Introduction
Today, we talk about some cores concepts within kafka. Apache kafka is a distributed publish-subscribe messaging system. It is originally developed at Linkdln Corporation and later on become a part of Apacche project, kafka is a fast, scalable, distributed in nature by its design, partitioned and replicated commit log service.producers publish messages to kafka topics, and consumers subsribe to these topics and consume the messages, a server in a kafka is called broker, for each topic, the kafka cluster maintains a partition for scaling, parallelism and fault-tolerance. each partiiton is an ordered , immutable sequence of messages that is continually appended to a commit log. The messages in the partitions are each assigned a sequential id number called the offset.
Otherwise, how should I write this artical? I think it is better to introduce the architectue of kafka before the core concepts, Now, let talk about kafka's architecture.
Architecture
Firstly, I want to introduce the basic concepts of kafka, Its architecture consists of the following components:
- A stream of messages of a particular type is defined as a topic, a message is defined as a payload of bytes and a topic is a category or feel name to which messages are published.
- A producers can be anyone who can publish messages to a topic.
- The published messages are then stored at a set of servers called Brokers or kafka cluster.
- A consumer can subscribe to one or more Topics and consume the published Messages by pulling data from tthe brokers.

The overall architecture of kafka is shown in above figure. Since kafka is a distributed in a nature, a kafka broker typically consists of multiple brokers, To balance load, a topic is divided into multiple partitions and each broker and each broker stores one or more of those partitions. Multiple producers and consumers can publish and retrieve messages at the same time.
Now, let me talk about these three concepts: topic, producer, consumer.
topic
Officially, A kafka topic is a fundamental concept in the Apache Kafka streaming platform , serving as a logical channel or category for organizing and categorizing data streams. Topics act as message queues, where data is published by producers and consumed by consumers in a distributed and real-time manner. Each kafka topic represents a specific data feed or stream, allowing related information to be grouped together. Topics are highly scalable and durable, often partitioned across multiple servers to enable parallel processing and fault tolerance, they faciliate decoupling data producers from consumers in event-driven architectures, making it possible to build efficient, resilient and scalable data pipelines and applications that can handle vast volumes of data with low latency.
A kafka topic partition is a critical mechanism in the apache kafka messaging system that allows for the parallel and distributed processing of data streams. It involves breaking down a kafka topic into smaller, independently manageable units or topic partitions, Each partition is essentially a linear, ordered log of messages, and it serves as the unit of parallelism, allowing multiple consumers to read and process messages simultaneously, Partitions enable kafka to achieve high throughput and scalability , as they can distributed across multiple kafka brokers and processed concurrently by consumers ,Additionally, partitioning ensures fault tolerance, as each partition has replicas on other servers , ensuring data durability and availability even during hardware failures.
There is a famous definition of topic, kafka topics are a permanent log of events or sequences, every topic can serve information to nurmerous consumers, which is why producers are in some cases referred to as a publisher, and consumers are called subscribers. Partitions serve to repeat information across brokers, every kafka topic is isolated into segments and each partition can be set on a different node.
so , what the role of kafka topics play? the role of kafka topics in data streaming is fundamental to functionality and efficiency of kafka, topic serve as the primary organizational structure for kafka stream, their role can be summarized in several key aspects-
- Data organization-kafka topics categorize and organize data into logical channels of categories. Each topic represents a specific data stream or feed , allowing data to be organized based on its source, purpose, or content.
- Decoupling producers and consumers-kafka topics enable data producers and consumers to decouple, producers publish data to topics without knowing who or what will consume it , promoting loose coupling and flexibility in system design.
- Parallel Processing, Topics are divided into partitions , which can be processed independently and in parallel, This parallelism facilitates the high-throughput procesing of data, making kafka suitable for real-time and high-volume data streams.
- Data retention-kafka topics can retain data for a configurable period, ensuring consumers can access historical data, replay events , or perform analytics on past data.
- Scalability and fault tolerance - kafka topics are partitions across multiple brokers, distributing the data load and ensuring fault tolerance, this architecture allows kafka to scale horizontally to handlle massive data volumes.
- Messages Ordering- within a partition , kafka maintains strict message order, ensuring that data is processing sequentially, which is critical for applications requiring ordered event processing.
I believe reader has know what is definition of topic, what the role topics play in kafka? how can kafka have a
high-performance, high-scalability, fault-tolerance through topics work. now let talk about producers within kafka.
producer
In a nutshell, producers create new messages. In other publish/subscirbe systems, these may be called publisher or writers, A message may produced to a specific topic, by default, the producer will balance messages over all partitions of a topic evenly, In some cases, the producer will direct messages to specific partitions, this is typically done using the message key and a partitioner that will generate a hash of key and map it to a specific partition, this ensures thats all messages produced with a given key will get written to the same partition.
There are many reasons an application might need to write messages to kafka: recording user activities for auditing or analysis, recording metrics, storing log messages, recording information from smart appliances, communicating asynchronously with other application , buffering indormation before writing to a database, and much more.Those diverse use cases also imply diverse requirements: is every message critial , or can we tolerate loss of message? Are we ok with accidentially duplicating messages? Are there any strict latency or throughput requirements we need to support?
There is some particular sitution, for example, In the credit card transaction processing example, we can see it is critical to never lose a single message or duplicate any messages, Latency should be low, but latencies up to 500ms can be tolerated, and throughput should be very high --we expect to process up a million messages a second. A different use case might be to store click information from a website, In that case, some messages loss or a few duplicates can be tolerated; latency can be high as long as there is no impact on user experience, In other words, we don't mind if it takes a few seconds for the message to arrive at kafka, as long as the next page loads immediately after the user clicks on a link, Throughtput will depend on the level of activity we anticipate on our website.
So we must know , the different requirements will influence the way we use the producer API to write messages to kafka and the configuration you are,while the producer API is very simple, there is a bit more that go on under the hood of the producer when we send data, the below figure shows the main steps involved in sending data to kafka.
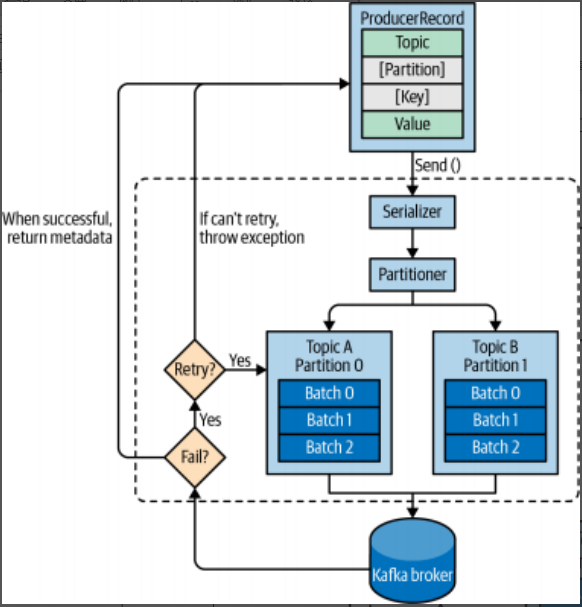
we start producing messages to kafka by creating a ProducerRecord, which must include the topic we want to send the record to and a value. Optionally, we can also specify a key, a partition , a timestamp, and/or a collection of headers. Once we send the ProducerRecord, the first thing the producer will do is serialize the key and value objects to byte arrays so they can be sent over the network.
Next, if we didn't explicitly specify a partition, the data is sent to a partiitoner, the partitioner will choose a partition for us, usually based on the producerRecord key, Once a partiiton is selected , the producer knows which topic and partiiton the record will go on, It then adds the record to a batch of records that will also be sent to the same topic and partiiton, A separate thread is responsible for sending those batches of records to the appropriate kafka brokers.
When the broker receives the messages , it sends back a response, If the messages were sucessfully written to kafka , it will return a RecoredMetedata object with the topic, partiiton, and offset of the record within the partion . If the broker failed to write the message , it will return an error, When the producer receives an error, it may retry sending the message a few more times before giving up and returning an error.
consumer
Applications that need to read data from kafka use a KafkaConsumer to subscribe to kafka topics and receive messages from these topics, reading data from kafka is a bit different than reading data from other messaging systems, and there are a few unique concepts and ideas involved, I will start by explaining some of the important concepts,
To understand how to read data from kafka , you first need to understand its consumers and consumer groups. The following sections cover those concepts.
Supose you have an application that to read messages from a kafka topic, run some validations against them , and write the results to another data store , In this case , your application will create a consumer object, subscribe to the approprite topic, and start receiving messages, validating them, and writing the results, this may work for a while, but what if the rate at which producers write messages to the topic exceeds the rate at which your application can validate them? if you are limited to single consumer reading and processing the data, your application may fall further and further behind , unable to keep up with the rate of incoming messages, Obviously there is a need to scale consumption from topics . just like multiple producers can write to the same topic, we need to allow multiple consumers to read from same topic, splitting the data from them.
Typically, Kafka consumer are part of a consumer group, when multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group will receive messages from a different subset of the partiitons in a topic. for example, there is a topic with four partiitons, now suppose we created a consumer C1 belong to a consumer group called G1, if we use C1 subscribe to topic, C1 will get all messages from all four partitions, causing there is only one consumer in G1, if we add a new consumer C2 , to group G1, each consumer will get messages from two partitions . Perhaps messages from partion 0 and partition 2 to C1, and messages from partiitons 1 and 3 go to consumer C2. Naturally, if G1 has four consumers, then each will read messages from a single partition. because the number of consumers in G1 is equal to number of partitions.If we have more consumers to a single group with a single topic than we have partitions, some of consumers will be idle and get no messages at all.
It is common for kafka consumers to do high-latency operations such as write to a database or a time-consuming computation on the data, In these cases, a single consumer can't possibly keep up with the rate data flows into a topic, and adding more consumer that share the load by having each consumer own just a subset of the partitions and messages is our main method of scaling, This is a good reason to create topics with a large number of partiitons, we need to keep in mind that there is no point in adding more consumers than you have partitions in a topic, becase of some of the consumers will be idle.
So totally, you can add consumers to an existing consumer group to scale the reading and processing of messages from the topics, so each additional consumer in a group will only get a subset of the messages.
As we saw in the previous section, consumers in a consumer group share ownership of the partitions in the topics they subscribe to, when we add a new consumer to the same group, it starts consuming messages from partitions previously consumed by another consumer, The same thing happens when a consumer shuts down or crashes, it leaves the group, and the partition it used to consume will be consumed by one of the remaining consumers, this is called consumer rebalances ,Moving partition ownership from one consumer to another is called a rebalance, rebalances are important because they provide the consumer group with high-availability and scalability, allowing us to easily and safely add and remove consumers, but in the normal course of events they can be fairly undesirable. because one consumer failed ,the other consumers in same group must have some effects which are inappropriately.
So there is another feature called static group membership, all this is true unless you configure a consumer with a unique group.instance.id, which makes the consumer a static member of the group, When a consumer first joins a consumer group as a static member of the group, it is assigned a set of partitions according to the partition assignment strategy the group is using, as normal, however when this consumer shut down, it dose not automatically leave the group, it remains a member of the group until its session times out, when the consumer rejoins the group again, it is recognized with its static identity and is reassigned the same partitions it previously held without triggering a rebalance , The group coordinator that caches the assignment for each member of the group dose not need to trigger a rebalance but can just send the cache assignment to the rejoining static member. Static group membership is useful when your application maintains local state or cache that is populated by the partitions that are assigned to each consumer, when re-creating this cache is time-consuming, you don't want this process to happen every time a consumer restarts, on the flip side, it is important that the partitions owned by each consumer will not get reassigned when a consumer is restarts, for a certain duration, no consumer will consume messages from these partitions, it is important to note that static members of consumer groups do not leave the group proactively when they shut down, and detecting when they are "really gone" depends on session.timeout.ms configuration. you will want to set it high enough to avoid triggering rebalances on a simple application restart, but set it low enough to allow automatic ressignment of their partiitons to avoid large gaps in processing these partition.
Conclusion
It is time to summarize this acticle, totally, it show the basic concepts in kafka, included, the basic architecture, and how the producer and consumer to be run , at the same time, I hope it will good for you. next time I will show more details about this concepts, how to configure and how to code. see you!