零、主从配置使用场景
1、防止单点故障,做数据备份,从服务器作为主服务器的实时数据备份,遇到故障时可切换到从库
2、实现读写分离,提高可用性,主库执行写操作,从库配置多个执行读操作
3、性能大大提高,根据不同的从库,可以根据项目的模块与业务进行拆分访问
4、防止某些事务锁表时,无法执行读操作
...
一、主从配置原理
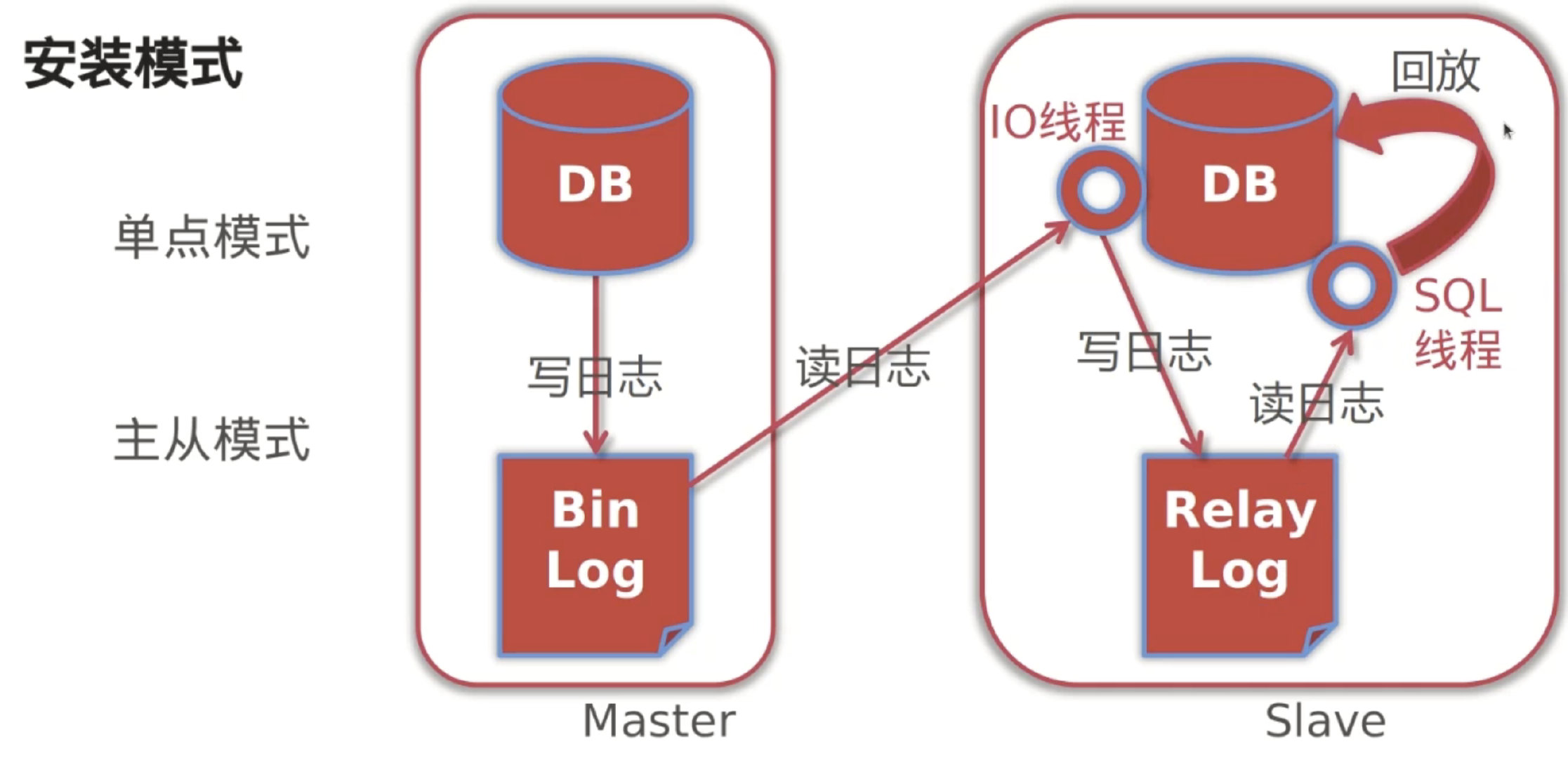
mysql主从配置的流程大体如图:
1)master会将变动记录到二进制日志里面;
2)master有一个I/O线程将二进制日志发送到slave;
3)slave有一个I/O线程把master发送的二进制写入到relay日志里面;
4)slave有一个SQL线程,按照relay日志处理slave的数据;
二、操作步骤
(一)配置文件
具体执行命令如下
#把docker中的文件挂载出来,创建文件夹conf.d,data
mkdir /home/mysql1
mkdir /home/mysql1/conf.d
mkdir /home/mysql1/data/
touch /home/mysql1/my.cnf
mkdir /home/mysql2
mkdir /home/mysql2/conf.d
mkdir /home/mysql2/data/
touch /home/mysql2/my.cnf
主库的my.cnf文件,必须具备的参数
[mysqld]
#同一局域网内注意要唯一
server-id=100
# 开启二进制日志功能,名字可以随便取
log-bin=mysql-bin
#需要同步的二进制数据库名;
binlog-do-db=test
#不同步的二进制数据库名,如果不设置可以将其注释掉;
binlog-ignore-db=information_schema
binlog-ignore-db=mysql
从库my.cnf文件
[mysqld]
# 设置server_id,注意要唯一
server-id=101
# 开启二进制日志功能,若Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
# relay_log配置中继日志
relay_log=mysql-relay-bin
(二)主从配置
1、启动两个mysql
# 主库33306
docker run -di -v /Users/yangxiaobo/Desktop/mysql1/data/:/var/lib/mysql -v /Users/yangxiaobo/Desktop/mysql1/conf.d:/etc/mysql/conf.d -v /Users/yangxiaobo/Desktop/mysql1/my.cnf:/etc/mysql/my.cnf -p 33306:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=123456 dockerhub.datagrand.com/idps/mysql:latest
# 从库33307
docker run -di -v /Users/yangxiaobo/Desktop/mysql2/data/:/var/lib/mysql -v /Users/yangxiaobo/Desktop/mysql2/conf.d:/etc/mysql/conf.d -v /Users/yangxiaobo/Desktop/mysql2/my.cnf:/etc/mysql/my.cnf -p 33307:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=123456 dockerhub.datagrand.com/idps/mysql:latest
2、远程连接入主库和从库
#连接主库
mysql -h 127.0.0.1 -P 33306 -u root -p123456
#在主库创建用户并授权
#创建用户
create user 'repl'@'%' identified by '123';
#授权用户
grant replication slave,replication client on *.* to 'repl'@'%' ;
#刷新权限
flush privileges;
#查看主服务器状态(显示如下图)
show master status;

#连接从库
mysql -h 127.0.0.1 -P 33307 -u root -p123456
#配置详解
/*
change master to
master_host='MySQL主服务器IP地址',
master_user='之前在MySQL主服务器上面创建的用户名',
master_password='之前创建的密码',
master_log_file='MySQL主服务器状态中的二进制文件名',
master_log_pos='MySQL主服务器状态中的position值';
*/
#命令如下
change master to master_host='100.100.20.191',master_port=33306,master_user='repl',master_password='123',master_log_file='mysql-bin.000003',master_log_pos=759;
#启用从库
start slave;
#查看从库状态
show slave status\G;
Slave_IO_Running与Slave_SQL_Running都为Yes表示成功
(三)测试主从同步
在主库上新建表格与数据
#在主库上创建数据库test
create database test;
use test;
create table datagrand (id int,salary int);
insert datagrand (id,salary) values(1,1),(2,2);
#在从库上查询
show database;
use test;
show tables;
select * from datagrand;
#查看主从库之间的连接
show processlist \G
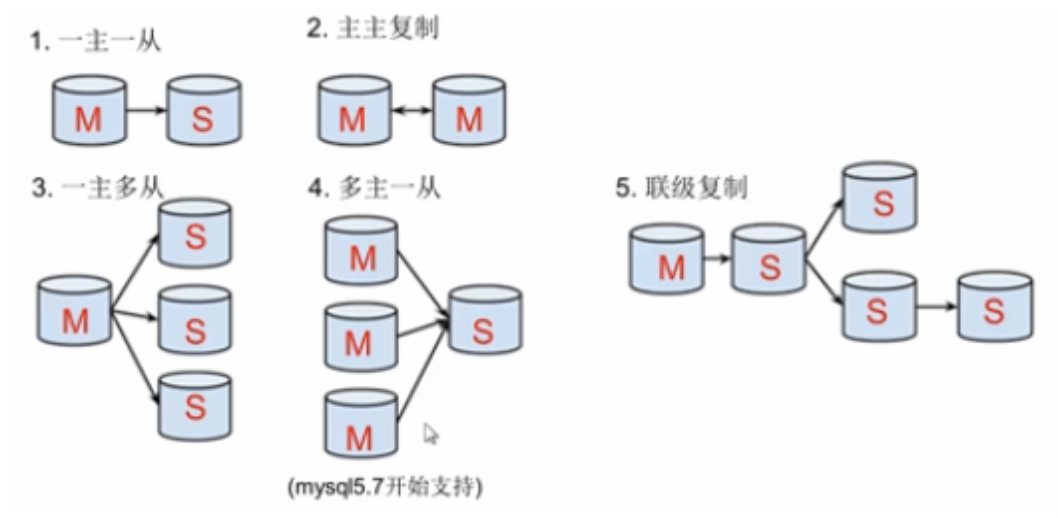
三、主从搭建形式
1、一主一从
较为常见的方式
2、主主复制
互相作为主从,可以就可以互相作为备份库
3、一主多从
当读压力较大的场景时可使用
4、多主一从
当写压力较大的场景时可使用
5、联级复制(mysql5.7开始支持)
四、其他配置参数
(一)主库配置文件
[mysqld]
#同一局域网内注意要唯一
server-id=100
# 开启二进制日志功能,名字可以随便取
log-bin=mysql-bin
#需要同步的二进制数据库名;
binlog-do-db=test
#不同步的二进制数据库名,如果不设置可以将其注释掉;
binlog-ignore-db=information_schema
binlog-ignore-db=mysql
# 表示binlog的写入频率STATEMENT,ROW,MIXED
binlog-format= MIXED
# innodb提交事务时,控制relo log写入磁盘的频率,可设置:0,1,2,控制的是事务
innodb_flush_log_at_trx_commit=1
# 表示binlog的写入频率,默认为0,开启该参数之后,mysql每n次提交事务前会将二进制日志同步到磁盘上,保证在服务器崩溃时不会丢失事件。
sync_binlog=1
# 主库只写
write_only=1
binlog-format详述:
binlog-format=(STATEMENT,ROW,MIXED)
表示binlog以什么方式写入日志
1、STATEMENT
每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如last_insert_id())
2、ROW
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了,几乎没有行复制模式无法处理的场景。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
3、MIXED
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
关于ROW与STATEMENT比较:
比如有下面两个sql语句
insert into t2 (col1,col2,sum_col3) select col1,col2,sum(col3) from t15.1 group by col1,col2;
update t1 set col1 = 0;
(二)从库配置文件
[mysqld]
# 设置server_id,注意要唯一
server-id=101
# 开启二进制日志功能,若Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
# relay_log配置中继日志
relay_log=mysql-relay-bin
# (0:关闭,1:开启)允许链式复制,即从库做为其他机子的主库
log-slave-updates=1
# 从库执行binlog中的sql出错时候,默认会停止复制,改参数可跳过错误继续执行后面的操作
slave_skip_errors=all
# slave_skip_errors=1062,1053 #可直接填写mysql错误码
# 从库只读
read_only=1
五、主从同步延时问题
(一)延时原因
1、主库执行写入操作,从库上会根据主库的binlog,生成一个relay log执行对应的写入操作,在执行这些relay log时,重放数据,对于这些DML和DDL的IO操作来说是随机io。当主库写入量多的情况下,就会产生延迟。
2、数据重放过程中遇到锁等待
(二)缓解方案
1、若某些数据实时性要求极高,可以读取主库数据
2、对于从库若不需要非常高的数据安全,从库配置可以考虑innodb_flush_log_at_trx_commit=0与sync_binlog=0
3、从库开启并行复制
六、sqlachemy读写分离
import time
import random
import pymysql
pymysql.install_as_MySQLdb()
from flask import Flask
from flask_sqlalchemy import SQLAlchemy, SignallingSession, get_state
from sqlalchemy import orm
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:123456@127.0.0.1:33306/test' # 设置数据库连接地址
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False # 是否追踪数据库变化(触发某些钩子函数), 开启后效率会变
app.config['SQLALCHEMY_ECHO'] = True # 开启后, 控制台会打印底层执行的SQL语句
app.config['SQLALCHEMY_BINDS'] = { # get_engine的bind参数为该配置的键
'master': 'mysql://root:123456@127.0.0.1:33306/test',
'slave1': 'mysql://root:123456@127.0.0.1:33307/test'
}
class RoutingSession(SignallingSession):
def get_bind(self, mapper=None, clause=None):
"""每次数据库操作(增删改查及事务操作)都会调用该方法, 来获取对应的数据库引擎(访问的数据库)"""
state = get_state(self.app)
if mapper is not None:
try:
# SA >= 1.3
persist_selectable = mapper.persist_selectable
except AttributeError:
# SA < 1.3
persist_selectable = mapper.mapped_table
# 如果项目中指明了特定数据库,就获取到bind_key指明的数据库,进行数据库绑定
info = getattr(persist_selectable, 'info', {})
bind_key = info.get('bind_key')
if bind_key is not None:
return state.db.get_engine(self.app, bind=bind_key)
# 使用默认的主数据库
# SQLALCHEMY_DATABASE_URI 返回数据库引擎
# return SessionBase.get_bind(self, mapper, clause)
from sqlalchemy.sql.dml import UpdateBase
# 写操作 或者 更新 删除操作 - 访问主库
if self._flushing or isinstance(clause, UpdateBase):
print("写更新删除 访问主库")
# 返回主库的数据库引擎
return state.db.get_engine(self.app, bind="master")
else:
# 读操作--访问从库,目前是直接随机选取,若需要负载需进一步优化
slave_key = random.choice(["slave1"])
print("访问从库:{}".format(slave_key))
# 返回从库的数据库引擎
return state.db.get_engine(self.app, bind=slave_key)
class RoutingSQLAlchemy(SQLAlchemy):
def create_session(self, options):
return orm.sessionmaker(class_=RoutingSession, db=self, **options)
# 初始化组件(建立数据库连接)
db = RoutingSQLAlchemy(app)
# ORM 类->表 类属性->字段 对象->记录
class User(db.Model):
__tablename__ = "t_user" # 设置表名, 默认为类名的小写
id = db.Column(db.Integer, primary_key=True) # 主键
name = db.Column(db.String(20), unique=True, nullable=False) # 设置唯一&非空约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束&建立索引
@app.route('/')
def index():
# 增加数据 进行检验是否读写分离
# 1.创建模型对象
write_data()
time.sleep(1)
print('-' * 30)
# 2.查询数据
read_all_data()
return "index"
def write_data():
user1 = User(name=5, age=5)
db.session.add(user1)
db.session.commit()
def read_all_data():
print(User.query.all())
if __name__ == '__main__':
db.drop_all() # 删除所有继承自db.Model的表
db.create_all() # 创建所有继承自db.Model的表
app.run(debug=True)