TextShot项目地址:https://github.com/ianzhao05/textshot
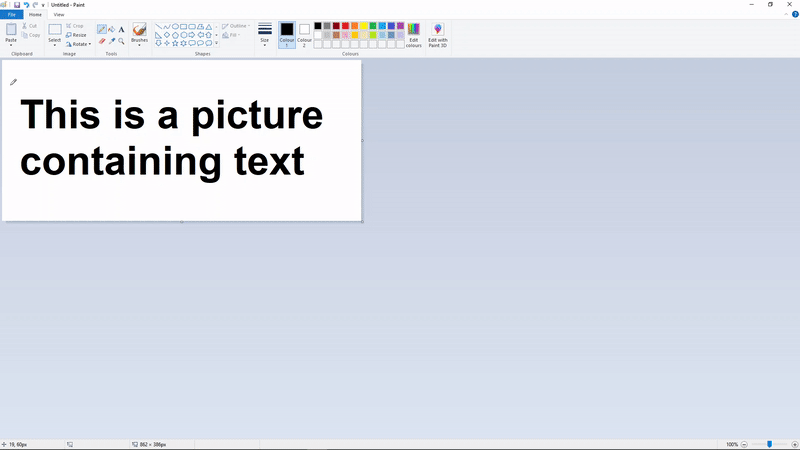
功能:截屏选中需要识别的区域、右键粘贴得到文字识别结果。
项目底层调用的是Tesseract OCR(最新下载地址:https://github.com/UB-Mannheim/tesseract/wiki),所以首先需要安装Tesseract OCR(这部分网上教程很多,可以参考:https://blog.csdn.net/qq_43576028/article/details/102907170,不再赘述)。
安装后确保已经将Tesseract 添加至了环境变量,可以在cmd输入tesseract -v,如果出现一下内容则说明配置成功。
其实到这一步了,如果不嫌麻烦的话,可以直接可以把需要识别的图片截好,然后用tesseract console终端进行识别,就不用再使用TextShot了(手动狗头)。
tesseract命令:
- tesseract 图像路径 结果输出文件名 如:tesseract E:\test.png result 识别的结果会生成一个result.txt文件
但毕竟懒是人类进步的阶梯,言归正传,下面正式开始安装TextShot:
1.git clone/下载项目压缩包解压到本地。
2.选一个或者新建一个python3的conda环境,(我用的python3.8)。
3.cd到项目路径下, 安装依赖。
pip install -r requirements.txt
4.运行时,我又继续cd到了textshot文件夹下,运行: (使用可选的命令行参数指定语言。例如,python textshot.py eng + fra 将使用英语作为主要语言,使用法语作为次要语言。默认值为英语(eng)。同时确保为其他语言安装了适用于 Tesseract 的数据文件。)
E:\textshot-master\textshot>
python textshot.py eng
(里面的文件import时路径有问题,我是把textshot下面5个文件互相import时前面的. 都去掉了,才能运行成功)
如果不cd到textshot下,直接在textshot-master运行也是一样的:
E:\textshot-master>
python ./textshot/textshot.py eng
5.运行结束后等待截图功能出现,截后再把结果粘贴到想要的地方就可以了。