intern方法,这个方法首先在常量池中查找是否存在一份equal相等的字符串如果有的话就返回该字符串的引用,没有的话就将它加入到字符串常量池中,所以存在于class中的常量池并非固定不变的,可以用intern方法加入新的。
结论:
-
只有使用引号包含文本的方式创建的String对象之间使用“+”连接产生的新对象才会被加入字符串池中。
-
对于所有包含new方式新建对象(包括null)的“+”连接表达式,它所产生的新对象都不会被加入字符串池中。
需要注意的特例
1、常量拼接
public static final String a = "123";
public static final String b = "456";
public static void main(String[] args)
{
String c = "123456";
String d = a + b;
System.out.println(c == d);
}
------反编译结果-------
0: ldc #2 // String 123456
2: astore_1
3: ldc #2 // String 123456
5: astore_2
6: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;
我们可以发现,对于final类型的常量它们已经在编译中被确定下来,自动执行了+号,把它们拼接了起来,所以就相当于直接”123” + “456”;
A和B都是常量,值是固定的,因此s的值也是固定的,它在类被编译时就已经确定了。也就是说:String d = a + b;等同于:String d=”123”+”456”;
2、static 静态代码块
public static final String a;
public static final String b;
static {
a = "123";
b = "456";
}
public static void main(String[] args)
{
String c = "123456";
String d = a + b;
System.out.println(c == d);
}
------反编译结果-------
3: getstatic #3 // Field a:Ljava/lang/String;
6: getstatic #4 // Field b:Ljava/lang/String;
9: invokedynamic #5, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
上个例子是在编译期间,就已经确定了a和b,但是在这段代码中,编译期static不执行的,a和b的值是未知的,static代码块,在初始化的时候被执行,初始化属于类加载的一部分,属于运行期。看看反编译的结果,很明显使用的是indy指令,动态调用返回String类型对象。一个在堆中一个在方法区常量池中,自然是不一样的。
包装类的常量池技术(缓存)
简单介绍
相信学过java的同学都知道自动装箱和自动拆箱,自动装箱常见的就是valueOf这个方法,自动拆箱就是intValue方法。在它们的源码中有一段神秘的代码值得我们好好看看。除了两个包装类Float和Double 没有实现这个缓存技术,其它的包装类均实现了它。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
分析:我们可以看到从-128~127的数全部被自动加入到了常量池里面,意味着这个段的数使用的常量值的地址都是一样的。一个简单的实例
Integer i1 = 40;
Integer i2 = 40;
Double i3 = 40.0;
Double i4 = 40.0;
System.out.println("i1=i2 " + (i1 == i2));
System.out.println("i3=i4 " + (i3 == i4));
-----结果----
true
false
原理如下:
-
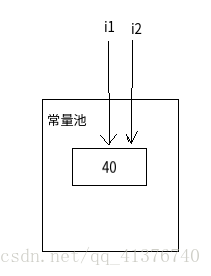
== 这个运算在不出现算数运算符的情况下 不会自动拆箱,所以i1 和 i 2它们不是数值进行的比较,仍然是比较 地址是否指向同一块内存
-
它们都在常量池中存储着,类似于这样
-
编译阶段已经将代码转变成了调用valueOf方法,使用的是常量池,如果超过了范围则创建新的对象
Integer i1=40;Java在编译的时候会直接将代码封装成Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
复杂实例[-128~127]
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
System.out.println("i1=i2 " + (i1 == i2));
System.out.println("i1=i2+i3 " + (i1 == i2 + i3));
System.out.println("i1=i4 " + (i1 == i4));
System.out.println("i4=i5 " + (i4 == i5));
System.out.println("i4=i5+i6 " + (i4 == i5 + i6));
System.out.println("40=i5+i6 " + (40 == i5 + i6));
----结果----
(1)i1=i2 true
(2)i1=i2+i3 true
(3)i1=i4 false
(4)i4=i5 false
(5)i4=i5+i6 true
(6)40=i5+i6 true
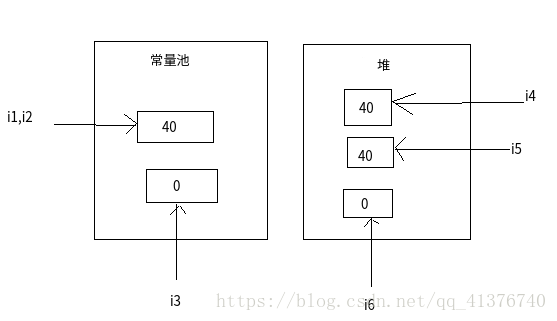
它们的内存分布大概如下
注意点:
1、当出现运算符的时候,Integer不可能直接用来运算,所以会进行一次拆箱成为基本数字进行比较
2、==这个符号,既可以比较普通基本类型,也可以比较内存地址看比较的是什么了
分析:
- (1)号成立不用多说
- (2)号成立是因为运算符自动拆箱
- (3)(4)号是因为内存地址不同
- (5)(6)号都是自动拆箱的结果
PS:equals方法比较的时候不会处理数据之间的转型,比如Double类型和Integer类型。
解释: 语句i4 == i5 + i6,因为+这个操作符不适用于Integer对象,首先i5和i6进行自动拆箱操作,进行数值相加,即i4 == 40。然后Integer对象无法与数值进行直接比较,所以i4自动拆箱转为int值40,最终这条语句转为40 == 40进行数值比较。
超过范围
假设一下,如果超出了这个范围之后呢?正如前文所言,所有的都将成为新的对象
Integer i1 = 400;
Integer i2 = 400;
Integer i3 = 0;
Integer i4 = new Integer(400);
Integer i5 = new Integer(400);
Integer i6 = new Integer(0);
Integer i7 = 1;
Integer i8 = 2;
Integer i9 = 3;
System.out.println("i1=i2 " + (i1 == i2));
System.out.println("i1=i2+i3 " + (i1 == i2 + i3));
System.out.println("i1=i4 " + (i1 == i4));
System.out.println("i4=i5 " + (i4 == i5));
System.out.println("i4=i5+i6 " + (i4 == i5 + i6));
System.out.println("400=i5+i6 " + (400 == i5 + i6));
----结果----
i1=i2 false
i1=i2+i3 true
i1=i4 false
i4=i5 false
i4=i5+i6 true
400=i5+i6 true
栈(Stack)
概述
- 在计算机流传有一句废话: 程序 = 算法 + 数据结构
- 但是对于大部分同学都是: 程序 = 框架 + 业务逻辑
- 栈:后进先出 / 先进后出
- 队列:先进先出(FIFO : First Input First Output)
栈管理程序运行
- 存储一些基本类型的值、对象的引用、方法等
- 栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。
为什么 main 方法最先执行,但最后结束?——栈

说明:
- 栈也叫栈内存,主管Java程序的运行,是在线程创建的时创建,它的生命周期是跟随线程的生命周期,线程结束栈内存也就释放了。
- 对于栈来说不存在垃圾回收问题,只要线程一旦结束,该栈就Over,生命周期和线程一致,是线程私有的。
- 方法自己调用自己就会导致栈溢出(递归死循环测试)。
栈里面会放什么?
8大基本类型 + 对象的引用 + 方法
栈的运行原理
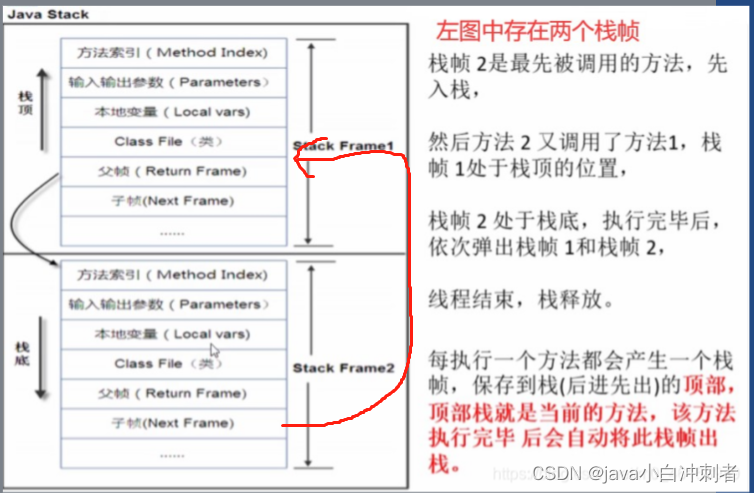
Java栈的组成元素------栈帧。
栈帧:是一种用于帮助虚拟机执行方法调用于方法执行的数据结构。他是独立于线程的,一个线程有自己的一个栈帧。封装了方法的局部变量表,动态链接信息、方法的返回地址以及操作数栈等信息。
第一个方法从调用开始到执行完成,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
当一个方法A被调用时就产生了一个栈帧F1,并被压入到栈中,A方法又调用了B方法,于是产生了栈帧F2也被压入栈中,B方法又调用了C方法,于是产生栈帧F3也被压入栈中 执行完毕后,先弹出F3, 然后弹出F2,在弹出F1........
遵循“先进后出” / “后进先出” 的原则。
栈满了,抛出异常:stackOverflowError
11.三种JVM
- Sun公司的Hotspot™64-Bit server vw (build 25.181-b13,mixed mode)
- BEA JRockit
- IBM J9 VM
我们都是学的Hotspot
堆
概述
一个JVM仅有一个堆内存,堆内存大小可以调节
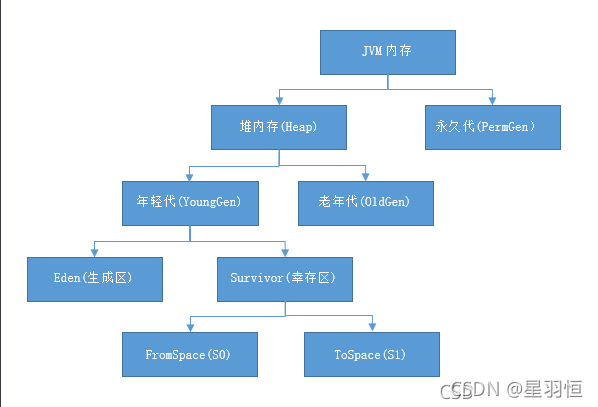
JVM内存划分为堆内存和非堆内存
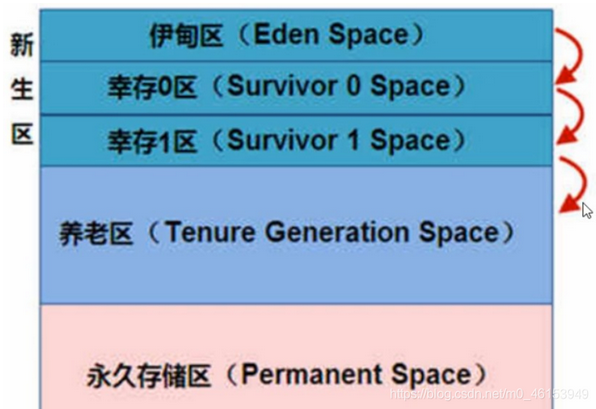
- 堆内存分为年轻代(Young Generation)、老年代(Old Generation),
- 非堆内存就一个永久代(Permanent Generation)。(这个非堆,严格意义上来说也是堆,但逻辑操作上又不是堆…)
年轻代分为Eden和Survivor区
-
Eden区占大容量,Survivor两个区占小容量,默认比例是8:1:1
-
Survivor区由FromSpace和ToSpace组成。(谁空谁是to)
老年代:
- 在新生代中经历了多次(默认是15次,具体看虚拟机配置的阀值)GC后仍然存活下来的对象会进入老年代中
- 老年代中的对象生命周期较长,存活率比较高
- 在老年代中进行GC的频率相对而言较低,而且回收的速度也比较慢
堆内存:
- 存放的是对象,垃圾收集器就是收集这些对象,然后根据GC算法回收
非堆内存
- 永久代(jdk1.8后被元空间代替),元空间是方法区的实现,存储类信息、常量、静态变量、即时编译器编译后的代码等数据,对这一区域而言,Java虚拟机规范指出可以不进行垃圾收集,一般而言不会进行垃圾回收。
垃圾回收过程
新生成的对象首先放到年轻代Eden区,当Eden空间满了,出发Minor GC,存活下来的对象移动到Survivor0区,Survivor0区满后触发执行Minor GC,Survivor0区存活对象移动到Suvivor1区,这样保证了一段时间内总有一个survivor区为空。经过多次Minor GC仍然存活的对象移动到老年代。
老年代存储长期存活的对象,占满时会触发Major GC=Full GC,GC期间会停止所有线程等待GC完成,所以对响应要求高的应用尽量减少发生Major GC,避免响应超时。
Minor GC : 清理年轻代
Major GC(Full GC): 清理整个堆空间(年轻代和老年代),目前不确定是否清理永久代,停止所有线程等待GC完成
若养老区执行了Full GC后依然无法进行对象的保存,就会产生OOM异常 “OutOfMemoryError ”。说明Java虚拟机的堆内存不够,原因如下:
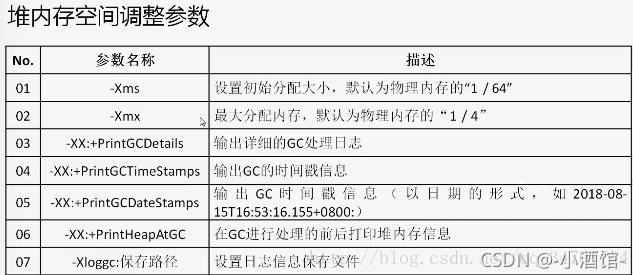
- 1、Java虚拟机的堆内存设置不够,可以通过参数 -Xms(初始值大小),-Xmx(最大大小)来调整。
- 2、代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)或者死循环。
真理:经过研究,99%的对象都是临时对象
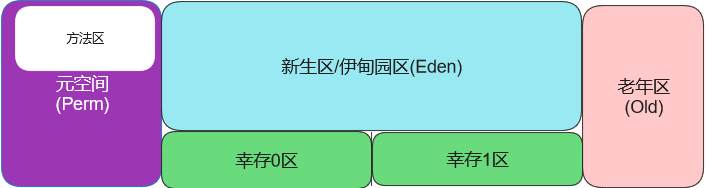
元空间
在JDK1.8版本废弃了永久代,替代的是元空间(MetaSpace),元空间与永久代上类似,都是方法区的实现,他们最大区别就是:元空间并不在JVM中,而是使用本地内存。
元空间注意有两个参数:
- MetaspaceSize :初始化元空间大小,控制发生GC阈值
- MaxMetaspaceSize : 限制元空间大小上限,防止异常占用过多物理内存
内存结构图:
修改虚拟机内存
查看虚拟机内存
以我的电脑为例,本电脑的内存是16GB.
public static void main(String[] args) {
// 返回虚拟机试图使用的最大内存
long max = Runtime.getRuntime().maxMemory();
// 返回虚拟机的初始化总内存
long total = Runtime.getRuntime().totalMemory();
System.out.println("虚拟机试图使用的最大内存"+max/1024/1024+"MB");
System.out.println("虚拟机的初始化总内存"+total/1024/1024+"MB");
}
打印结果:
虚拟机试图使用的最大内存3618MB
虚拟机的初始化总内存245MB
可以看到
虚拟机试图使用的最大内存约占电脑总内存的1/4
虚拟机的初始化总内存约占电脑总内存的1/64
修改虚拟机内存
操作
在idea中点击编辑配置
点击替换配置
选择
编辑虚拟机内存
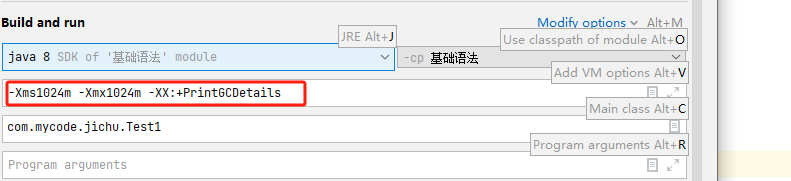
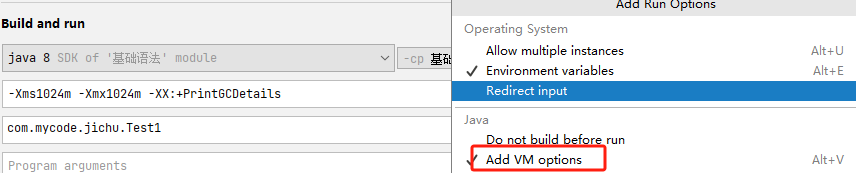
-Xms1024m -Xmx1024m -XX:+PrintGCDetails
执行代码

查看打印
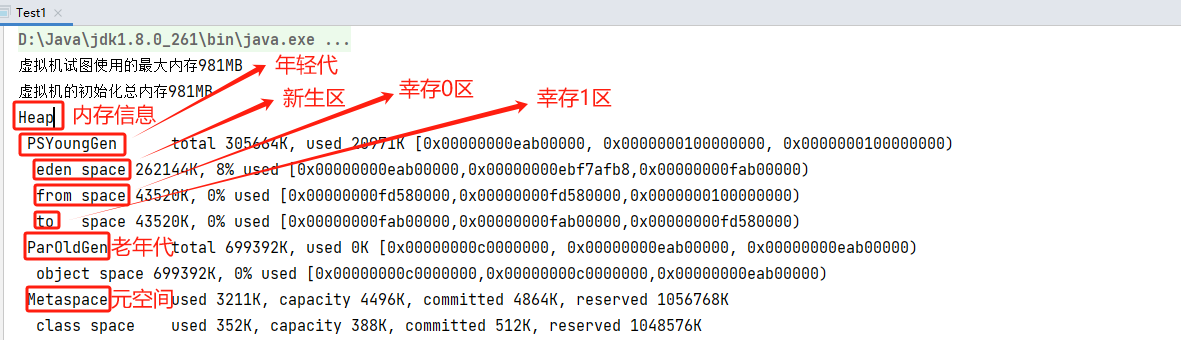
分析
年轻代:305664kb
老年代:699392kb
(305664+699392)/1024=981.5MB
通过打印的信息,我们知道。年轻代(新生区、幸存区)和老年代的内存通过计算一共是981.5MB,和虚拟机的内存几乎一样。这就说明虚拟机的内存大部分是被堆内存占用,元空间只是逻辑上存在于堆中,但是实际上用的是本地的内存(并不属于堆内存)。
测试OOM错误
OOM:OutMemoryError
1、将虚拟机的试图使用的最大内存和初始化总内存修改为8MB
2、执行下面的代码
3、查看打印信息
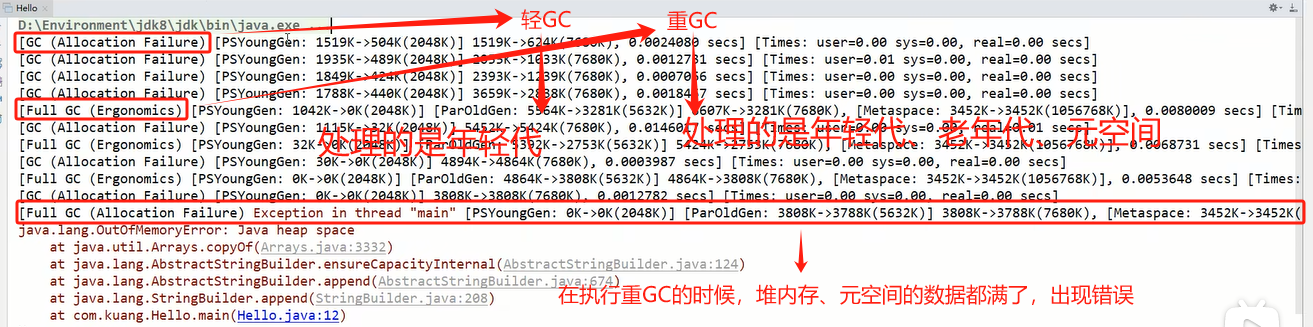
所以出现OOM错误,首先修改jvm内存,没有解决,检查代码,可能出现死循环...
堆内存调优
分析
堆空间具体划分
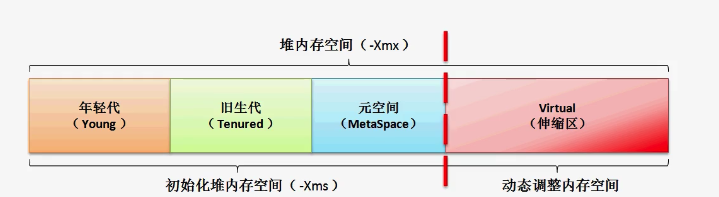
可以在idea的编辑设置上进行指定
JPofiler工具分析OOM
作用
- 分析Dump内存文件,快速定位内存泄露;
- 获得堆中的数据
- 获得大的对象~
使用
下载
下载插件
在idea中下载jprofile插件,下载之后重启idea
下载客户端
我实际使用的是jprofile9.2.1版本,客户端安装笔记使用的是14和9.2.1版相结合,安装过程几乎一样。
网站:https://www.ej-technologies.com/download/jprofiler/files
下载jprofile客户端
下载完之后进行安装
自定义安装
接收
自己选择安装目录
选择电脑的系统版本
创建桌面的快捷方式
默认即可,下一步
等待安装完毕即可
选择输入许可证密钥
输入许可证密钥
许可证密钥:
L-Larry_Lau@163.com#23874-hrwpdp1sh1wrn#0620
L-Larry_Lau@163.com#36573-fdkscp15axjj6#25257
L-Larny_Lau@163.com#5481-ucjn4a16rvd98#6038
L-Larry_Lau@163.com#99016-hli5ay1ylizjj#27215
L-Larry Lau@163.com#40775-3wle0g1uin5c1#0674
这里让选择一个idea版本,因为我的版本是21,匹配不上就选个16版的
选择yes
是否检查更新,从不。因为更新烦
先不要运行,安装完毕,finish
idea配置jprofile插件
指定路径
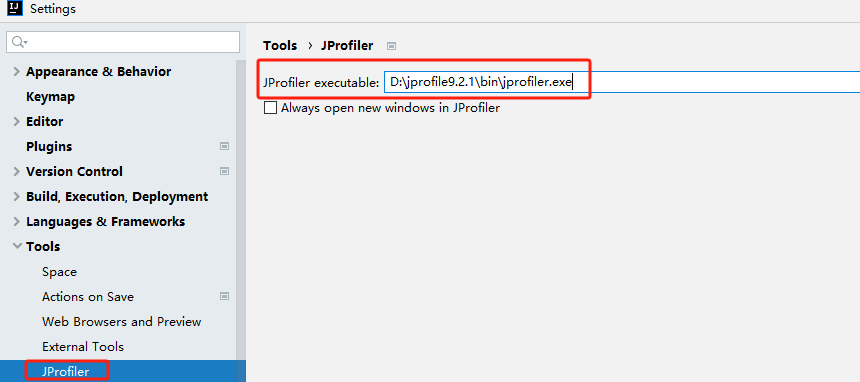
测试
修改虚拟机参数
-Xms1m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
-Xms:设置初始化内存分配大小 1/64
-Xmx:设置试图使用最大内存 1/4
-XX:+PrintGCDetails:打印GC垃圾回收信息
-XX:+HeapDumpOnOutOfMemoryError:如果出现OOM异常,则生成dump文件
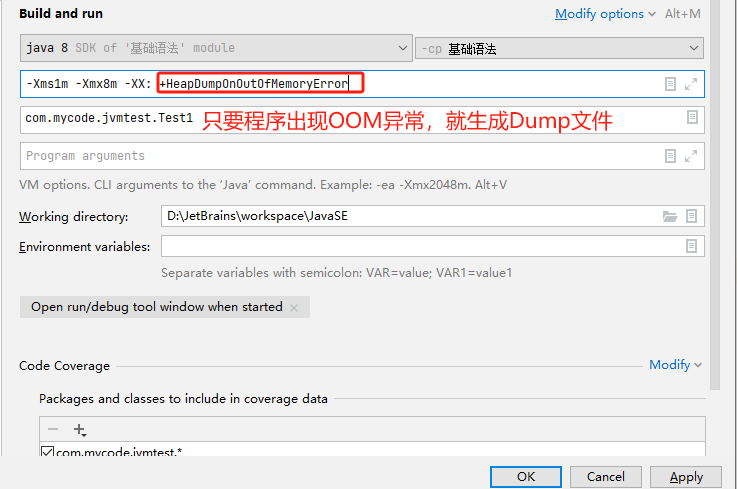
运行下面的代码
public class TestJvm {
// 1M = 1024K
byte[] byteArray = new byte[1*1024*1024];
public static void main(String[] args) {
ArrayList<TestJvm> list = new ArrayList<>();
int count = 0;
try {
while (true) {
list.add(new TestJvm()); // 问题所在
count = count + 1;
}
} catch (Error e) {
System.out.println("count:" + count);
e.printStackTrace();
}
}
}
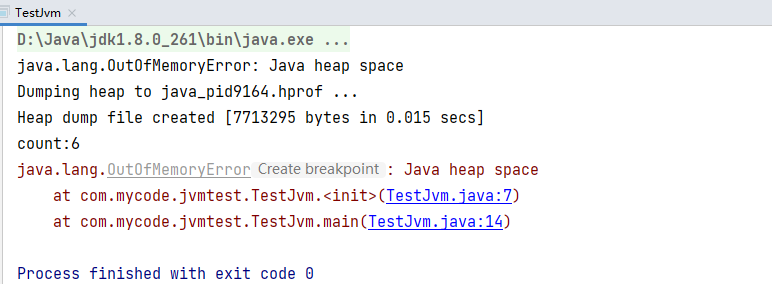
出现OOM异常
查看dump文件,打开当前类所在磁盘
在工程目录下得到这个文件
双击文件,默认使用的就是jprofile工具打开
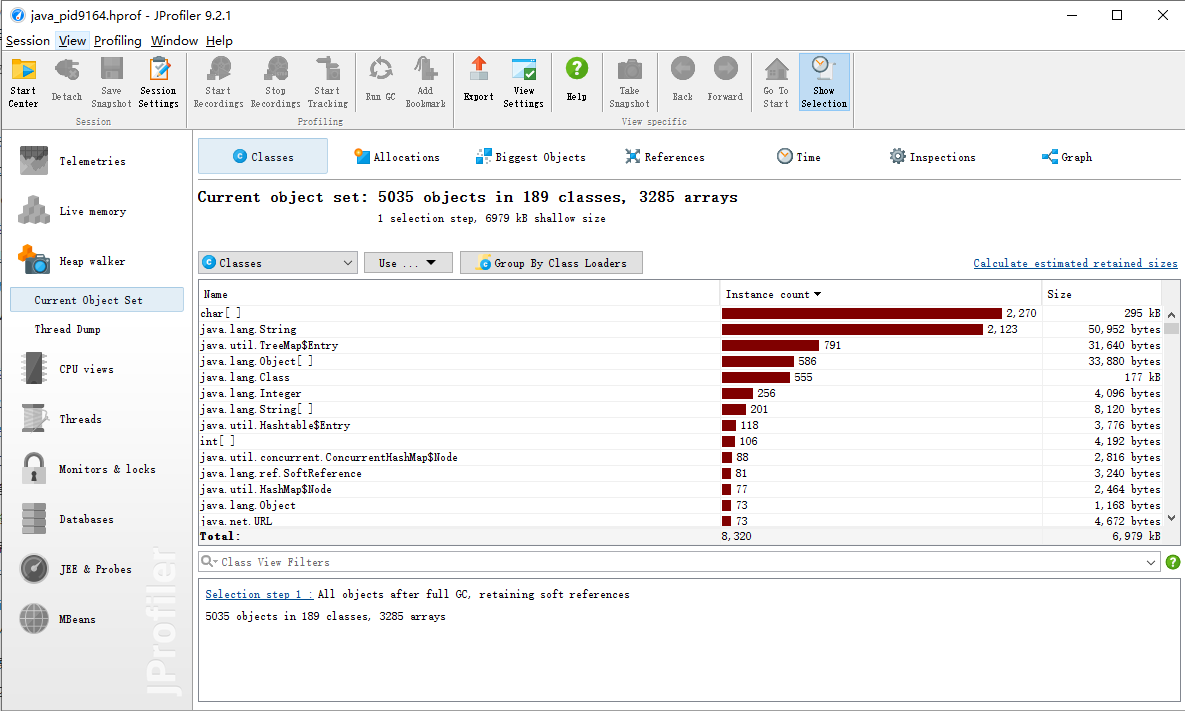
分析
可以看到这个对象出现问题
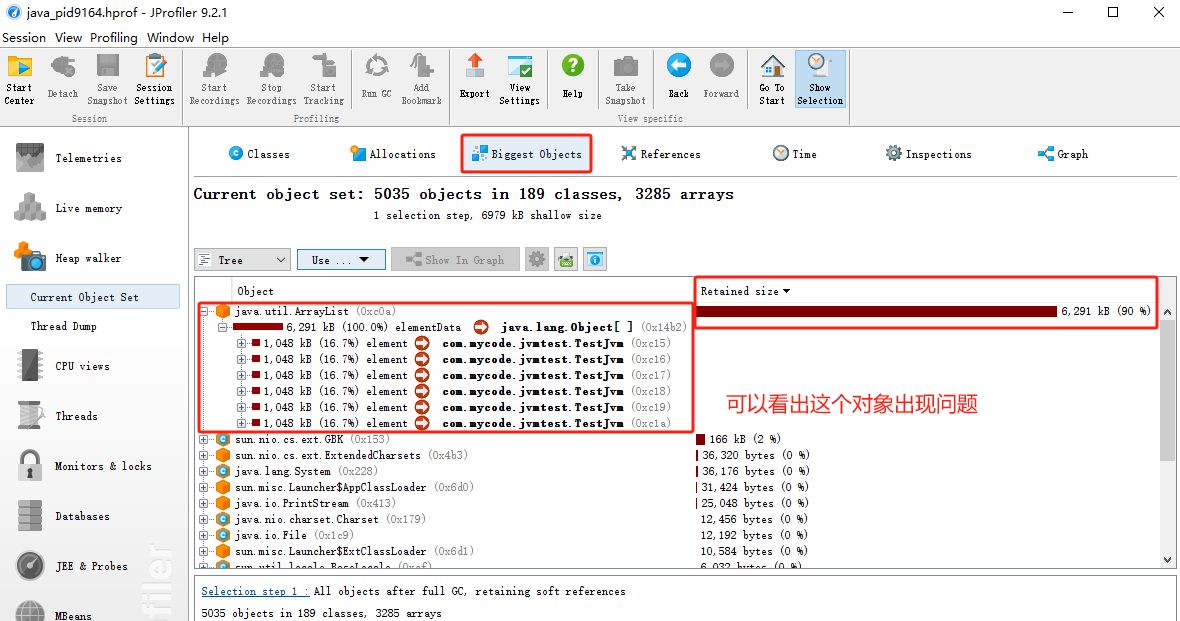
但是并不知道哪一行出现问题,接着往下看,通过线程定位到哪一行出现了问题
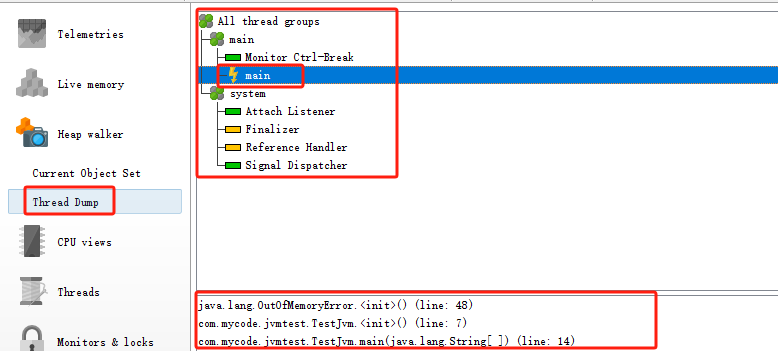
现在这个工具的使用应该是有点概念了,后续还要熟练使用
GC四大算法
引用计数法
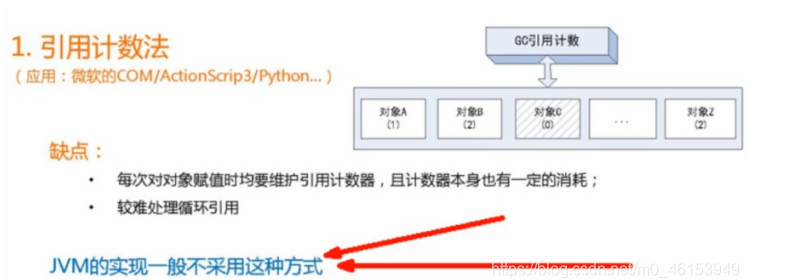
每个对象有一个引用计数器,当对象被引用一次则计数器加1,当对象引用失效一次,则计数器减1,对于计数器为0的对象意味着是垃圾对象,可以被GC回收。
目前虚拟机基本都是采用可达性算法,从GC Roots 作为起点开始搜索,那么整个连通图中的对象边都是活对象,对于GC Roots 无法到达的对象变成了垃圾回收对象,随时可被GC回收。
复制算法
年轻代中使用的是Minor GC(轻GC),采用的就是复制算法(Copying)。
什么是复制算法
Minor GC 会把Eden中的所有活的对象都移到Survivor区域中,如果Survivor区中放不下,那么剩下的活的对象就被移动到Old generation中,也就是说,一旦收集后,Eden就是变成空的了
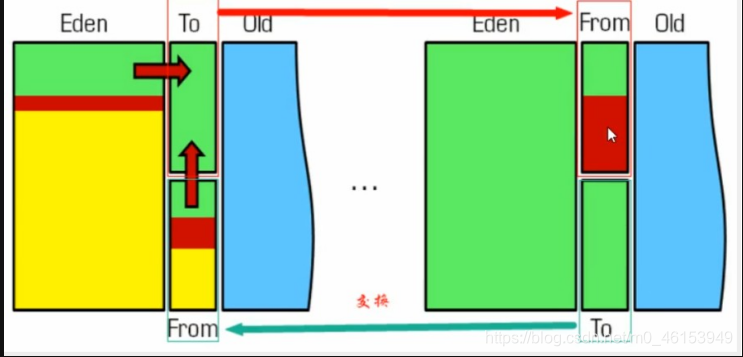
对象在Eden区域出生,在经过一次轻GC后,活着的对象经过复制算法进入Survivor to区域(to区),然后Survivor from区中被GC之后活着的对象也会被复制到Survivor to区,这样原Survivor from区因为没有任何对象就动态变成了to区,原to区动态变成了from区。Eden区的对象因为经历了一次GC,将他们的年龄设置1,以后对象在Survivor区,每熬过一次MinorGC,就将这个对象的年龄 + 1,当这个对象的年龄达到某一个值的时候(默认是15岁,通过- XX:MaxTenuringThreshold 设定参数)这些对象就会成为老年代。
-XX:MaxTenuringThreshold 任期门槛=>设置对象在新生代中存活的次数
面试题:如何判断哪个是to区呢?一句话:谁空谁是to
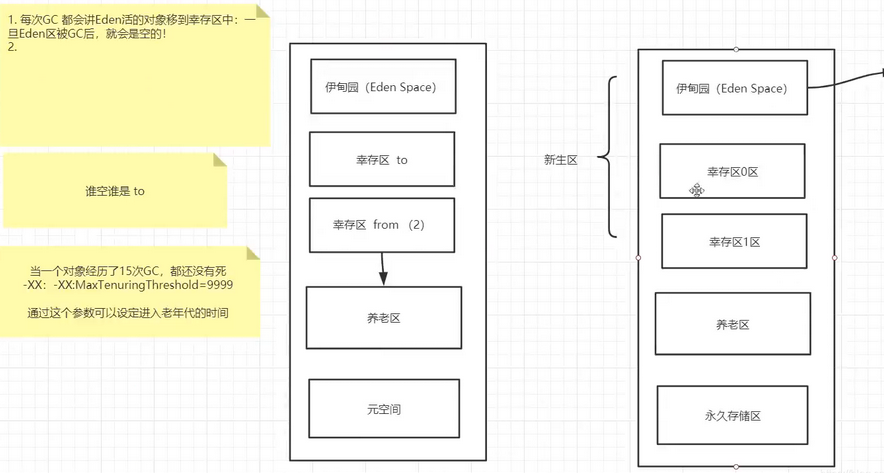
原因解释:
- 年轻代中的GC,主要是复制算法(Copying),因为年轻代对象存活率低
- HotSpot JVM 把年轻代分为了三部分:一个Eden区和2个Survivor区(from区和to区)。默认比例8:1:1,一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊处理),这些对象经过第一次Minor GC后,如果仍然存活,将会被移到Survivor区,对象在Survivor中每熬过一次Minor GC , 年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到年老代中,因为年轻代中的对象基本上 都是朝生夕死,所以在年轻代的垃圾回收算法使用的是复制算法!复制算法的思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。复制算法不会产生内存碎片!
优势:
没有内存碎片(数据在连续的内存空间存储就是没有内存碎片,不连续就是产生内存碎片)
劣势:
浪费了一半的内存,这太要命了。
如果对象的存活率很高,我们可以极端一点,假设是100%存活,那么我们需要将所有对象都复制一遍,并将所有引用地址重置一遍。复制这一工作所花费的时间,在对象存活率达到一定程度时,将会变的不可忽视,所以从以上描述不难看出。复制算法想要使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要客服50%的内存浪费。
标记清除算法
先标记:标记活着的对象
再清除:清除没有标记的对象
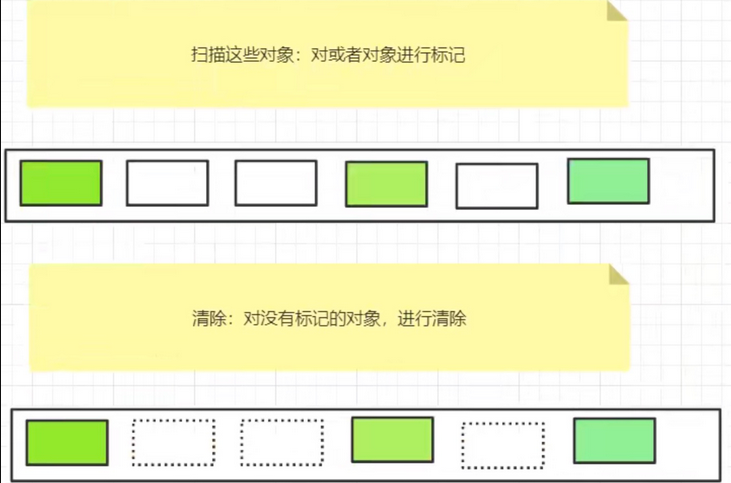
- 优点:不需要额外的空间。
- 缺点:两次扫描,严重浪费时间,会产生内存碎片。
标记清除压缩算法
先标记:
再清除:
后压缩:将活着的对象移动到内存的一端,防止内存碎片的产生
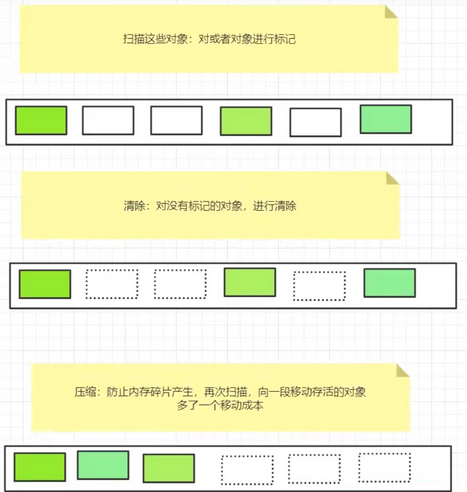
一般可以进行多次标记清除,再进行一次压缩。减少扫描次数
总结
内存效率:复制算法 > 标记清除算法 > 标记压缩算法(时间复杂度)
内存整齐度:复制算法 = 标记清除压缩算法 > 标记清除算法
内存利用率:标记压缩算法 = 标记清除算法 > 复制算法
思考一个问题:难道没有最优算法吗?
答案:没有,没有最好的算法,只有最合适的算法,所以GC也被称之为分代收集算法
年轻代:
- 存活率低
- 复制算法
老年代:
- 区域大:存活率高
- 标记清除(内存碎片太多)+标记压缩混合实现