加速比计算
100个处理器对于程序的并发而言,是100倍的加速。对于程序的顺序执行而言,是1倍的速度。

对于该题目,首先明确90倍的加速意味着什么:原始程序量为1,原始执行时间为1,现在加速了90倍,而程序本身不变,则:
原始的程序量为1,现在的执行时间是1/90。
现在假设x为并行执行的比例,则程序中,1-x为串行,x为并行。而程序之所以加速,是因为并行的部分,原始的串行部分执行时间是不被加速的,那么1/90的总时间是如通过如下方式得到的:
1/90 = 1-x + x/100
得到x= (89*100)/(90*99),得到1-x的值,小于0.1,顺序执行的比例小于0.1。
以下是原始答案

在MESI上增加O状态
原来的时候,M状态cacheline收到其它agent发起的读请求,当前agent需要将数据写回memory,状态清为invalid。
现在增加了状态O,M状态cacheline收到其它agent发起的读请求,当前agent需要将数据返回给其它agent,将M状态切换为O状态。这样降低和主存的交互,降低时间开销。
O状态表示存在共享,但是数据已经和主存不一致,感觉像是shared dirty(不知道对不对).
不要看其它非官方资料,主要是出版图书,amba手册、网上说的我感觉不太对劲。
block size对cache的命中率与选择
这里的block size指的是cacheline大小
cache的失效有三种,一般称为3C,强制失效、容量失效、冲突失效。
其中的冲突失效和关联度有关,因此和block size有关。
在cache中选用哪种block size,能降低命中率,表层看和访问的顺序有关,下表为一些列举启发。
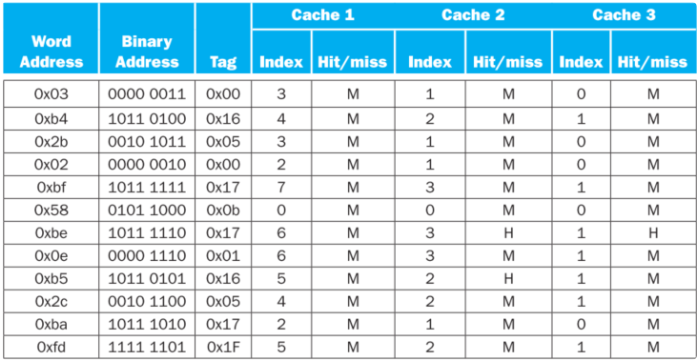
Block大小:Block大小与Cache大小有关,且不能太大,也不能太小!
https://cs.nju.edu.cn/swang/CompArchOrg_13F/slides/lecture13.pdf
另外一个制约block size的大小是soc层面的DDR burst length。需要确保DDR能进行这样的读取。
突发长度: DDR4 的BL为 8,与 DDR3 相同,允许一次从缓存中传输高达 16B 的数据。DDR5 将其增加到 16,并支持 32 长度模式,这意味着只使用一个 DIMM 就阔以获取高达 64 字节的缓存行。
https://blog.csdn.net/weixin_42238387/article/details/120382894
文中的DIMM是:Dual-Inline-Memory-Modules,物理接口。
https://blog.csdn.net/weixin_42050661/article/details/120266570
BBM和写时复制
break before make,一种通用的刷新页表的方法。在多个agent共享同一个页表的时候TLB的时候,如果某个agent要更新页表,那么需要先break掉(invalid掉),以通知其它agent无法再次使用tlb,否则其它agent仍然使用旧有的结果,将导致错误访问。
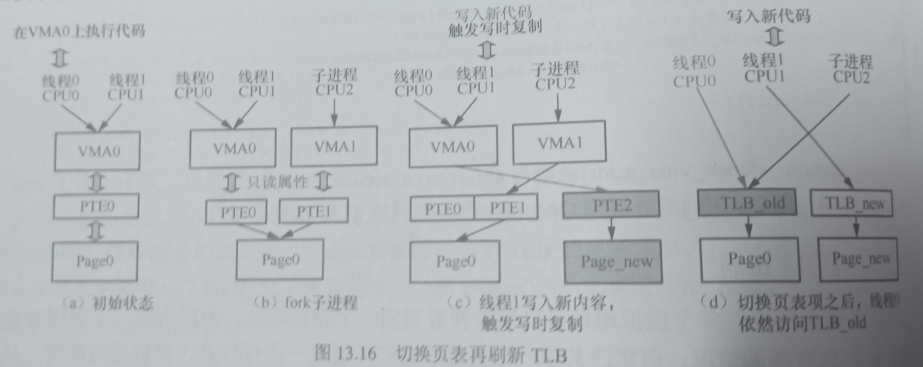
在linux中的页表更新时候用COW的方法实现页表更新,这基本是fork的常用策略。更新的过程本身是会复制一份旧有数据,在旧有数据上做更新。复制前,两个进程使用一套PTE;复制后,使用不同的PTE。
这本身是出于节约数据和安全的考虑,并不是上图中BBM的根本原因。而linux如果没有采用COW,一开始就以两块不同的空间,存储每个进程的相同数据,本身也是可以运行的,而BBM机制未使用的话,仍然出现错误访问。
写时复制:
https://cloud.tencent.com/developer/article/1914919
写时复制(Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
伪汇编和汇编嵌入
主要是查找就好,比如下述链接:
https://zhuanlan.zhihu.com/p/588075416
.type name, type_desc,定义符号的类型,如.type symbal, @function
.pushsection .name 将本伪操作之前对应的段设置保存,并设置成.name对应的section
在嵌入到C程序中,格式如下,这比直接用汇编要难:
https://baijiahao.baidu.com/s?id=1722268508697136684&wfr=spider&for=pc
int sum, add1=1, add2=2;
asm volatile("add %[dest], %[src1], %[src2]"
:[dest]"=r"(sum)
:[src1]"r"(add1), [src2]"r"(add2))
这里有一些例子,比如read_csrr的定义:
https://github.com/riscv/riscv-opcodes/blob/d752f193cec46cfd33300abba2a3a0d020c36755/encoding.h
注意#reg是在双引号外面。
#define read_csr(reg) ({ unsigned long __tmp; \
asm volatile ("csrr %0, " #reg : "=r"(__tmp)); \
__tmp; })
容易忘记的汉明码
其实只要记住1位纠错,2位检错。sbe,single bit error,dbe,double bit error。这就行了。
https://www.cnblogs.com/cherishui/p/4206257.html
位置1:校验1位,跳过1位,校验位数编号为:1,3,5,7,9,11,13,15,…
位置2:校验2位,跳过2位, 校验位数编号为:2,3, 6,7, 10,11, 14,15,…
位置4:校验4位,跳过4位, 校验位数编号为:4,5,6,7, 12,13,14,15, 20,21,22,23,…
位置8:校验8位,跳过8位,校验位数编号为: 8-15,24-31,40-47,…
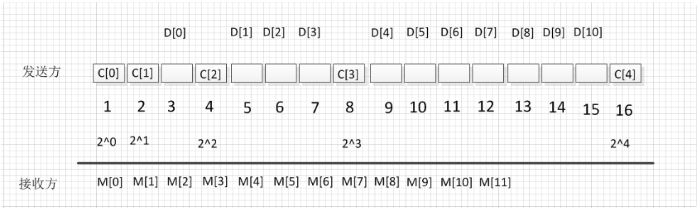
举例说明发送数据
一个字节的数据 1001_1010,按照上图所示,D[0]~D[7]填写对应数值,D[0]写1,D[1]写0….,需要计算得出4个校验位,根据上述原理可知:
C[0] = D[0] xor D[1] xor D[3] xor D[4] xor D[6] = 0
C[1] = D[0] xor D[2] xor D[3] xor D[5] xor D[6] = 1
C[2] = D[1] xor D[2] xor D[3] xor D[7] = 1
C[3] = D[4] xor D[5] xor D[6] xor D[7] = 0
最终排列出来的结果为: 011100101010 ,这个码字代表了8位真实码加上4位冗余码,可以自纠正一位错误。也就是说,在传输过程中,这列码字,无论哪一位出现位翻转,在接收端都可以被检测并且纠正回来。
在接收端收到此列数据
还是按照上述方法来计算,看M[0] 和 M[2] xor M[4] xor M[6] xor M[8] xor M[10] 是否相等,如果相等,则设置对于M[0]位设为0,不等则设置对应位为1.
通过这样来计算四次,得到M[7] M[3] M[1] M[0],如果传输没错,则这四位均为0.如果某一位发生翻转,比如M[4]发生错误,从0变为1,那么M[0]和M[3]的奇偶性就会计算错误,那么
M[7] M[3] M[1] M[0]
正确 0 0 0 0
M[4]错误 0 1 0 1 ==>对于接受序列中第五个数,也就是M[4]
M[7]错误 1 0 0 0 ==> 对于接受序列中第八个数,也就是M[7]