redis可以通过SLAVEOF命令去复制(同步)另一台服务器,例如:
当前有两台redis服务器其信息为:
| hostname | ip | port |
|---|---|---|
| redis_1 | 127.0.0.1 | 6379 |
| redis_2 | 127.0.0.1 | 12345 |
如果redis_2想要同步redis_1的内容,可以在redis_2上执行SLAVEOF 127.0.0.1 6379,进而达到这个效果。
Redis SLAVEOF命令的功能主要通过如下几个命令:
- 2.8版本之前主要通过SYNC命令和BGSAVE命令
- 2.8版本及之后主要通过PSYNC命令和BGSAVE命令
接下来我们主要介绍SLAVEOF功能的具体实现。
2.8版本之前的SLAVEOF
Redis的复制功能主要通过两个操作完成,分别为同步和命令传播:
- 同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。(保证初始状态一致)
- 命令传播操作则用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态(最终状态一致)
因此,在SLAVEOF被执行后,从服务器首先对主服务器进行同步,同步完毕后,后续主服务器上执行的命令,会通过命令传播传输到从服务器上。
同步主要通过SYNC命令完成,SYNC命令的执行步骤如下:
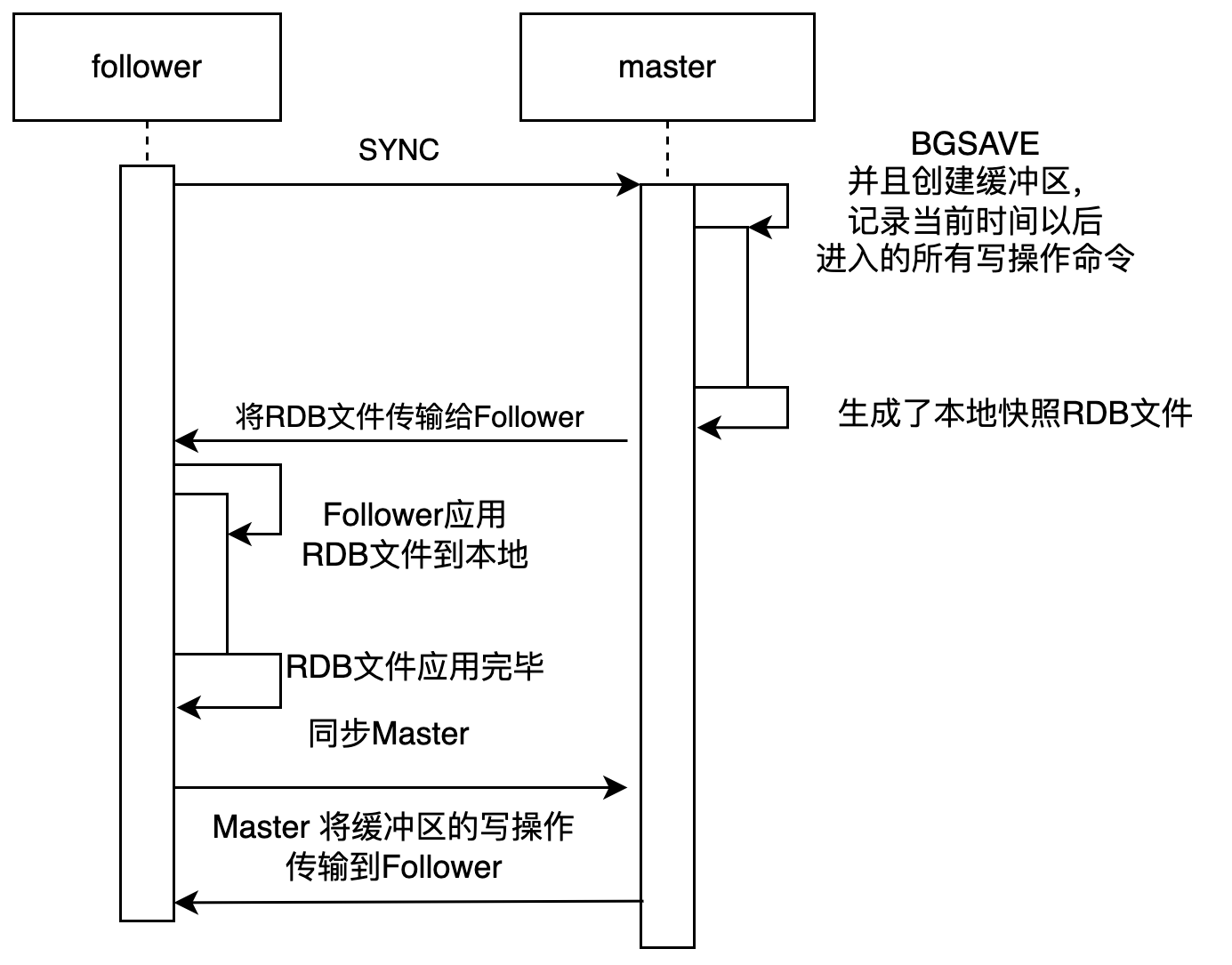
- 从服务器向主服务器发送SYNC命令
- 主服务器收到命令后,开始执行BGSAVE命令,后台生成一个RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令
- 当主服务器BGSAVE命令执行完毕后,主服务器会将生成的RDB文件发送给从服务器,从服务器接收并载入这个文件,将数据库更新为主服务器生成RDB文件时的状态。
- 主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态。
当同步过程完成之后,进入命令传输阶段,一旦主服务器接收到写命令,并且执行完成之后,主服务器会将该命令同步至从服务器,让从服务器也执行该命令。(感觉直接复用AOF日志的逻辑就好)
但是该方法有两个缺陷:
- BGSAVE命令是十分低效的,他会将本地所有的数据生成为一个RDB文件,其次由于RDB文件比较大,网络耗时也会比较影响效率
- 命令传输阶段如果从服务器停止,主服务器无法将命令同步到从服务器,也需要兼容。
2.8以及以后的SLAVEOF
2.8版本以后,Redis进行了如下改动:
- 将负责存储写命令的缓冲区引入到了命令传输阶段,缓冲区大小为1MB
- 为各个Redis服务器,无论主从,添加了唯一的Run ID,用于唯一标识Redis服务器
- 各个Redis会记录本地同步的offset,master记录已经同步过的数据的offset,Follower记录已经成功同步master的offset。
引入了这三点改动,就解决了上面的问题:
由于2.8以前所有的同步操作都需要使用BGSAVE,导致同步的效率十分低下,为了缓解这个问题,在命令传输阶段,master引入了一个大小为1MB的缓冲区,用于记录已经执行的写命令,并且Master和Follower都记录了自己的唯一ID,并且会记录同步的offset。
- 唯一ID保证了Follower和Master中Offset等信息的有效性,如果无法确认各个Redis服务器的身份,存储的offset就没有意义。
- Offset负责记录同步进程。
- 如果Follower断线,又重启后,其最后的Offset+1对应的数据还在缓冲区中,则Master只将缓冲区中的写命令传输给Follower,避免了BGSAVE。
- 如果Follower断线,又重启后,其最后的Offset+1对应的数据不在缓冲区中,则只能通过BGSAVE的方式+命令传输的方式进行同步
- 缓冲区的大小为1MB保证了同步的效率。
如果出现了数据丢失现象:
首先Master的Offset必定大于Follower的Offset,因为Master传输出命令就把Offset增加了,无论Follower是否执行,但是Follower在请求Master的命令同步消息时,会携带自身的Offset,因此Master会将自己的Offset与Follower的Offset中间差距的数据传输给Follower,保证了数据不会丢失。