gtiee文件夹链接:https://gitee.com/lichouben/assignment-2.git
- 作业①:
- 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
- 输出信息:
- Gitee文件夹链接
代码如下:
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import sqlite3# 创建一个 SQLite 数据库连接 conn = sqlite3.connect('weathers.db') c = conn.cursor() # 创建一个新表,如果表已经存在则忽略 c.execute('''CREATE TABLE IF NOT EXISTS weathers (num TEXT, address TEXT, date TEXT, weather TEXT, temp TEXT)''') url = "http://www.weather.com.cn/weather/101230101.shtml" try: headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") lis = soup.select("ul[class='t clearfix'] li") num = 0 for li in lis: try: num = num+1 address = "福州" date = li.select('h1')[0].text weather = li.select('p[class="wea"]')[0].text temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text print("{:<3} {:<10} {:<8} {:<10} {:<15}".format('序号', '位置', '日期', '天气', '温度')) print("{:<5} {:<5} {:<10} {:<10} {:<10}".format(num, address, date, weather, temp)) c.execute("INSERT INTO weathers VALUES (?, ?, ?, ?, ?)", (num, address, date, weather, temp)) except Exception as err: continue conn.commit() except Exception as err: print(err) finally: conn.close()
输出结果如下:

- 作业②
- 要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
- 候选网站:东方财富网:https://www.eastmoney.com/
- 新浪股票:http://finance.sina.com.cn/stock/
- 技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
- 参考链接:https://zhuanlan.zhihu.com/p/50099084
- 输出信息:
- Gitee文件夹链接
代码如下:
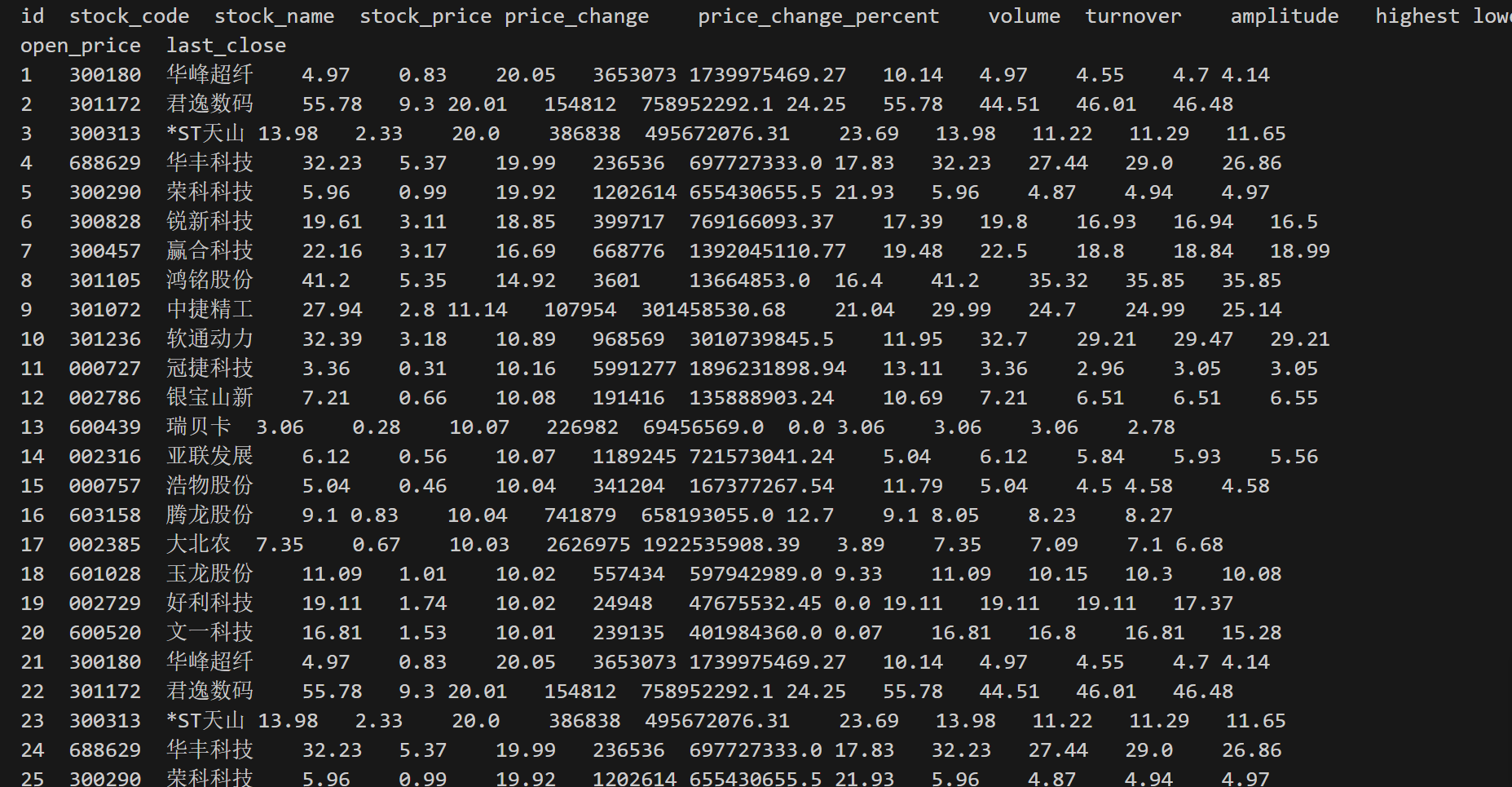
import requests import re import sqlite3 # 用get方法访问服务器并提取页面数据 def getHtml(page,cmd): url = ("http://66.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409097606620255823_1696662149317&pn=1&pz=20&po=1&np="+str(page)+ "&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&"+cmd+ "&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696662149318") r = requests.get(url) pat = "\"diff\":\[(.*?)\]" data = re.compile(pat, re.S).findall(r.text) return data def getOnePageStock(cmd, page): # 提供的JSON数组 data = getHtml(page,cmd) datas = data[0].split("},") #分解每条股票 # 连接到SQLite数据库(如果不存在,则会创建一个新的数据库文件) conn = sqlite3.connect('stock_data.db') cursor = conn.cursor() # 创建股票信息表 cursor.execute('''CREATE TABLE IF NOT EXISTS stock_info ( id INTEGER PRIMARY KEY, stock_code TEXT, stock_name TEXT, stock_price REAL, price_change REAL, price_change_percent REAL, volume INTEGER, turnover REAL, amplitude REAL, highest REAL, lowest REAL, open_price REAL, last_close REAL )''') # 解析JSON数组并将数据存储到数据库中 for item in datas: # 使用字符串操作来提取键值对 stock_info = {} pairs = item.split(',') for pair in pairs: key, value = pair.split(':') key = key.strip('"') value = value.strip('"') stock_info[key] = value # 提取需要的字段 stock_code = stock_info.get('f12', 'N/A') stock_name = stock_info.get('f14', 'N/A') stock_price = float(stock_info.get('f2', 0.0)) price_change_percent = float(stock_info.get('f3', 0.0)) price_change = float(stock_info.get('f4', 0.0)) volume = int(stock_info.get('f5', 0)) turnover = float(stock_info.get('f6', 0.0)) amplitude = float(stock_info.get('f7', 0.0)) highest = float(stock_info.get('f15', 0.0)) lowest = float(stock_info.get('f16', 0.0)) open_price = float(stock_info.get('f17', 0.0)) last_close = float(stock_info.get('f18', 0.0)) # 插入数据到数据库中 cursor.execute( "INSERT INTO stock_info (stock_code, stock_name, stock_price, price_change_percent, price_change, volume, turnover, amplitude, highest, lowest, open_price, last_close) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)", (stock_code, stock_name, stock_price, price_change_percent, price_change, volume, turnover, amplitude, highest, lowest, open_price, last_close)) conn.commit() # 查询股票信息 cursor.execute("SELECT * FROM stock_info") # 获取查询结果 stocks = cursor.fetchall() # 获取查询结果的列名 columns = [desc[0] for desc in cursor.description] # 打印列标签 print("\t".join(columns)) # 打印股票信息 for stock in stocks: # 打印每行数据 print("\t".join(map(str, stock))) # 关闭数据库连接 conn.close() page = 1 getOnePageStock("fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048", page) # cmd = { # "沪深A股": "fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048", # "上证A股": "fid=f3&fs=m:1+t:2,m:1+t:23" # }
输出结果截图如下:
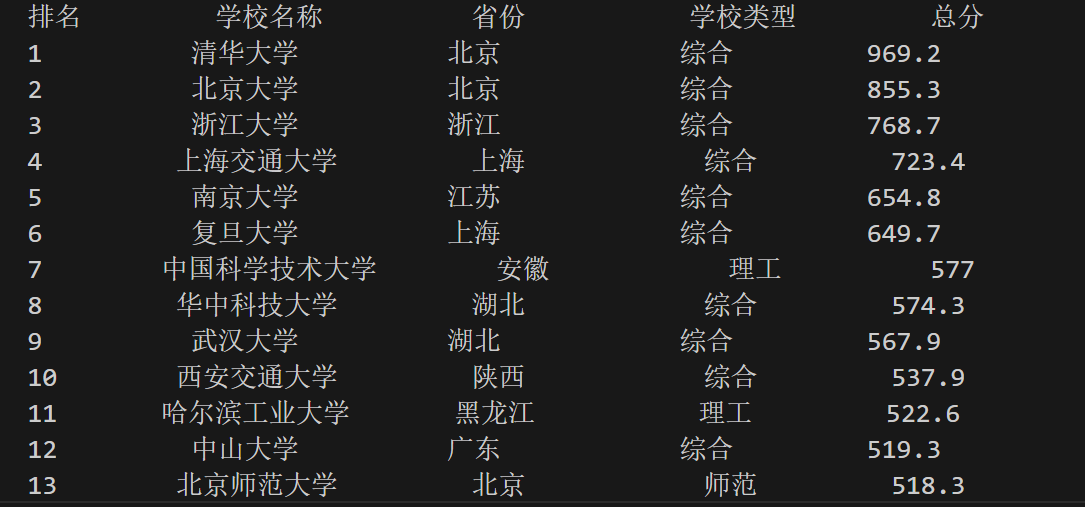
- 作业③:
- 要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程
。 - 技巧:分析该网站的发包情况,分析获取数据的api
- 输出信息:
- 要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程
- Gitee文件夹链接
|
排名 |
学校 |
省市 |
类型 |
总分 |
|
1 |
清华大学 |
北京 |
综合 |
969.2 |
录制jif视频如下:
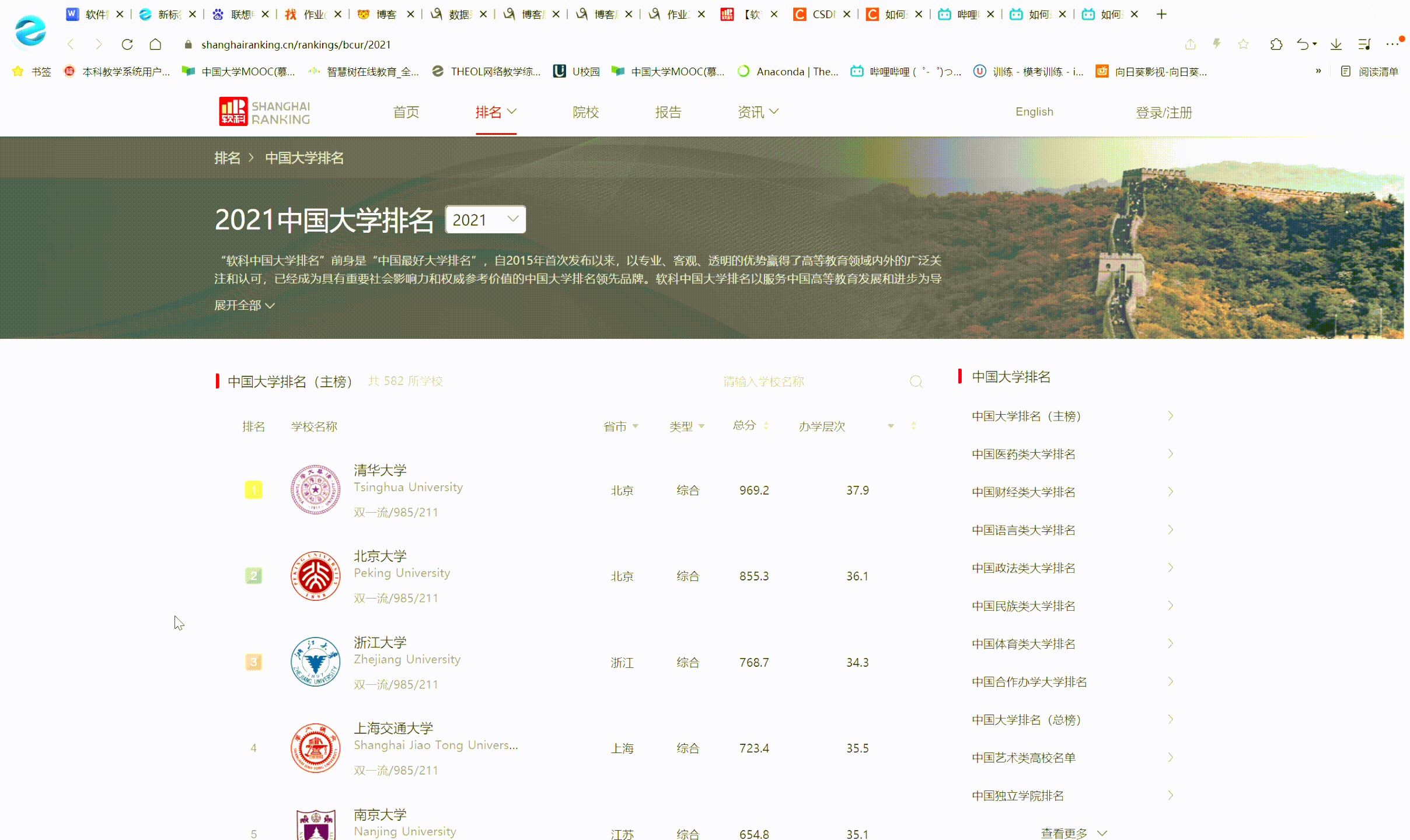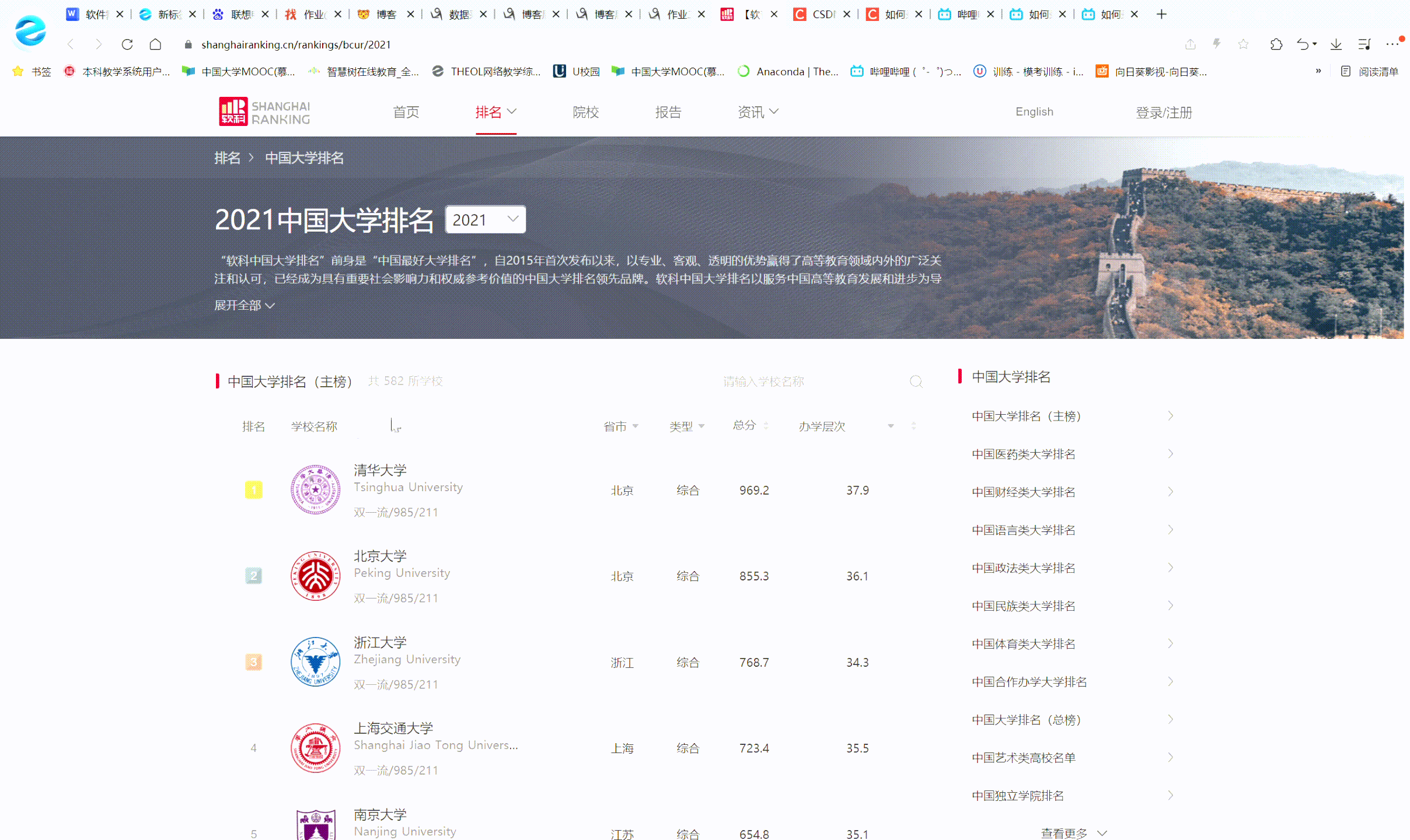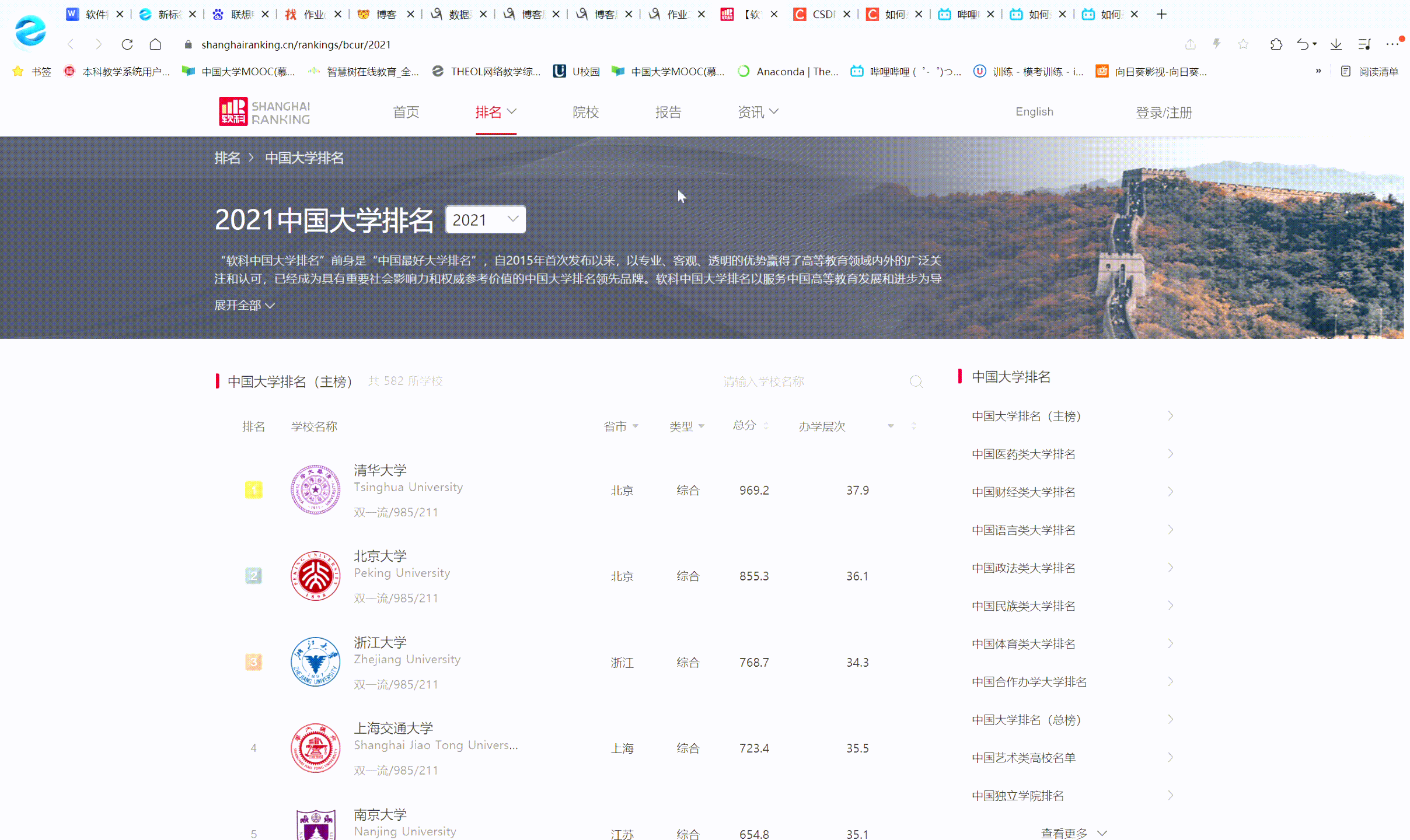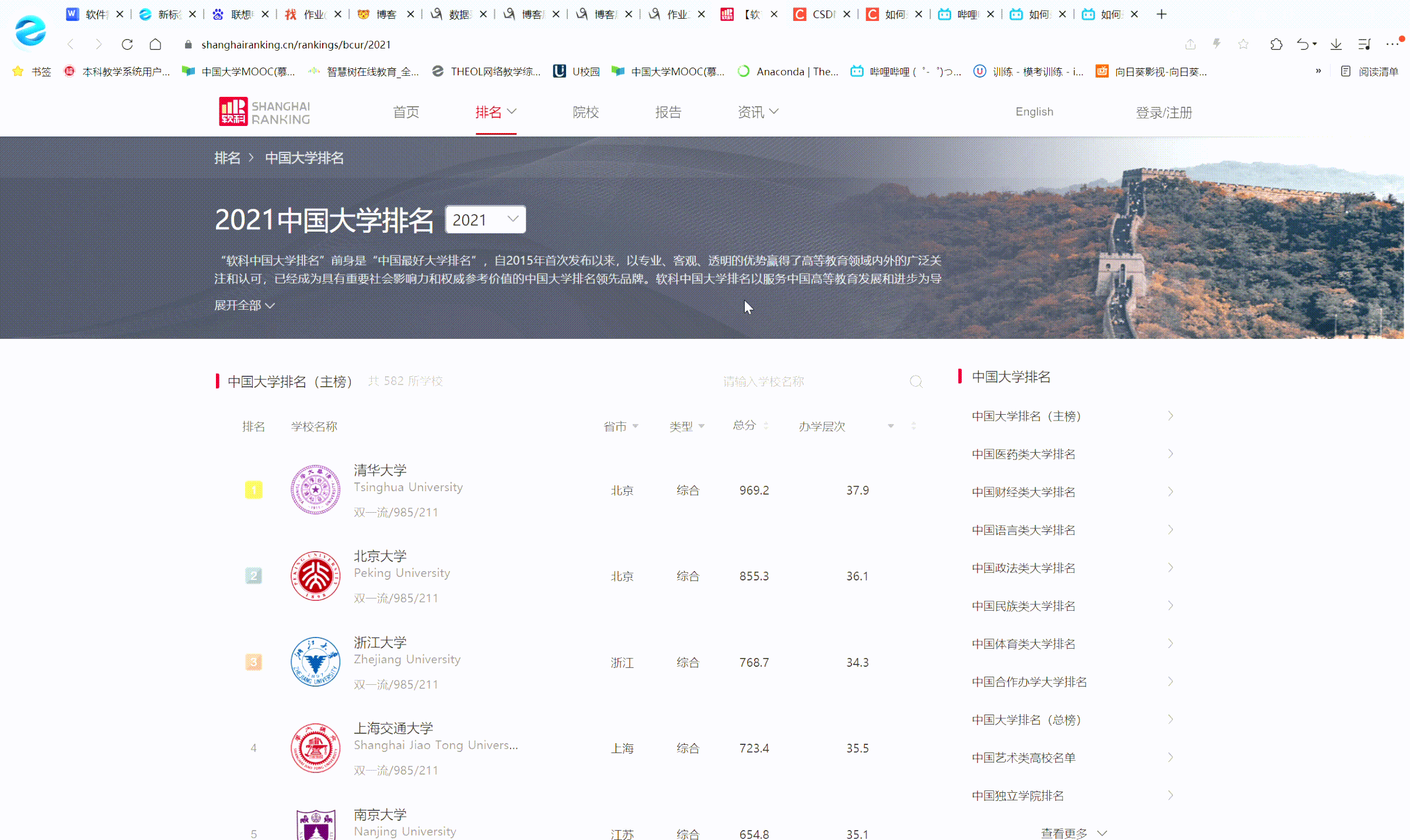
作业代码如下:
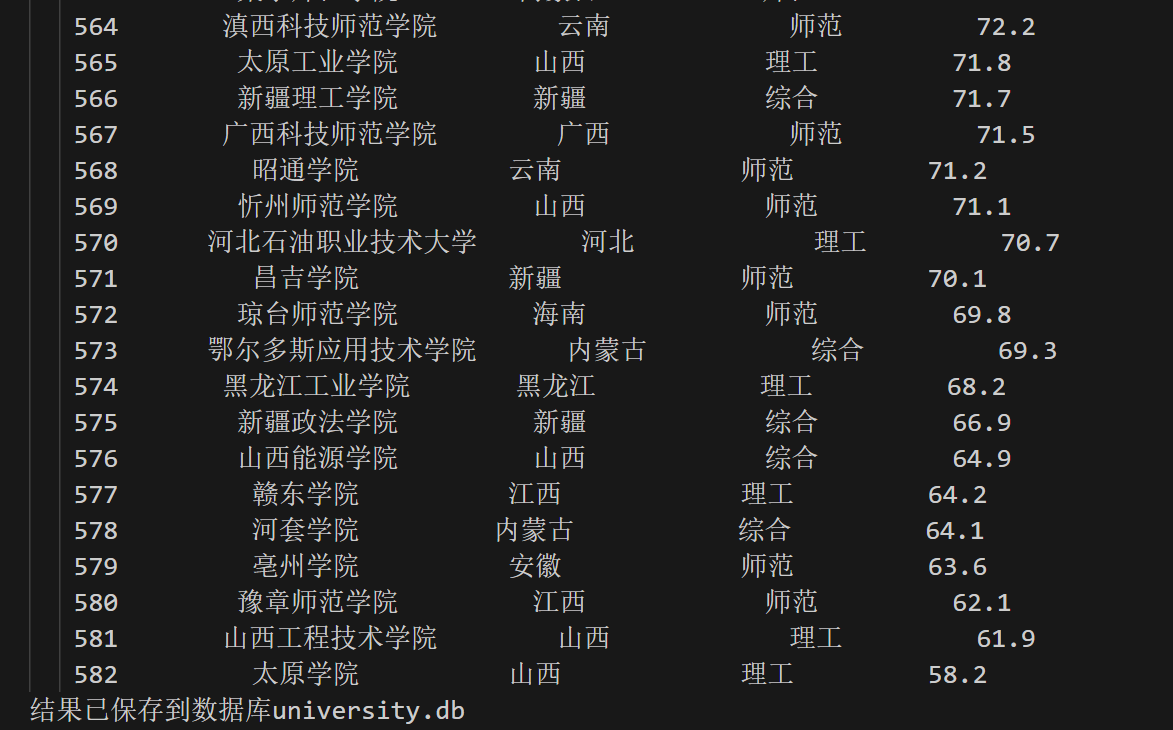
import re import requests import sqlite3 def get_university_ranking(): province_mapping = { 'k': '江苏', 'n': '山东', 'o': '河南', 'p': '河北', 'q': '北京', 'r': '辽宁', 's': '陕西', 't': '四川', 'u': '广东', 'v': '湖北', 'w': '湖南', 'x': '浙江', 'y': '安徽', 'z': '江西', 'A': '黑龙江', 'B': '吉林', 'C': '上海', 'D': '福建', 'E': '山西', 'F': '云南', 'G': '广西', 'I': '贵州', 'J': '甘肃', 'K': '内蒙古', 'L': '重庆', 'M': '天津', 'N': '新疆', 'Y': '海南' } univ_category_mapping = { 'f': '综合', 'e': '理工', 'h': '师范', 'm': '农业', 'T': '林业' } url = 'https://www.shanghairanking.cn/_nuxt/static/1697106492/rankings/bcur/2021/payload.js' header = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre" } resp = requests.get(url, headers=header) resp.raise_for_status() resp.encoding = resp.apparent_encoding obj = re.compile( r'univNameCn:"(?P<univNameCn>.*?)",.*?' r'univCategory:(?P<univCategory>.*?),.*?' r'province:(?P<province>.*?),' r'score:(?P<score>.*?),' , re.S) results = [] for idx, it in enumerate(obj.finditer(resp.text), start=1): univNameCn = it.group('univNameCn') univCategory = it.group('univCategory') province = it.group('province') score = it.group('score') mapped_province = province_mapping.get(province, province) mapped_category = univ_category_mapping.get(univCategory, univCategory) results.append((idx, univNameCn, mapped_province, mapped_category, score)) return results def save_to_db(results): conn = sqlite3.connect('university.db') c = conn.cursor() c.execute('''CREATE TABLE IF NOT EXISTS university (rank INTEGER, school_name TEXT, province TEXT, category TEXT, score REAL)''') c.executemany('INSERT INTO university VALUES (?, ?, ?, ?, ?)', results) conn.commit() conn.close() print("结果已保存到数据库university.db") if __name__ == '__main__': results = get_university_ranking() tplt = "{0:^10}\t{1:^10}\t{2:^12}\t{3:^12}\t{4:^9}" print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分")) for u in results: rank = str(u[0]) school_name = u[1] province = u[2] category = u[3] score = u[4] print(tplt.format(u[0], u[1], u[2], u[3], u[4])) save_to_db(results)
输出结果截图如下: